Editing Models with Task Arithmetic
Abstract and Introduction
- Main Concept: this paper introduces “task vectors” which are directions in the weight space of a pre-trained model that enhance performance on specific tasks when modified.
- Objective: To manipulate these vectors to alter model behaviors efficiently, with a focus on either improving task performance or removing unwanted biases.
Task Vectors and Model Editing
-
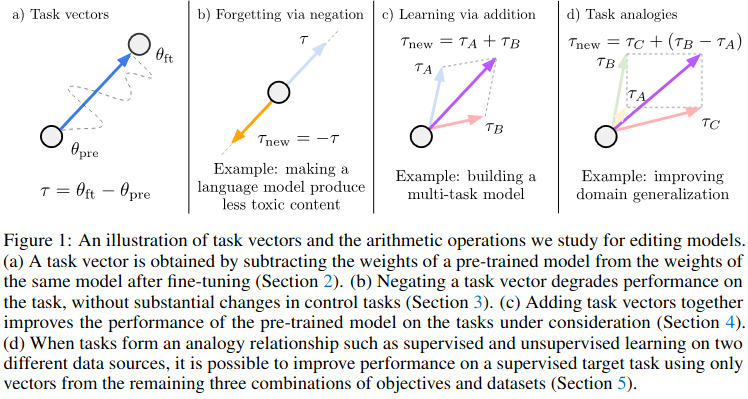
Creation of Task Vectors: Task vectors are derived by subtracting the weights of a pre-trained model from those fine-tuned on a specific task. Such a task vector is illustrated in figure 1 (a).
-
Manipulation Techniques: Pretrained models can be altered through arithmetic operations like negation and addition to edit the model’s behavior in targeted ways. Three types of manipulations are presented, namely : Negation, Addition and Task analogy, all illustrated in figure 1 (b), (c), (d).
Negation of Task Vectors
- Purpose and Use: Negating a task vector reduces the model’s effectiveness on that task, which is useful for “unlearning” undesirable behaviors or biases.
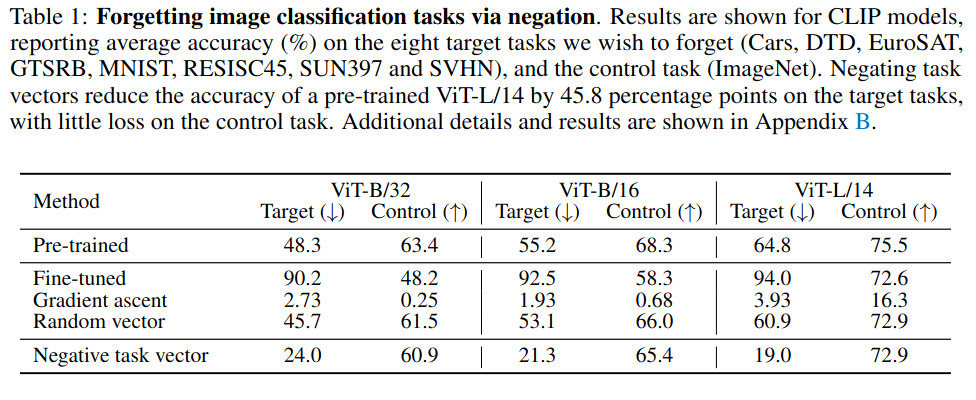
- Applications: Demonstrated for mitigating unwanted behaviors like toxic language generation, with minimal impact on other model functions. Table 1 illustrates a CLIP model pre-trained on imageNet from which 8 target tasks have been negated. Results show that negation reduces the performances on one specific task without diterring the performances on the other tasks (control dataset).
Addition of Task Vectors
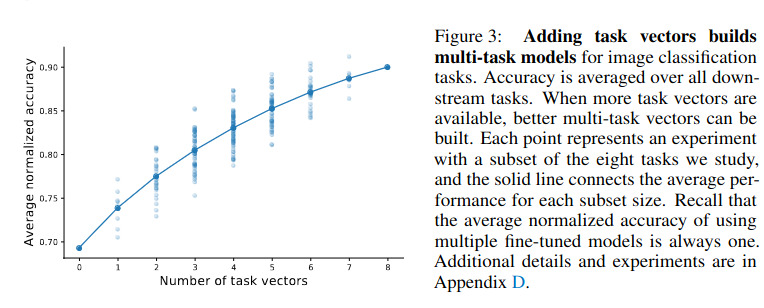
- Enhancing Multitasking: Adding task vectors from different tasks improves the model’s ability to handle multiple tasks simultaneously. This is illustrated in figure 3. As mentioned in the paper :
“vectors for all possible subsets of the tasks (128 in total). In Figure 3, we show how the normalized accuracy of the resulting models, averaged over all the eight tasks. As the number of available task vectors increases, better multi-task models can be produced.”
Analogy
- Improving Sparse Data Performance: By using task analogies, vector addition can enhance performance on tasks with limited data by leveraging similarities between related tasks. As mentioned on the paper : “task analogies in the form “A is to B as C is to D”, and show that task arithmetic using vectors from the first three tasks improves performance on task D even if little or no data for that task is available”. An example is illustrated in Table 4 between the Yelp and Amazon dataset, two sentiment analysis datasets.
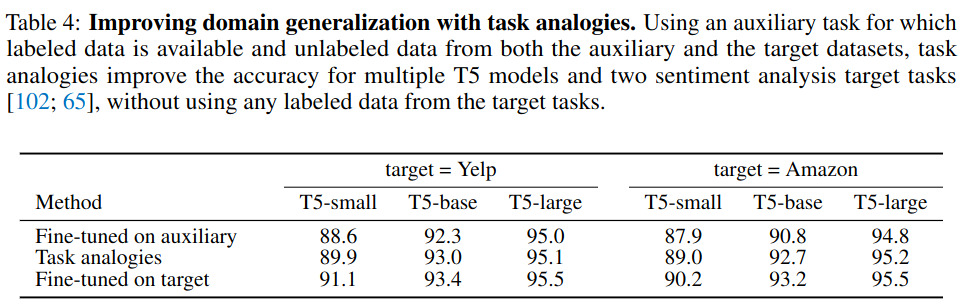
the experiment is further detailed in this screenshot

Discussion
-
Impact of Learning Rates and Seeds: Discusses how variations in learning rates and random seed initializations significantly affect the model’s performance, highlighting the importance of careful tuning.
-
Practical Limitations: Notes limitations such as the necessity for the same model architecture and shared pre-training initializations for the effective application of task vector arithmetic.
-
Further Insights: Provides insights into the relationship between model ensembles and weight averaging, suggesting similarities that may enhance generalization and robustness.
This section offers crucial insights into the practical applications and inherent challenges of the task vector approach.