MemSAM: Taming Segment Anything Model for Echocardiography Video Segmentation
MemSAM
MemSAM is a new video segmentation model designed for echocardiography, built on top of the SAM architecture. It is designed to address specific issues related to the application of SAM to echocardiography and video segmentation more broadly, versus image segmentation.
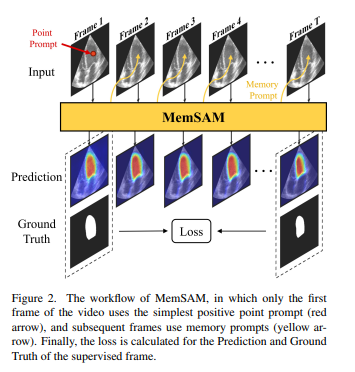
A space-time memory module allows the model to prompt itself for all but the first frame in a video sequence, and its training framework allows it to be trained with fewer annotations in a semi-supervised manner. Using memory rather than multi-frame aggregation helps limit the computational needs of the model, especially when scaling to video processing.
Background
SAM has been reimplemented for medical image segmentation, but these methods rely on dense annotations and prompts, making them mostly unsuitable for medical video segmentation.
A few methods have been proposed to adapt the SAM architecture to video segmentation, but they mostly remain limited to natural images, as medical images such as echocardiography carry much more noise. This noise is carried through intermediate features in the models, rendering them inaccurate. MemSAM builds upon ideas brought forward (XMem, etc.), but applies them more specifically to the challenges of medical image segmentation.
Method
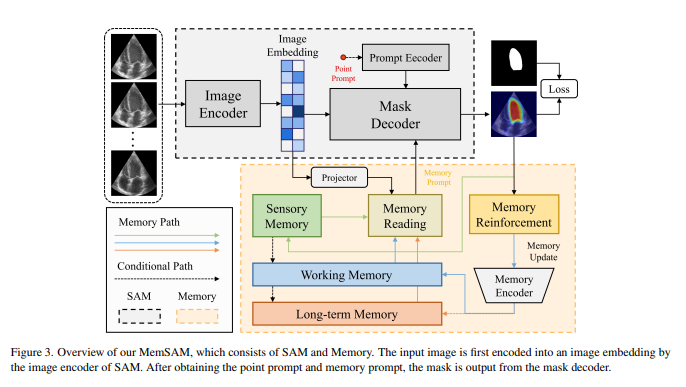
MemSAM is built on top of the original SAM model (image encoder, prompt encoder and mask decoder). The image embedding obtained from the image encoder is projected to the memory, which allows it to create a memory prompt for the mask decoder. The memory is updated after each frame is processed.
Memory
The memory is MemSAM is composed of three elements:
- Sensory memory: short-term
- Working memory: medium term, across multiple previously handled frames.
- Long-term memory: longest term, “only utilized for long videos and is omitted here”
Reading
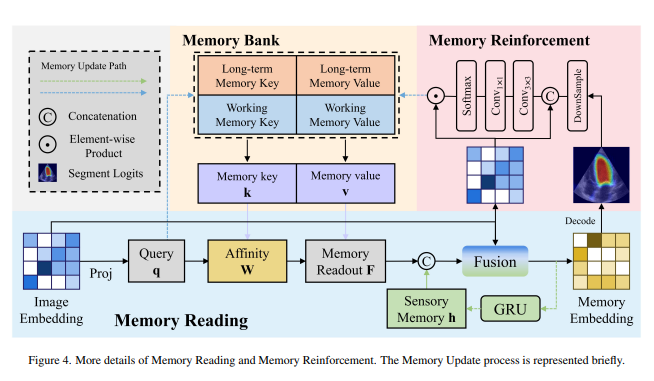
When accessing the memory, a similarity computation is done between the current image features (query) and memory entries to get working and long-term memory readouts. Entries for these elements are key-value pairs formed with image features as keys and segmentation masks as values.
These readouts are concatenated with the sensory memory to produce the final readout, which is combined with the image features for the mask decoder.
Updating
Sensory memory is updated with Gated Recurrent Units. It seems to be aimed at very recent context from the previous frame’s segmentation. Working and long-term memory is updated using the memory reinforcement mechanism.
Memory reinforcement
Emphasis on foreground features rather than background noise, achieved by using the obtained segmentation mask in the memory.
- Downsampled output from the decoder is multiplied with image features to maintain foreground features only in the working memory.
Authors show the effect of memory reinforcement on the attention that the model outputs. The attention is more localized and more effective for the segmentation task.
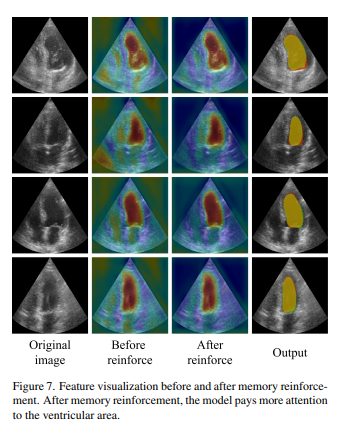
Experiments
The authors use the pre-trained SAM weights and fine-tune with both the CAMUS and EchoNet datasets. Only the image encoder from SAM was trained, along with memory elements added in.
Results show that the method improves performance compared to other SAM-based methods and more traditional architectures.
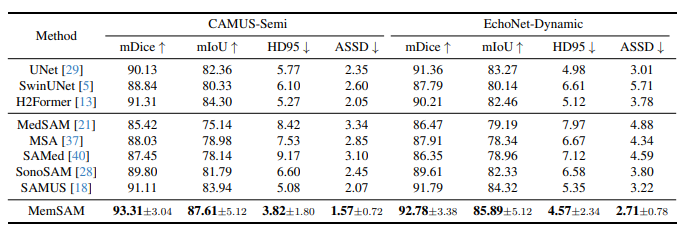
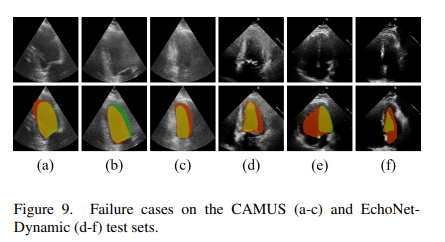
Qualitative results show that the model is more robust to blurry/unclear boundary regions compared to other methods.
Semi-supervised vs. fully-supervised
MemSAM allows for flexible use of labels when available. Loss is only calculated on frames for which a label is available, in this case, on end-systolic and end-diastolic frames. For the CAMUS dataset, which contains full segmentations for half-cycle sequences, they show improvement versus ES/ED frame annotations only.
Interpretation and conclusion
Overall, MemSAM offers an interesting new adaptation of the SAM architecture to echocardiography video segmentation. It offers good performance with few annotations.
One limitation is the heavy reliance on the first frame of the video, which determines the quality of the memory and following frame segmentations. Failure cases are shown below, demonstrating the issue.