ResMLP: Feedforward networks for image classification with data-efficient training
Highlights
- Architecture using only linear (fully-connected) layers at its core
- No convolutions, transformer layers, batch norm, pooling (except at the end).
- Performance competitive to CNNs and Vision Transformers
Methods
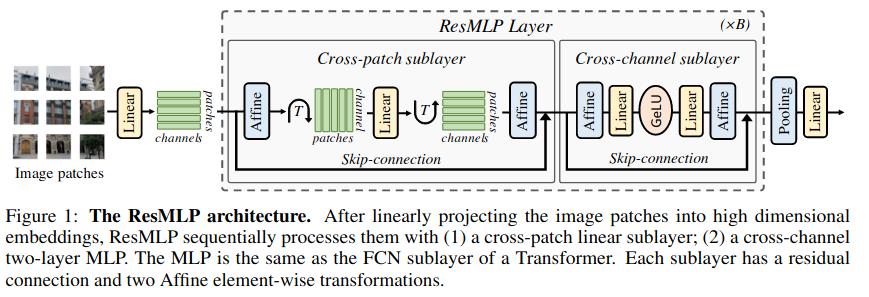
- Split image in non-overlapping patches. Typically 16x16 images. Fixed image size: 224x224.
- Take each patch, and flatten and embed it to a high dimensionality vector : we get a (num_patches, vec_size) matrix
- Residual Multi-Perceptron Layer (repeated multiple times)
- Cross-patch connectivity block: transpose the data matrix before passing it through a linear layer. Now, each channel is independent, and a patch can be influenced by all patches from the previous layer. The weights are the same for all channels.
- Cross-channel connectivity block: apply a linear layers to the (num_patches, vec_size).
- Non-linearities: Only one GeLU layer after the cross-channel communication.
- Normalization layers: No batch norm, layer norm or anything. Replaced by a learned affine transformation. Used before and after blocks of operations.
- Skip connections
- Global average pooling
- Final linear layer
They also propose a model for sequence-to-sequence modeling.
The authors reuse many aspects of the methodology of their previous paper(s) about the training of Vision Transformers.
Data
- ImageNet-1k
- ImageNet-real (some results)
- ImageNet-v2 (some results)
- ImageNet-21k (some results)
Experiments
- Compare with other classification architectures (CNN, transformers) in supervised learning
- Better measure generalisation by using other ImageNet-like datasets with a “clearly defined” test set
- Self-supervised learning (DINO)
- Knowledge Distillation (Distill a CNN into a ResMLP)
-
Seq2Seq
- Visualisation of cross-patch connectivity
- Sparsity of the weights
- Ablation studies
Results
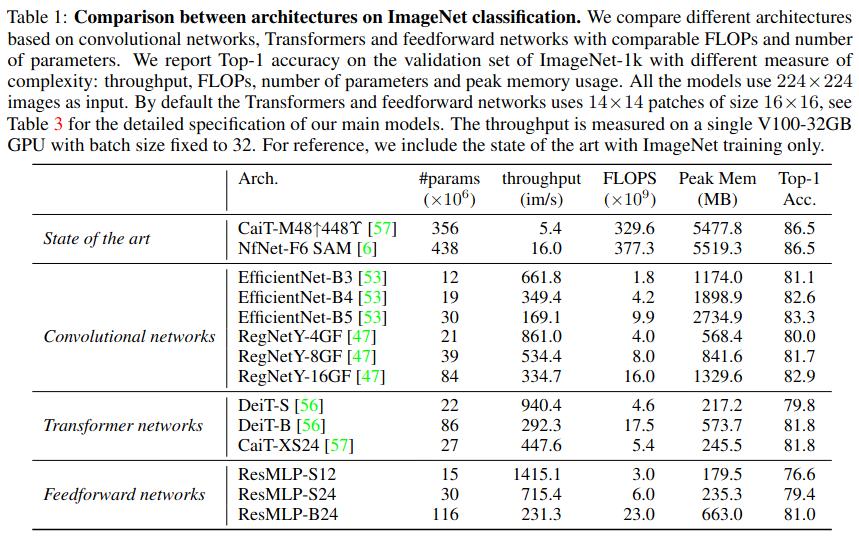

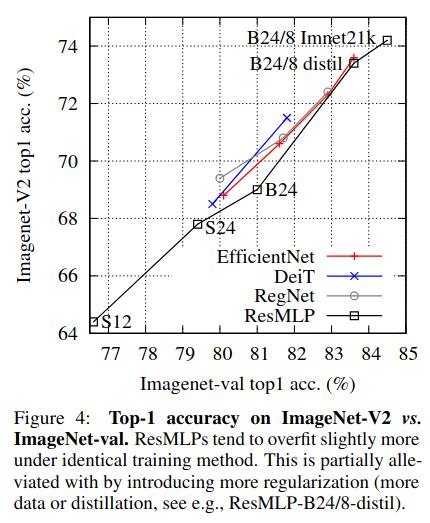
Conclusions
- Surprising results for a model consisting mainly of linear layers
- Benefits greatly from Knowledge Distillation
- Something similar to self-attention can be done simpler than what is seen in Transformers
- The use of BatchNorm, and normalization layers that rely on batch statistics in general, is questionned.
Remarks
- They are not alone studying this, they mention 4 concurrent works (footnote p.2)
- Maybe it shows that the vast majority of examples these datasets can be solved using crude intuition. It’s only for a small number of harder examples that a more advanced architecture makes a difference. But in the small number of examples where ResMLP fails, it may not be acceptable mistakes.
- Adversarial examples? Easier to fool this model?