DeepSeek-V3 Technical Report
DeepSeek-V3
DeepSeek proposes novel LLM architectures (still based on transformers) and training strategies to create powerful open source LLMs with limited training costs.
Model Architecture
Similarly to DeepSeek-V2, V3 adopts Multi-Head Latent Attention (MLA) for efficient inference and mixture of experts (DeepSeekMoE) for economical training. The main addition to the architecture, from V2, is the auxiliary-loss-free load balancing.
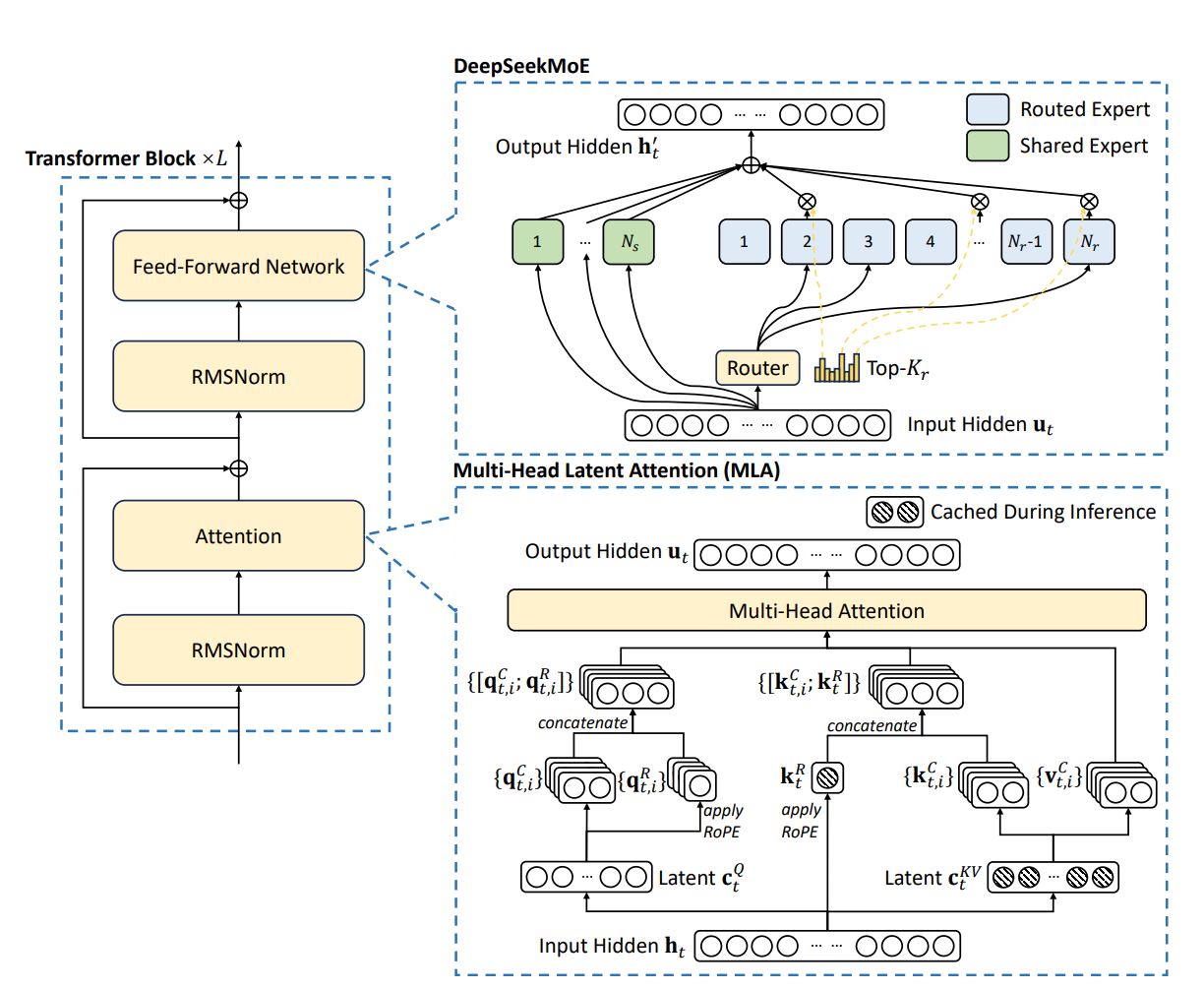
Multi-Head Latent Attention
MLA aims to offer more efficient inference in autoregressive text generation (especially for long contexts), using a key-value cache to avoid recalculating them at each generation step. However, such a cache comes with large memory overhead.
Joint compression of the key and values to reduce KV cache size during inference.
Compression matrices are used for up- and down-projection ($U$ and $D$ superscripts respectively).
RoPE is used to maintain positional information of keys and queries. An additional projection matrix $W^{KR}$ accounts for the rotation key carrying this information.

*Only blue vectors need to be cached during generation.
Compression is also applied to the queries to minimize memory footprint:
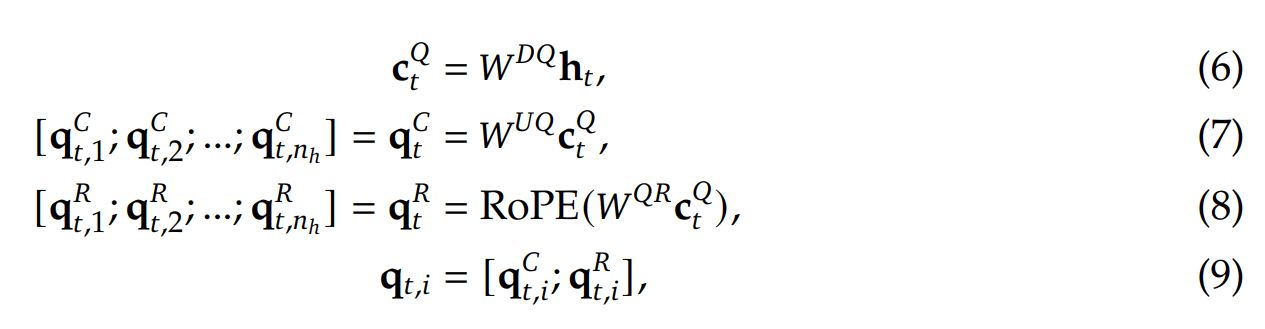
When computing attention, the compressed output is multiplied by the output up-projection matrix to regain the full dimension.
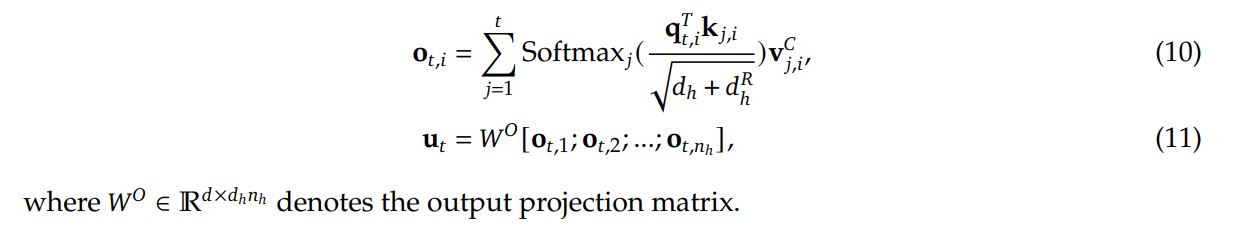
DeepSeekMOE and Auxiliary-loss-free Load Balancing
DeepSeekMOE
In the feed-forward networks (FFN) of DeepSeekV3, DeepSeekMOE architecture 1 is used to avoid activating all parameters at once for each input token.
The FFN layer in DeepSeekMOE is computed as follows:
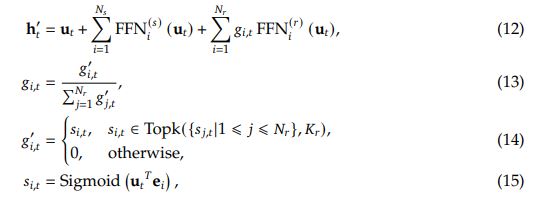
$g_t$ is the gating value for the i-th expert
$s_i$ is token-to-expert affinity.
$e_i$ is the centroid vector of the i-th routed expert.
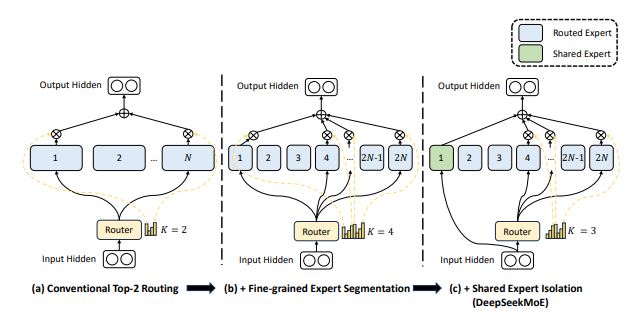
DeepSeekMOE uses more fine-grained experts than other MOE architectures, in order to ensure knowledge is decomposed more between experts. Number of experts grows from N to mN, hidden dimension of each expert is reduced to 1/m, and m more experts are activated each token. The computational cost is kept identical.
It also isolated some experts as shared ones to learn common knowledge across tasks, possibly allowing other experts to specialize more.
Auxiliary-loss-free Load Balancing
Unbalanced load in MOE scenarios can cause routing collapse and diminish computational efficiency. Auxiliary loss can be used but has been shown to reduce performance.
Instead, auxiliary-loss-free load balancing proposes to add a bias term to the affinity scores when calculating top-K routing.
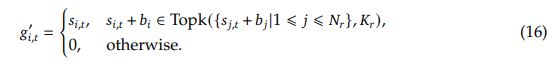
During training, the expert load is monitored at each training step, and the bias term is adjusted by a factor $\gamma$ if it’s corresponding expert is overloaded or underloaded. $\gamma$ is called bias update speed.
Authors say that this way of balancing experts allows DeepSeek-V3 to achieve better performance than models trained with auxiliary losses.
Multi-Token Prediction
To improve training efficiency, Multi-Token Prediction (MTP) is used. It allows predictions of future tokens at each prediction, allowing for denser training signals, improving data efficiency.
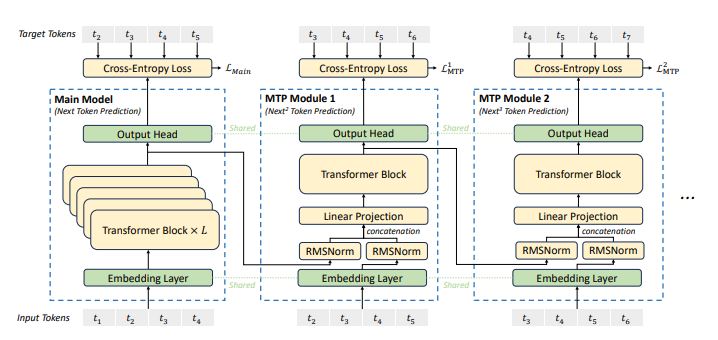
Unlike other MTP methods, DeepSeek’s MTP maintains the causal chain by predicting the additional tokens sequentially (rather than in parallel).
An additional loss is used in training, as an other training objective, to verify multiple output tokens at once. It allows the model to refine it’s understanding of the current context by looking ahead.
MTP modules are dropped at inference as they are not required. They can however be used to accelerate generation. The acceptance rate of the second token prediction from MTP is between 85 and 90%.
Training
Many hardware optmisation steps are detailed, they are not covered in this review.
- Trained with 2048 NVIDIA H800 GPUs.
- FP8 training with some innovations.
- Parallelism strategies
- …
Training steps
Pre-training
V3 is trained on 14.8T high-quality tokens, with an emphasis on mathematical and programming samples, spanning multiple languages (not limited to English and Chinese).
It uses fill-in-middle (FIM) strategy, training the model to predict missing text (or code) given surrounding context, in a structured data environment:
<|fim_begin|> 𝑓_pre <|fim_hole|> 𝑓_suf <|fim_end|> 𝑓_middle <|eos_token|>
FIM is useful for infilling tasks such as writing code.
Post-training
Supervised Fine-Tuning
Supervised training data is generated using various methods relying on previously trained models and validated using human annotators.
Reasoning data (math, code, logic puzzles, etc.) is generated using R1 models optimized for a specific domain. The goal is to transmit some of the reasoning capabilities of the R1 model to the V3 model. Rejection sampling is used to ensure quality of the SFT data.
For non-reasoning data (simple questions, creative writing, etc.), DeepSeek-V2.5 is used to generate responses which are verified by humans.
RL
The RL process uses both rule-based and model-based reward models.
Rule based reward models are used for tasks which can be evaluated objectively, such as math and coding. The model must output answers in a specific format so they can be evaluated with rules (compiler, calculator, etc.).
Model-based reward models are similar to other RLHF methods that make use of human preference annotations on sampled answers.
Algorithm
GRPO is used as the RL algorithm. It forgoes the need for a critic model which typically has the same size as the policy model. Instead, it uses group scores as a baseline.
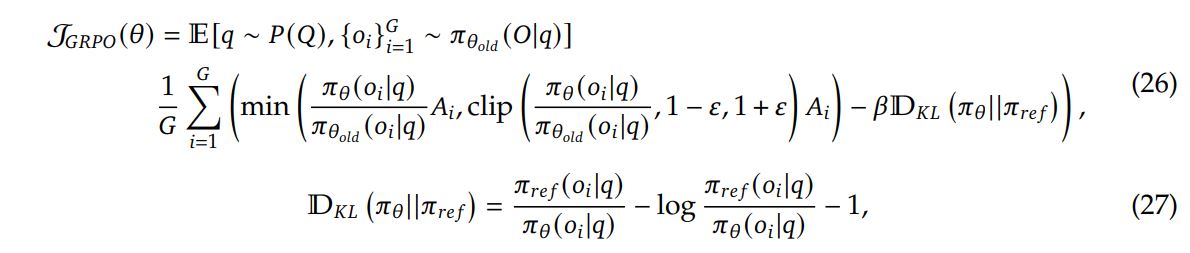
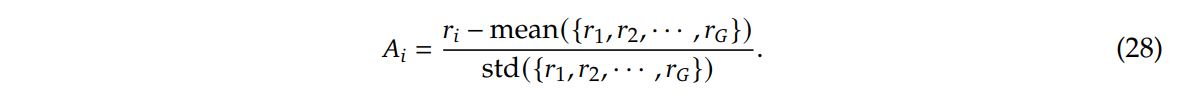
Results and discussion
DeepSeek-V3 performs very well compared to other state-of-the-art large LLMs. It does so with less training costs than many competitors (2.788M H800 GPU hours for full training).
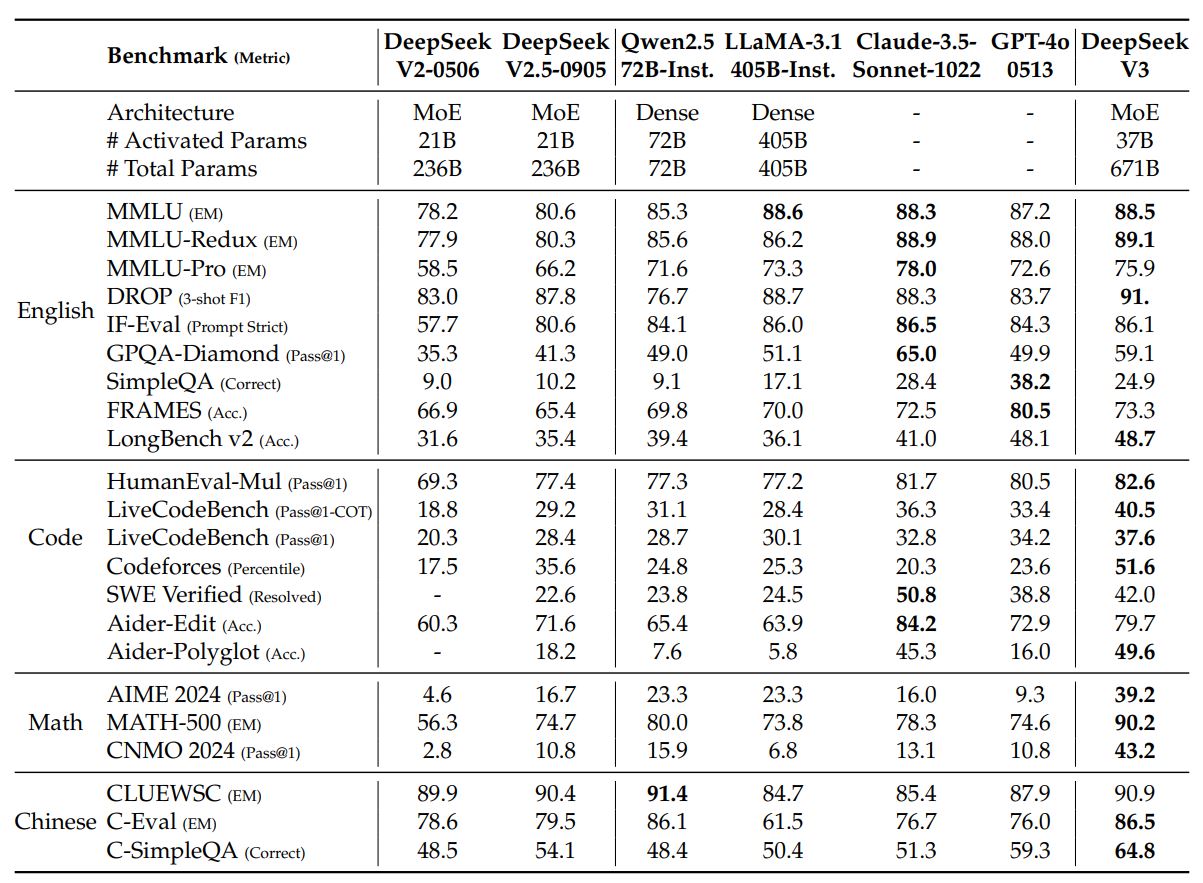
DeepSeek-V3 shows that complex and well thought out design, architectural and training choices can significantly reduce training time and costs, making powerful LLMs more accessible to smaller development teams.
References
-
Dai, D., Deng, C., Zhao, C., Xu, R. X., Gao, H., Chen, D., … & Liang, W. (2024). Deepseekmoe: Towards ultimate expert specialization in mixture-of-experts language models. arXiv preprint arXiv:2401.06066. ↩