EchoPrime: Multi-Video View-Informed Vision-Language Model for Comprehensive Echocardiography Interpretation
Objective
EchoPrime is a foundation model designed for comprehensive echocardiographic interpretation. Unlike previous models that use single views or static images, EchoPrime integrates multi-view echocardiographic videos with corresponding text reports using a vision-language framework.
Automated echocardiogram interpretation without supervised learning: EchoPrime can interpret complex cardiac features and diagnoses directly from echocardiographic video-text data, without needing supervised fine-tuning for each task.
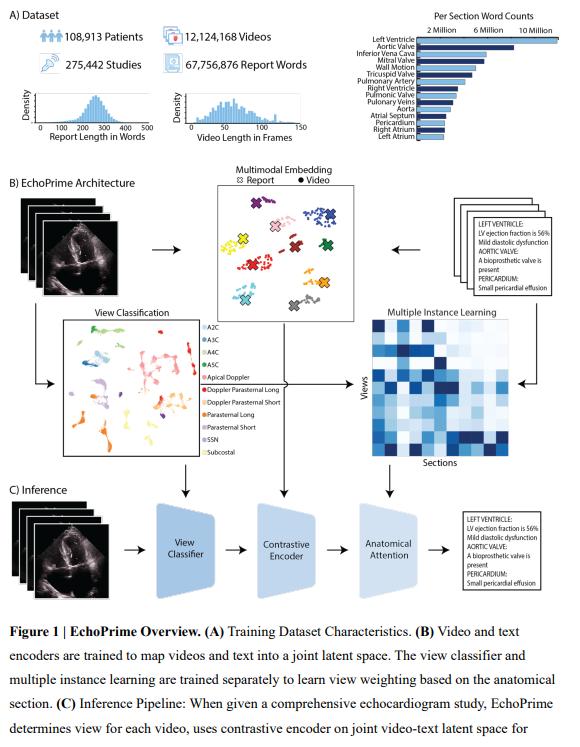
Key Features
- Massive dataset:
- Over 12 million videos
- From 275,442 studies
- Involving 108,913 patients
- Data come from 2 University hospital centers
- Contrastive Vision-Language Pretraining (CLIP-style):
- Trained to align sampled echocardiogram video clips with paired cardiologist report texts
- Builds a joint video-text representation space
- Video Encoder:
mViTbackbone - Text Encoder:
BioMedBERT
- View Classifier:
- Trained to recognize 58 standard echocardiographic views
- Supports both B-mode and Doppler modalities
- Anatomical Attention Module (Multiple Instance Learning):
- Identifies and weights the most relevant views and videos per anatomical region
- Uses attention-based deep multiple instance learning
- Retrieval-Augmented Interpretation (RAI):
- Similar to RAG (Retrieval-Augmented Generation)
- Retrieves historical echo reports most relevant to a given study
- Synthesizes them into a final interpretation, weighted by anatomical context
- Long-Context Processing:
- Processes full echo exams with multiple video views
- Handles up to 512 tokens of report text (vs. 77 in prior models like EchoCLIP)
- Disease Diagnosis with Probing:
- Applies K-Nearest Neighbors (KNN) and Linear Probing to predict conditions
- Even non-echocardiographic diseases (e.g., STEMI, amyloidosis)
- Embeddings used for zero-shot disease classification
- Applies K-Nearest Neighbors (KNN) and Linear Probing to predict conditions
- Training Infrastructure:
- Trained using two NVIDIA RTX A6000 GPUs (50GB each)
- Leveraged PyTorch’s
DistributedDataParallel
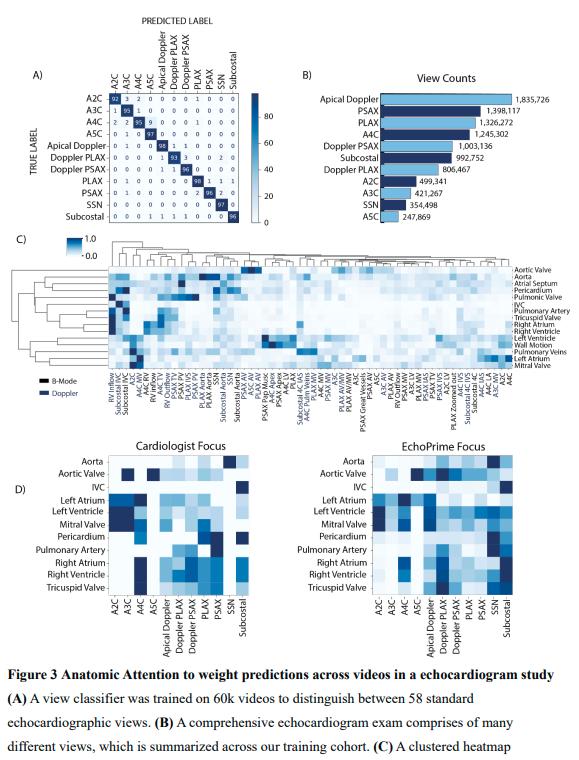
Performance Highlights
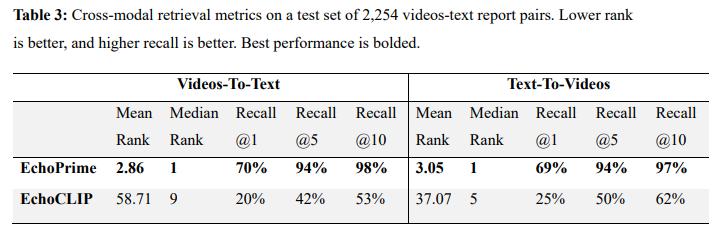
- Cross-Modal Retrieval (Zero-Shot) (Tab 3) :
- Video-to-Text Recall@10: 98%
- Text-to-Video Recall@10: 97%
- Dramatic performance gains over EchoCLIP in retrieval tasks
- Multi-View & Attention Integration Benefits:
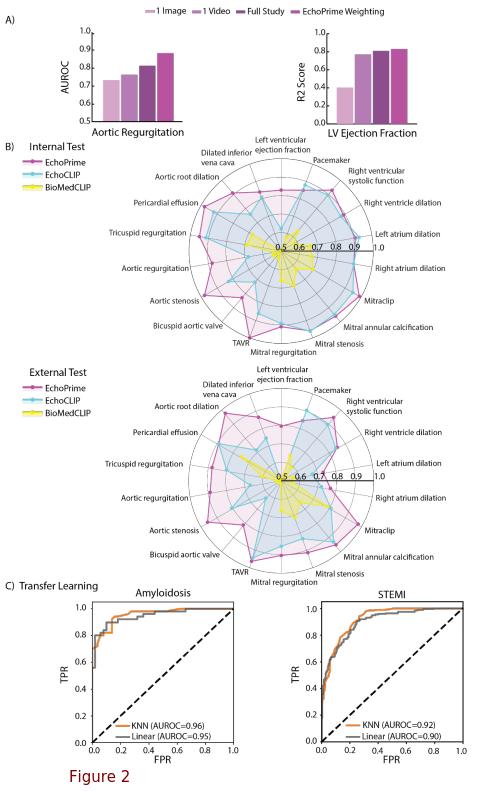
- Performance improves as model moves from (Fig 2A):
- Single frame → single video → multiple videos → multi-view + anatomical attention
- This setup mirrors clinical synthesis by cardiologistis (Fig 3D)
- The anatomical attention module enhances accuracy by:
- Focusing on the most informative views
- Down-weighting noisy or irrelevant clips
- Performance improves as model moves from (Fig 2A):
- Clinical Task Performance: (Fig 2B)
- Outperforms EchoCLIP, BioMedCLIP, and task-specific models on 23 cardiac benchmarks
- LV Ejection Fraction (MAE): 4.8% (internal), 4.1% (external)
- Tricuspid Regurgitation (AUC): 0.95
- Aortic Regurgitation (AUC): 0.88–0.89
- Also strong on mitral regurgitation, pericardial effusion, aortic stenosis, etc.
- Outperforms EchoCLIP, BioMedCLIP, and task-specific models on 23 cardiac benchmarks
Availability
- Trained on the largest echocardiography dataset to date
- Public resources:
Key Takeaways
- EchoPrime is a multi-view, video-based, vision-language foundation model
- Enables comprehensive, interpretable echo interpretation
- Handles rare diseases, non-echocardiographic diagnoses, and long textual inputs
- Sets a new standard in echocardiographic AI with potential for real-world clinical deployment