Towards Brain MRI Foundation Models for the Clinic: Findings from the FOMO25 Challenge
1. Motivation
Task-specific supervised models dominate neuroimaging ML, but they degrade on real clinical data and on scans from new sites, vendors, or populations. The root issue is a structural mismatch: clinical workflows generate huge volumes of MRI, yet only a tiny, mostly research-grade fraction is ever labeled. Self-supervised learning (SSL) sidesteps this by pretraining an encoder on a large unlabeled corpus and adapting it with minimal supervision — but brain-MRI progress has been limited by small pretraining sets and evaluation on clean benchmarks where supervised models already excel. The MICCAI FOMO25 challenge closes this gap by pairing a large pretraining corpus with evaluation on clinical-workflow data under few-shot, out-of-domain conditions.
2. Challenge design
Data
- Pretraining (FOMO60K): A large-scale unlabeled dataset of 60,529 structural brain MRI scans from 13,900 sessions across 11,187 subjects, aggregated from 16 public sources and released on Hugging Face. It is deliberately heterogeneous in demographics, scanner vendors, field strengths, protocols, and sequence types.
- Finetuning: Intentionally small datasets to test few-shot learning. Classification and segmentation data came from hospitals in India ; brain-age data came from a Boston cohort.
- Validation and test: Acquired from multiple hospitals in Denmark — different institutions and geographic regions from the finetuning data, making evaluation genuinely out-of-domain. Validation/test data remained private.
Three downstream tasks
| Task | Type | Finetuning cases | Test cases | Metric(s) |
|---|---|---|---|---|
| Task 1 — Infarct | Classification | 21 (13 positive / 8 negative) | 320 | AUROC |
| Task 2 — Meningioma | Segmentation | 23 | 107 | Dice, NSD* |
| Task 3 — Brain age | Regression | 200 | 800 | Mean AE, Pearson Corr. |
* Normalized Surface Distance
Two tracks
- Method Track — pretraining restricted to FOMO60K, isolating methodological contributions by controlling for data.
- Open Track — any pretraining data allowed, including private datasets, benchmarking what is achievable with arbitrary or proprietary resources.
Both tracks shared identical finetuning data and the same held-out out-of-domain evaluation. Methodological constraints were otherwise kept minimal to encourage diverse architectures and pretraining paradigms.
Participation
The challenge drew 137 registrations. Ultimately 19 unique foundation models from 16 teams were evaluated through a standardized, containerized pipeline.
3. Headline findings
The paper distills its results into three main messages.
Finding 1 — Self-supervised pretraining boosts generalization
Across all three tasks, the best pretraining-based model from the Method Track outperformed both a from-scratch out-of-domain supervised baseline and an in-domain supervised baseline. In other words, well-pretrained foundation models can bridge a cross-continent domain gap in a few-shot setting and beat specialist models trained directly on in-domain data.
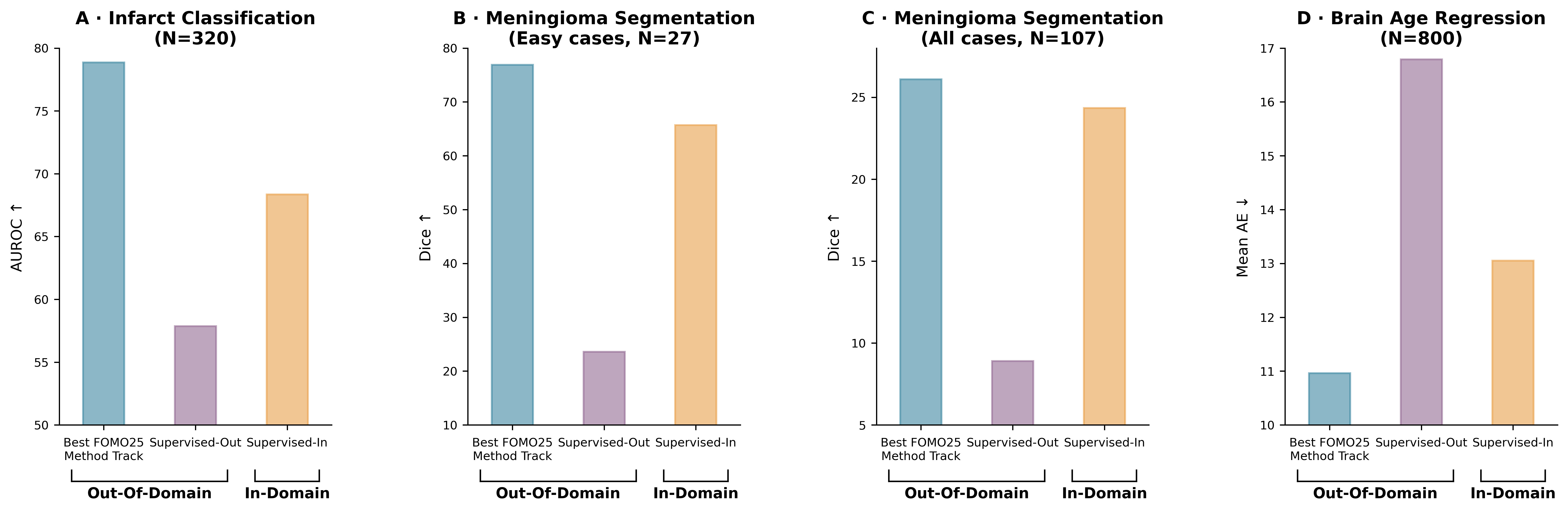
Concretely, 16 of 19 models ranked higher than the Supervised-OOD baseline trained on the same data. Two models, FOMO2JOMO and Dolphin_creators, even beat the stronger Supervised-ID baseline, with FOMO2JOMO’s improvement being statistically significant. The per-task gains for the best Method-Track models were substantial:
- Classification (ashash): +20.99 AUROC points over Supervised-OOD, +10.51 over Supervised-ID.
- Segmentation (Dolphin_creators): +17.20 Dice points over Supervised-OOD, +1.75 over Supervised-ID.
- Regression (FOMO2JOMO): error reduced by 5.83 Mean AE points vs. Supervised-OOD, 2.09 vs. Supervised-ID.
Finding 2 — No single SSL objective wins everywhere
Pretext tasks were grouped into three categories: local objectives (voxel-level supervision, e.g. Masked Autoencoders / MAE), global objectives (sequence- or subject-level, e.g. contrastive learning), and hybrid objectives (combining the two, e.g. MAE + contrastive, or DINOv2).
A consistent pattern emerged: local objectives (MAE) tended to favor segmentation, while hybrid objectives tended to favor classification and regression. Every model also showed large rank swings across tasks — no single foundation model performed well on all three.
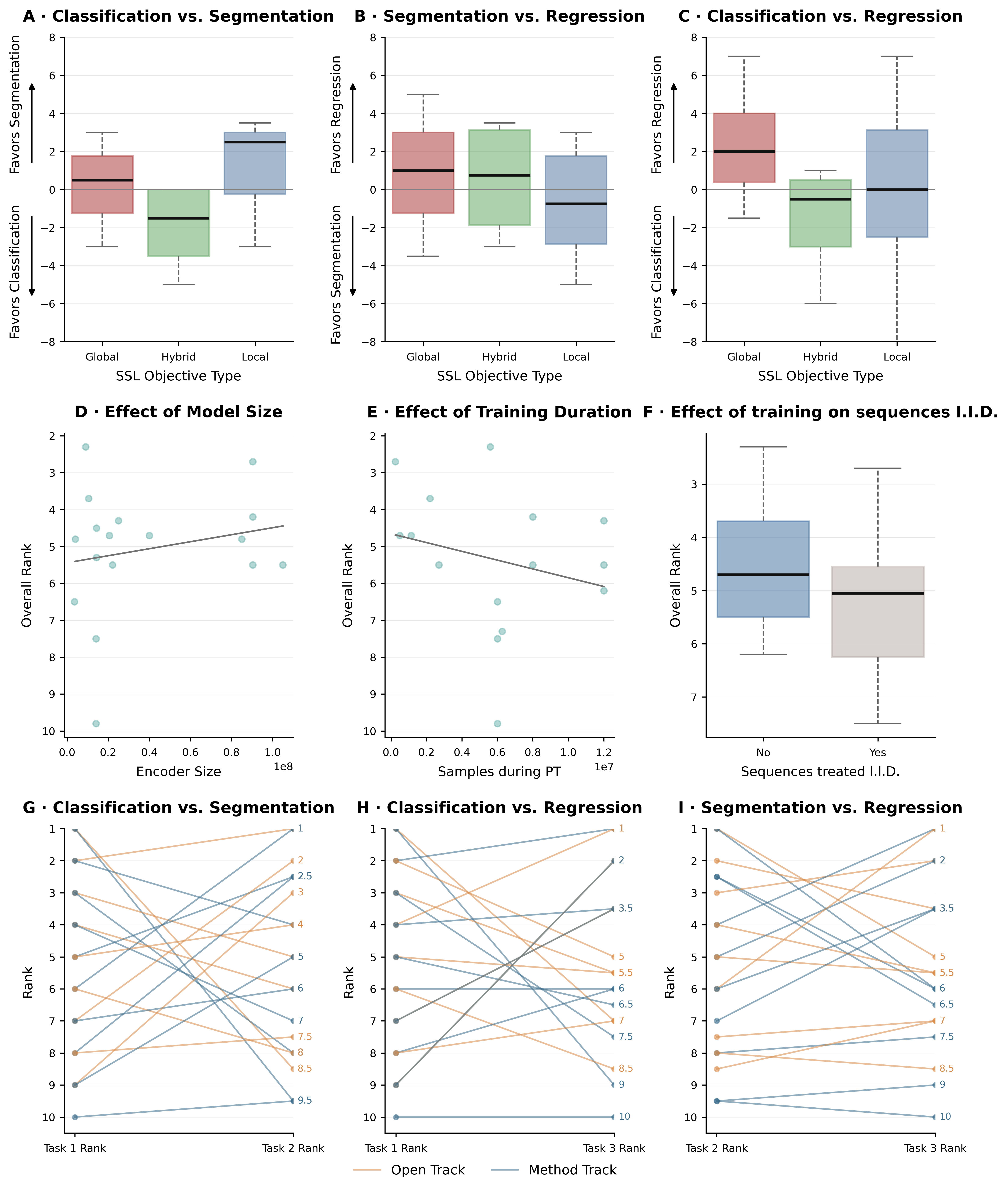
Finding 3 — Small models were competitive; scaling gave unreliable gains
Contrary to scaling trends in general computer vision, the associations between model size, pretraining duration, and downstream performance were weak. Larger encoders showed at most a modest advantage, and training for longer did not translate into meaningfully better results — methods appeared to saturate early. Strong performance was achieved by small pretrained models.
4. The leaderboard
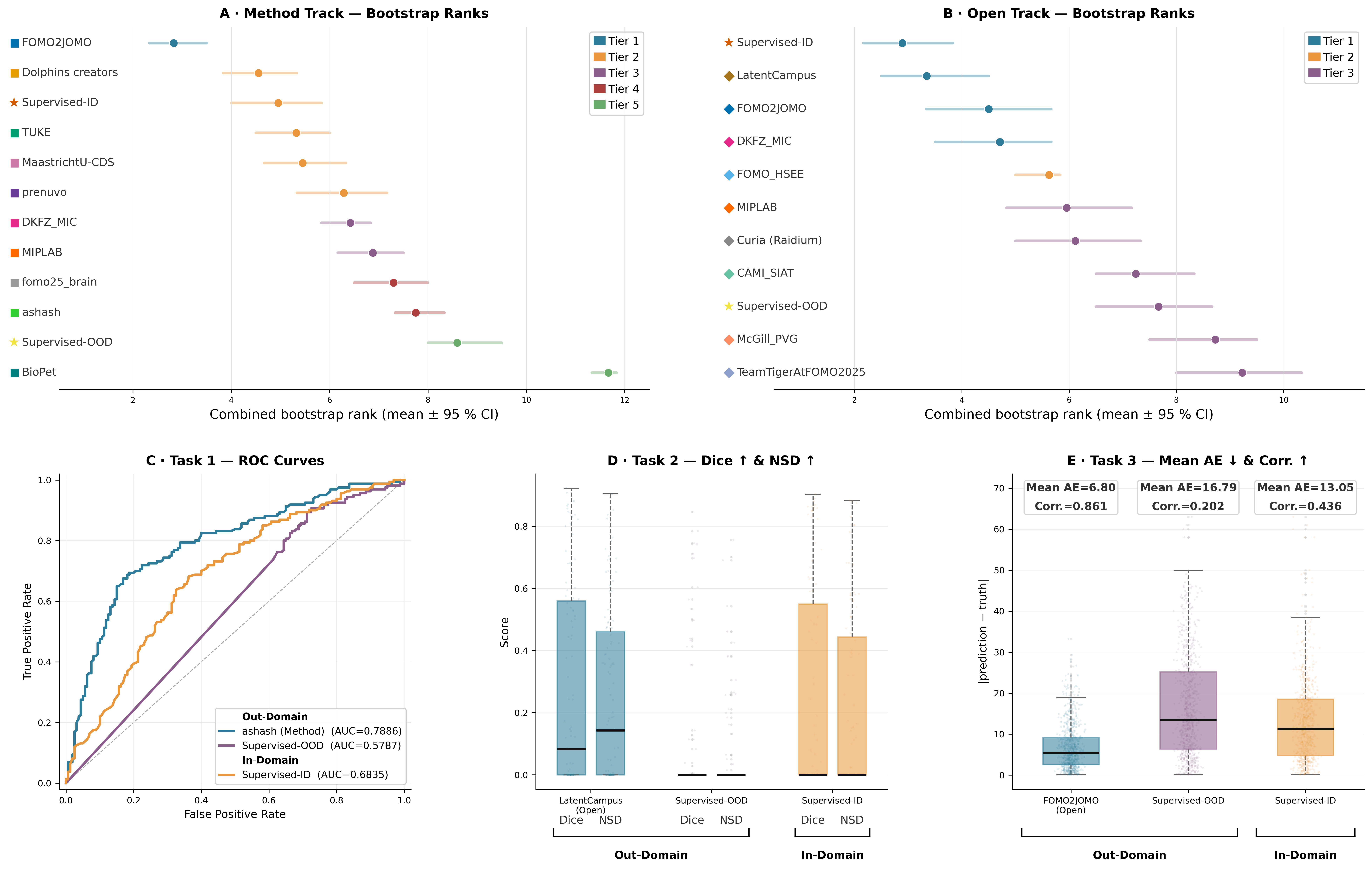
Rankings were computed by averaging metric-specific ranks within each task, then across tasks. Stability was assessed with 10,000 bootstrap resamples and significance with pairwise permutation testing, so results are best read as performance tiers rather than exact ordinal positions.
Method Track (top of leaderboard):
| Place | Team | Overall rank | Task 1 AUROC | Task 2 Dice | Task 3 Mean AE |
|---|---|---|---|---|---|
| 1 | FOMO2JOMO | 2.3 | 0.782 | 0.095 | 10.96 |
| 2 | Dolphins_creators | 4.3 | 0.684 | 0.261 | 12.67 |
| 3 | MaastrichtU-CDS | 4.7 | 0.688 | 0.181 | 16.17 |
| 4 | TUKE | 4.8 | 0.750 | 0.046 | 11.96 |
| 5 | MIPLAB | 5.3 | 0.473 | 0.065 | 11.48 |
Open Track (top of leaderboard):
| Place | Team | Overall rank | Task 1 AUROC | Task 2 Dice | Task 3 Mean AE |
|---|---|---|---|---|---|
| 1 | LatentCampus | 2.7 | 0.659 | 0.275 | 16.50 |
| 2 | FOMO2JOMO | 3.7 | 0.625 | 0.039 | 6.80 |
| 3 | DKFZ_MIC | 4.2 | 0.569 | 0.252 | 13.67 |
In the Method Track, FOMO2JOMO stood alone in Tier 1; five methods (including the in-domain supervised baseline) followed in Tier 2. In the Open Track, no submission significantly outperformed the in-domain supervised baseline overall — the baseline occupied Tier 1 alone, with LatentCampus in Tier 2. The bootstrap rank distributions and per-task ROC/Dice/error breakdowns are shown below.
5. What design choices mattered
Open vs. Method Track
The Open Track generally used larger pretraining datasets, larger models, and more GPUs than the Method Track — one team (Curia/Raidium) used a corpus estimated at over 1M scans covering both CT and MRI. Notably, almost all Open-Track methods used a CNN backbone, versus only about half in the Method Track.
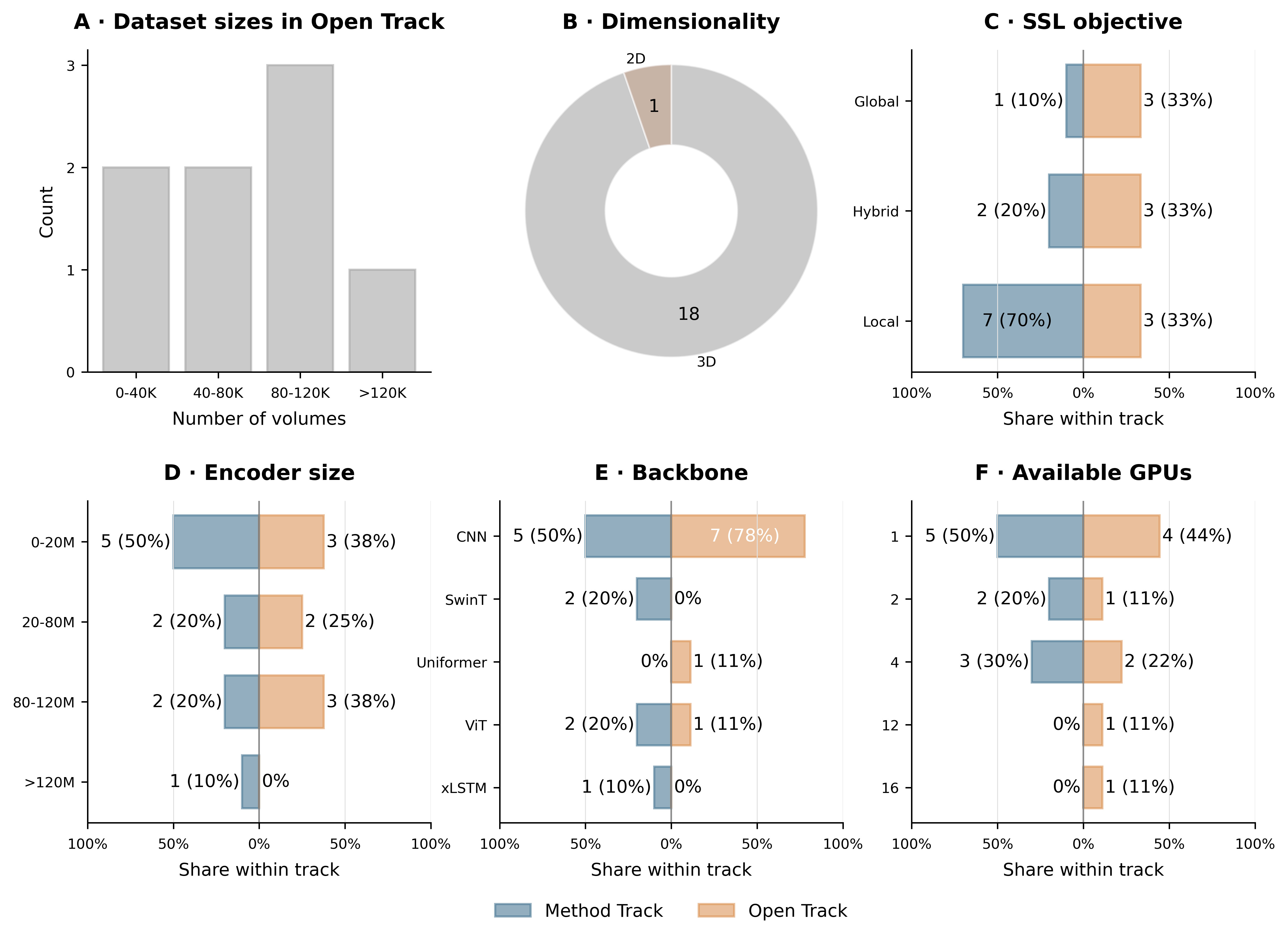
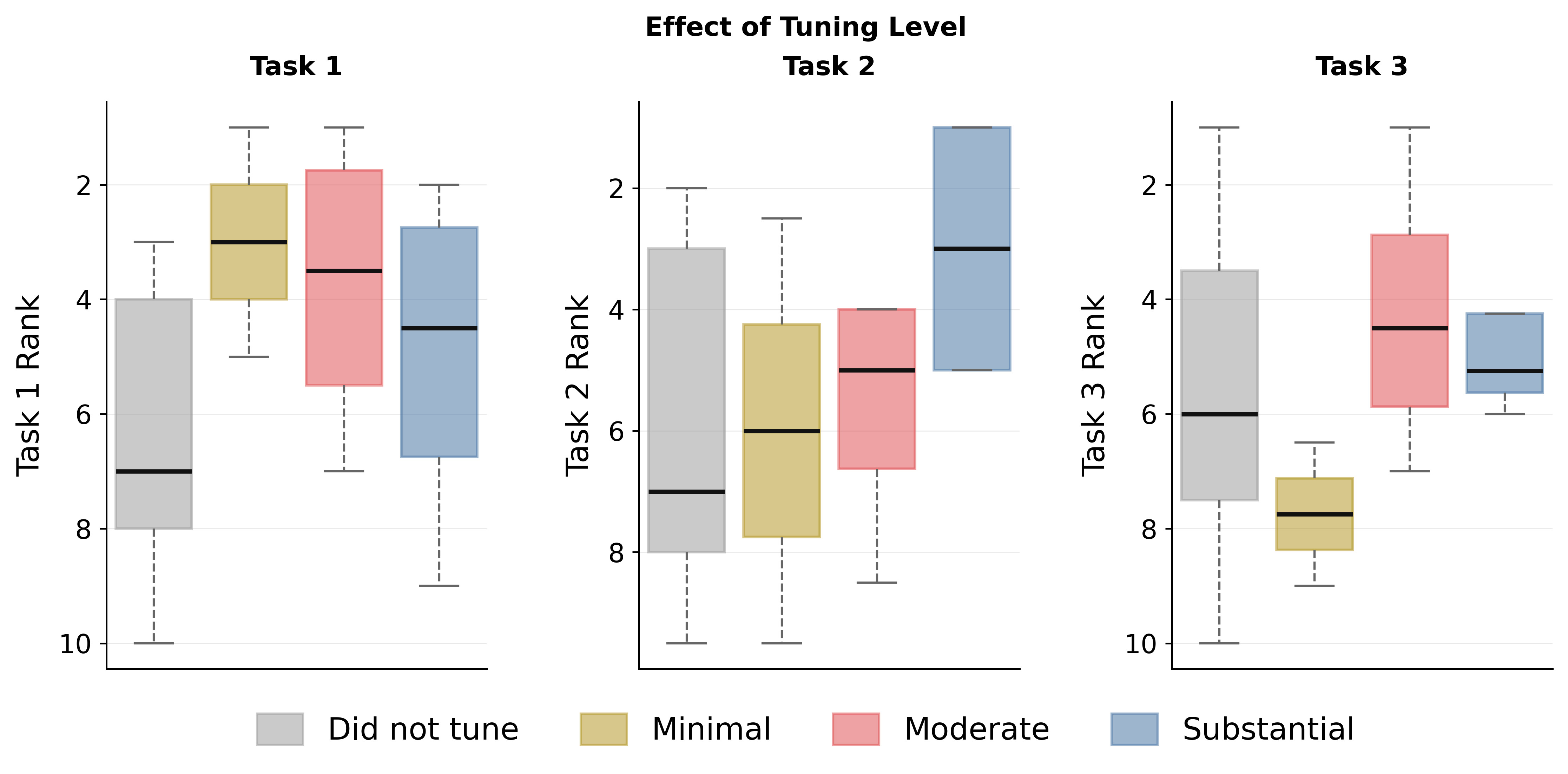
Hyperparameter tuning
Teams reported how much they tuned pretraining hyperparameters. On average, methods that did not tune performed worse. But the right amount varied by task: minimal tuning was best for classification, substantial tuning helped segmentation but hurt regression.
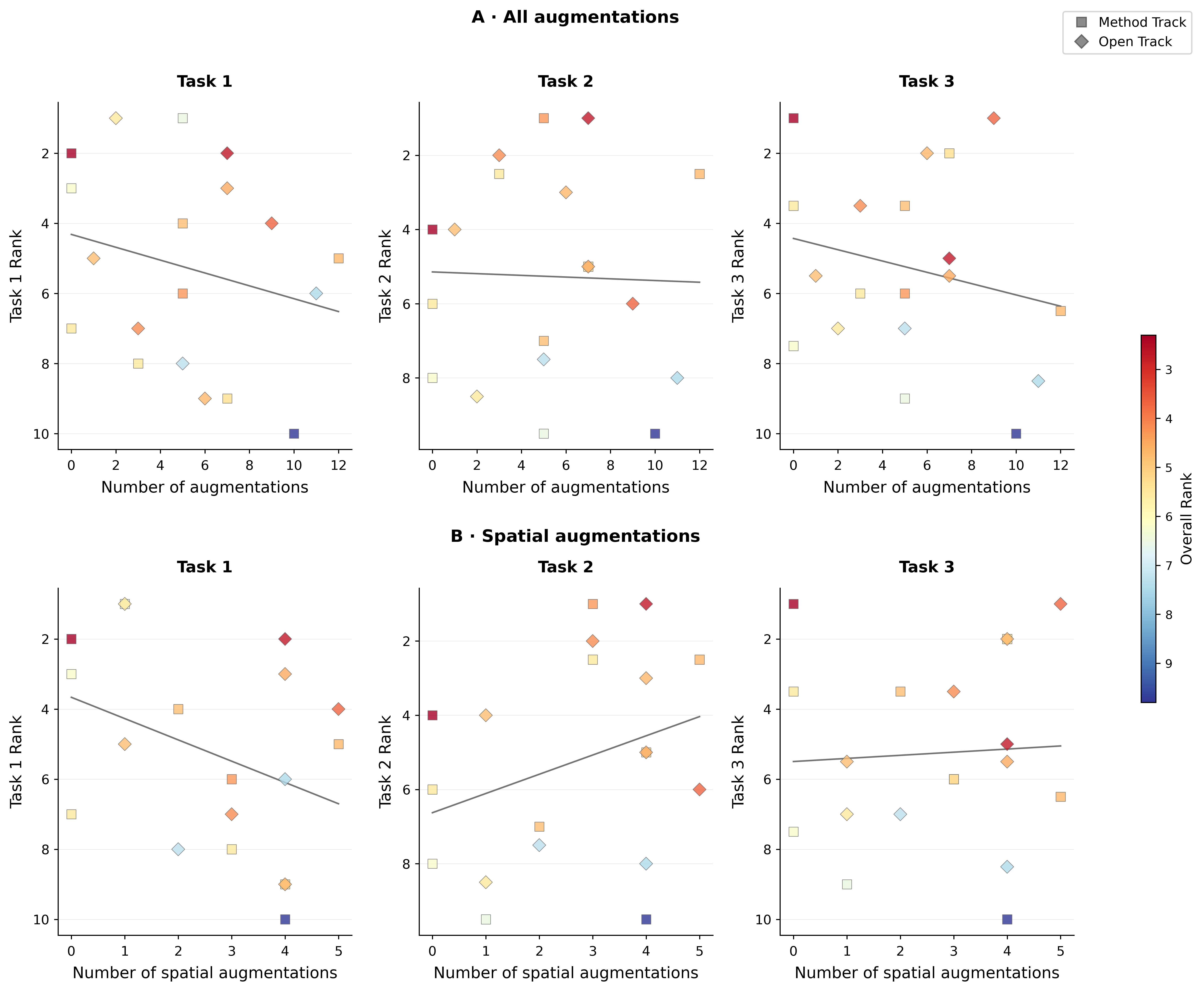
Augmentations
Three kinds of augmentations were made :
- Spatial (geometric aug) : cropping, elastic deformation, etc.
- Intensity (pixel-value transforms): Gaussian noise, Gaussian blur, etc.
- Artifacts (simulate scan artifacts): bias field, motion/ghosting, etc.
The total number of pretraining augmentations tended, on average, to hurt classification and regression. Spatial augmentations, by contrast, positively affected segmentation performance — reinforcing the broader theme that the pretraining setup should be aligned with the target task family.
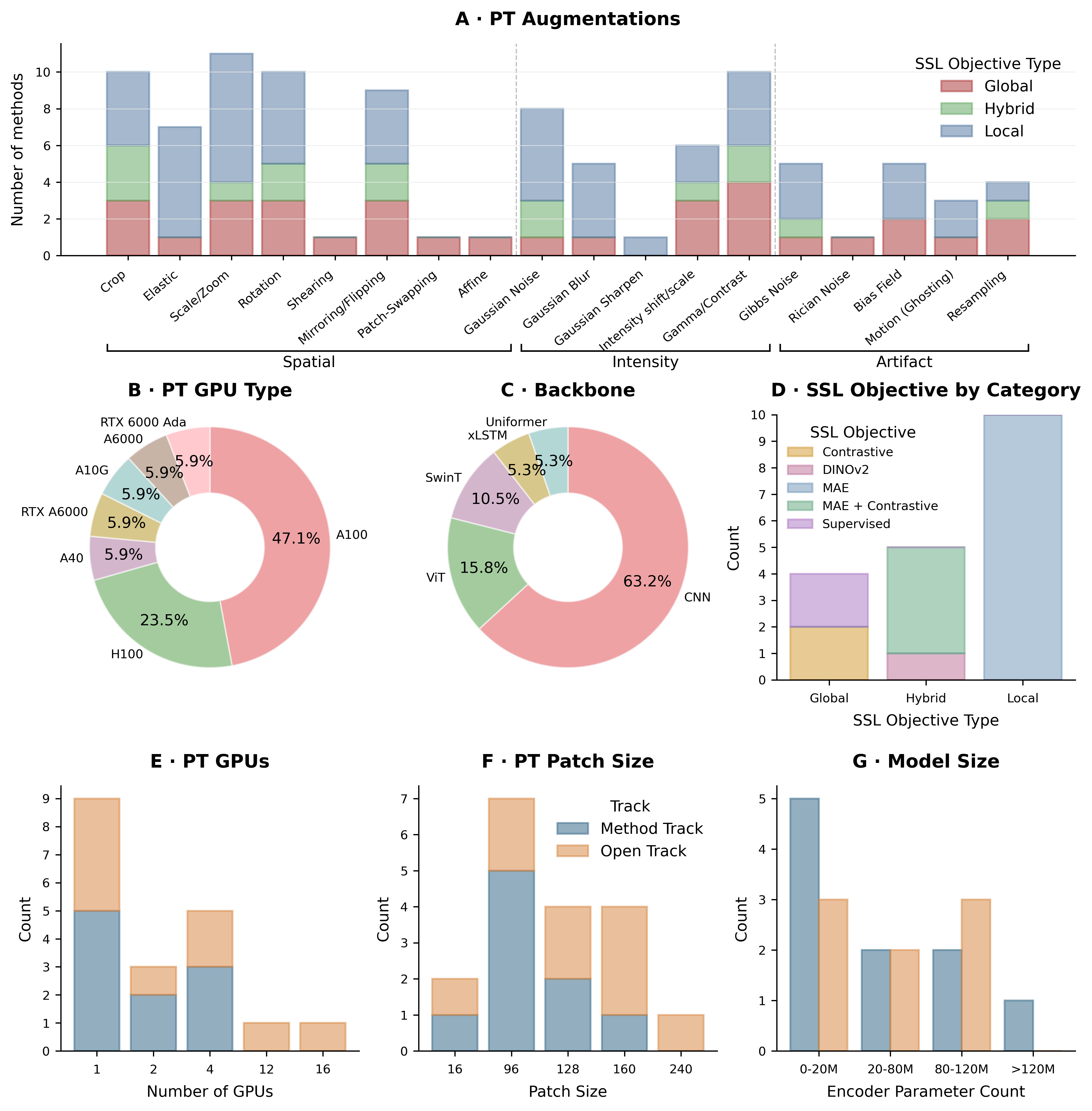
Diversity of submitted methods
The submissions spanned a wide range of backbones (CNN, Swin Transformer, Uniformer, ViT, xLSTM), SSL objectives, GPU budgets, and patch sizes — evidence of a field still in an exploratory phase without a mature consensus. CNNs remained dominant, and notably no submission implemented 3D self-distillation methods despite their growing use in large-scale visual representation learning.
6. Key takeaways and limitations
Takeaways
- SSL pretraining on heterogeneous, real-world MRI consistently improved adaptation to clinical data, with the strongest out-of-domain models beating supervised baselines — sometimes even in-domain specialists.
- There is no universal recipe: the pretext task should match the downstream task family, and the local-vs-global balance in the objective is an underexplored but consequential design parameter.
- Scaling model size or training length without rethinking objectives and data composition is unlikely to help much.
- Because no method approached task saturation, these clinically grounded benchmarks remain informative — unlike near-ceiling research-grade ones.
Limitations
- Inference-only evaluation confounds pretraining quality with finetuning, optimization, and compute, and reduces reproducibility.
- Track design was less informative than intended, since many Open-Track entries reused similar-scale models from a related challenge.
- One task per category means category-level conclusions are tied to the specific benchmarks chosen.
- Cohort effects: brain-age subjects were clinically imaged (not population healthy-aging) samples, and meningioma characteristics likely differ between the Indian finetuning and Danish test cohorts.
7. Conclusion
FOMO25 tested whether brain MRI foundation models deliver value under clinically realistic conditions — limited labels, heterogeneous acquisitions, and domain shift — and the answer was largely yes. By centering evaluation on few-shot, out-of-domain transfer, it gives a more stringent and clinically relevant view of current capabilities than research-grade benchmarks. The organizers frame it as the first of a recurring series, with a follow-up (FOMO26) already proposed.
FOMO2JOMO
FOMO2JOMO is the winner in the Method Track and a strong Open-Track entry. In the Method Track, it implements is a compact (~18.9M-parameter) 3D CNN UNet-style variational autoencoder that pretrains with a masked reconstruction loss applied at both the scan and subject level, plus a contrastive term on subject-level representations and KL regularization — a hybrid objective combining local reconstruction with global structure across a subject’s sequences.