UniverSeg: Universal Medical Image Segmentation
Introduction
There are many known issues related to clinical use of image segmentation models including most notably, domain shifts. Retraining new models for each new domain or task is unfeasible for clinical researchers without in-depth knowledge of deep learning.
Tasks are varied and can be differentiated by segmented class, modality, view, etc.
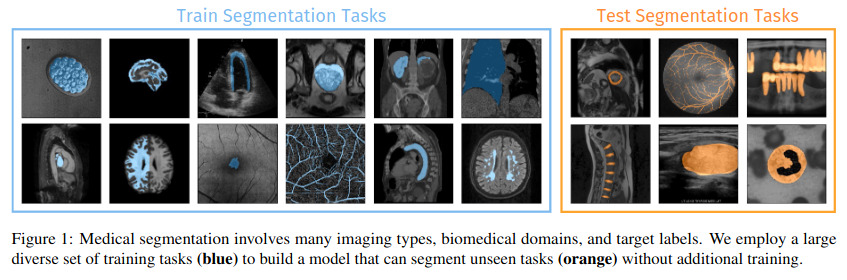
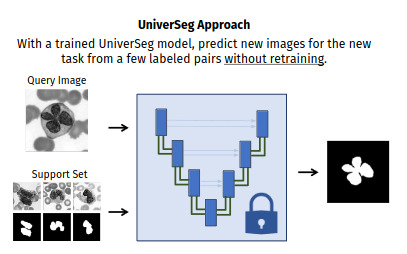
UniverSeg addresses these issues by providing a fully trained singular model capable of generalizing to unseen tasks using few labeled examples, without any further training.
Method
In the typical segmentation context for a tasks \(t\), a function \(\hat{y} = f^t_\theta(x)\) is learned to estimate a segmenation map \(\hat{y}\) from an image \(x\).
UniverSeg learns a universal function \(\hat{y} = f^t_\theta(x^t, S^t)\) to predict a label map for \(x^t\) and a task specfic support set \(S^t=\{(x^t_j, y^t_j)\}^N_{j=1}\). The support set is composed of labeled images for a given segmentation task.
Model
The structure of the model used in UniverSeg is the same encoder-decoder structure as a U-Net, built with new CrossBlock modules. The model used for experiments contains 5 CrossBlock stages in the encoder and 4 in the decoder.
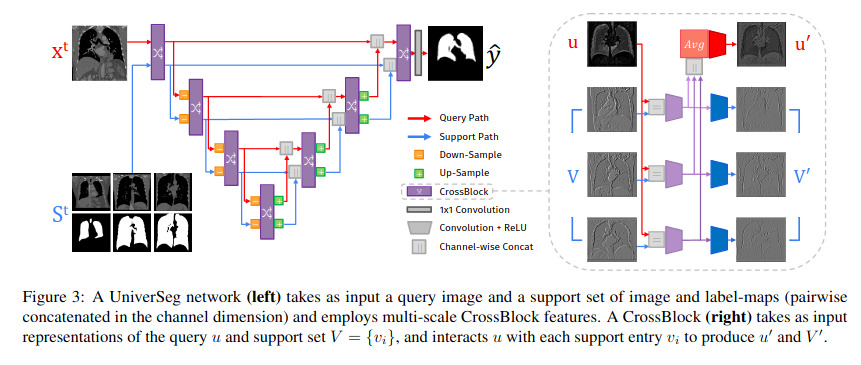
CrossConv Layer
The cross-convolutional layer introduced allows a query feature map \(u\) to interact with multiple support feature maps \(V = \{v_i\}^n_{i=1}\).
\[\text{CrossConv}(u, V; \theta_z) = \{z_i\}^n_{i=1}, \text{where} \ z_i = \text{Conv}(u||v_i; \theta_z)\]Weights \(\theta_z\) are reused for each support feature map making the layer invariant to permutations within \(V\).
CrossBlock Modules
CrossConv layers are used in a higher level module called CrossBlock modules that produce new versions of the query and support representations in at different steps of the network.
\(\text{CrossBlock}(u, V; \theta_z, \theta_v) = (u', V')\) where
\(z_i = A(\text{CrossConv}(u, v_i; \theta_z)) \quad \text{for} \ i = 1...n\),
\[u' = 1/n \sum^n_{i=1}z_i\] \[V' = A(\text{Conv}(z_i; \theta_v)) \quad \text{for} \ i = 1...n\]A is a non-linear activation function. In this paper A is a LeakyReLU.
Training
Training is done using typical supervised loss functions (cross-entropy, soft Dice), using various training tasks. The task, query and support set are sampled at each training step.
Standard image augmentations are applied independantly to the query and each element the support set. Task-augmentation is also applied to all query/support images uniformly to help generalize to new tasks (e.g. horizontal flip to all, edge detection of the segmentation maps, etc.).
Inference
Inference of the UniverSeg model is done by averaging the output of predictions obtained with different support sets: \(\hat{y} = 1/K \sum^K_{i=1}f_\theta(x, S^T_k)\). The size of the support sets is 64 in most experiments.
Data
The model is trained using a large dataset named MegaMedical containing many tasks. It contains 26 medical domains, 16 imaging modalities, using images from 53 datasets.
Domains include eyes, lungs, spine vertebrae, white blood cells, abdominal, brain, etc.
UniverSeg deals with 2D binary classification. Individual tasks are therefore created for each class, in the case of multiclass labels in certain datasets.
Synthetic tasks are added to improve generalizability.
Results
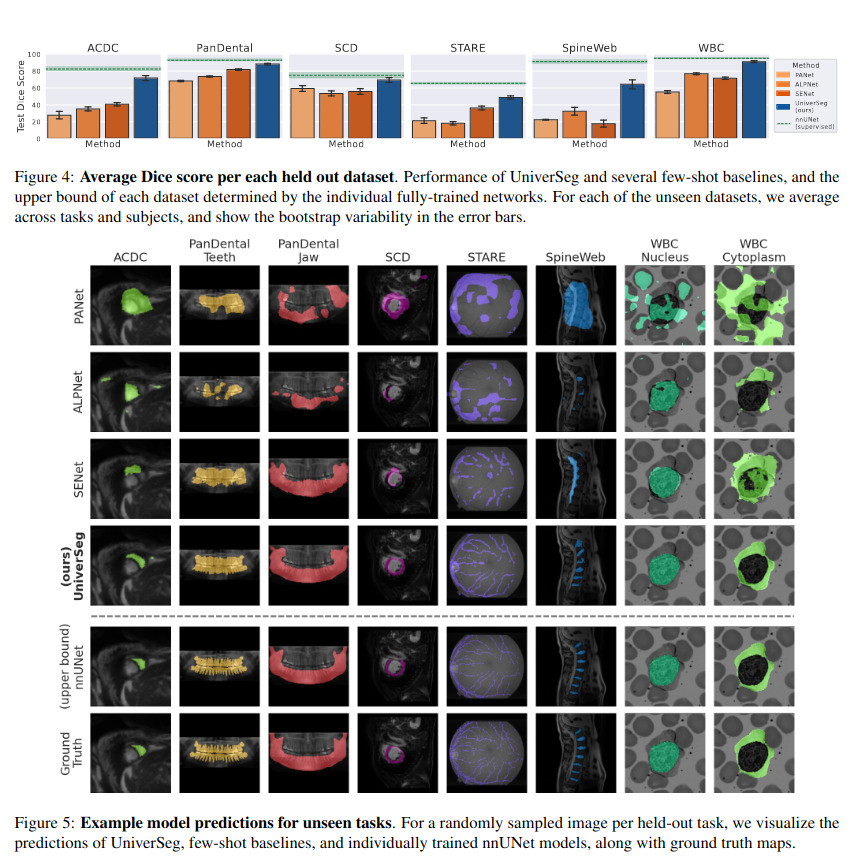
Compared to other few-shot baselines, UniverSeg performs better, and in some cases reaches performance similar to task-specific nnUnet baselines (upper-bound). It also requires fewer parameters than most other methods.
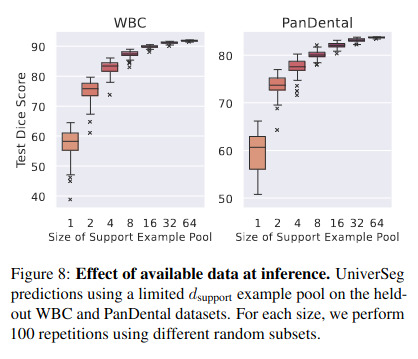
Support set size has a large impact on segmentation performance of unseen datasets, plateauing starting at around 16. The same trend is observed with support size at training time.
Interesting points:
- Model trained on synthetic data only performed well on medical images during testing.
- When limiting the training domains, the most accurate model was trained with heart, eyes, abdomen and brain, while the least accurate was trained mostly on lesion tasks.
- When testing different ensembling/support set sizes, support set size 64 and ensemble size 1 performed better than support size 2 (4 and 8 also) and ensemble size 64, even if less total support examples were seen at inference.
Conclusions
UniverSeg offers a new framework for few-shot image segmentation without the need for any additional training or fine-tuning. It offers segmentation performance that is competitive with task-specific nnUnets in certain tasks and outperforms other methods.