Emerging Properties in Self-Supervised Vision Transformers
Highlights
- New self-supervised learning framework, called DINO, that synergizes especially well with vision transformers (ViT);
- In-depth comparison of emerging properties ViT pretrained with DINO, compared to convolutional networks (convnets) and
other ViT trained in a supervised fashion. The most interesting emerging properties are:
- Self-attention modules of the last block explicitly contain scene layout and object boundaries;
- Features perform well at top-1 accuracy on ImageNet when used as input to a basic nearest neighbor classifier.
Introduction
The authors theorize that one of the main reasons for the success of transformers in NLP is the use of self-supervised training, and that the muted success of ViT comes from supervision in pretraining. According to them:
image level supervision often reduces the rich visual information contained in an image to a single concept selected from a predefined set of a few thousand categories of objects.
While not proposing much brand new ideas, the authors perform a thorough investigative work into the engineering required to make self-supervised ViT work in computer vision, listing the required tricks to avoid collapse during training.
Methods
The new contribution is a self-supervised training method called DINO, because it can interpreted as knowledge distillation with no labels. Fig. 2 summarizes the main idea behind DINO.
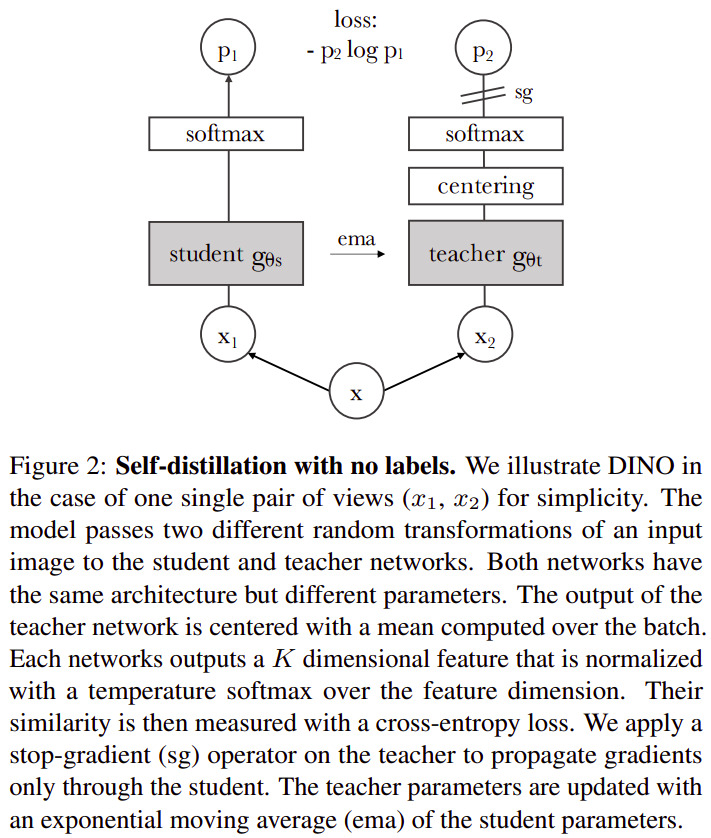
Main engineering components to ensure good training:
- Multi-crop training: The self-supervised training is formulated as learning to predict the same representation for different crops of the image. The crops are categorized as global views (crop covers > 50% of the original image), or local views (crop covers < 50% of the original image). The teacher network receives only global views, while the student network receives all the crops. The idea behind this is to encourage “local-to-global” correspondence in extracted features.
- Momentum encoder: The teacher network is updated with an exponential moving average (ema) of student parameters. In contrast to other teacher-student approaches, the teacher here consistently out-performs the student. The authors theorize that the teacher becomes a sort of model ensemble, similar to Polyak-Ruppert averaging.
- Centering and sharpening of teacher outputs: To avoid collapse towards learning trivial features, the authors
propose to use two operations with opposite effects on the teacher’s outputs, that together make the network learn
adequately:
- Centering: Basically adding a bias term to the output s.t. \(g_{\theta}(x) \leftarrow g_{\theta}(x) + c\), where the centering term \(c\) is computed on batch statistics and updated using an ema. It prevents one dimension from dominating a softmax, but encourages collapse to a uniform distribution.
- Sharpening: Obtained by using a low value for the temperature \(\tau\) in the softmax: \(\frac{exp(g_{\theta}(x) / \tau)}{\sum^K_{k=1} exp(g_{\theta}(x) / \tau)}\). It has the opposite effect of centering, i.e. it “sharpens” the softmax, at the risk of letting one dimension dominate.
Data
The authors mainly used DINO to pretrain ViT using ImageNet, but in some experiments’ setup other (unsupervised) datasets were used.
Results
The full paper (and even more so with the supplementary materials) provides a lot of results on different downstream tasks. They also provide a comprehensive ablation study regarding DINO’s components, as well as an analysis of how and why training fails when the framework lacks some essential tricks.
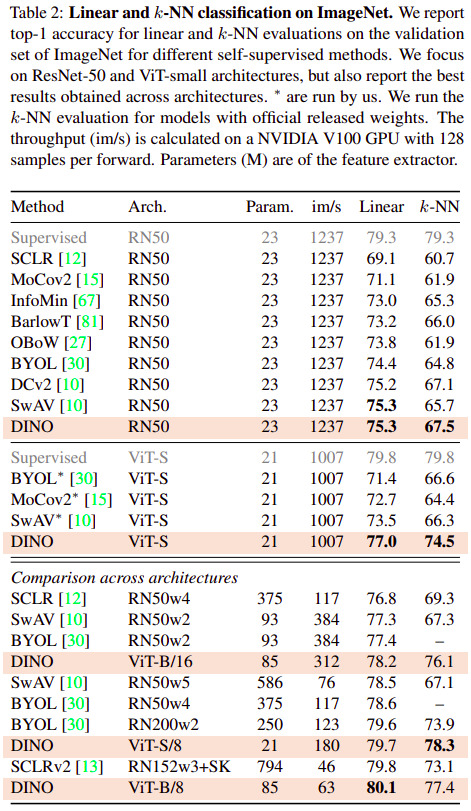
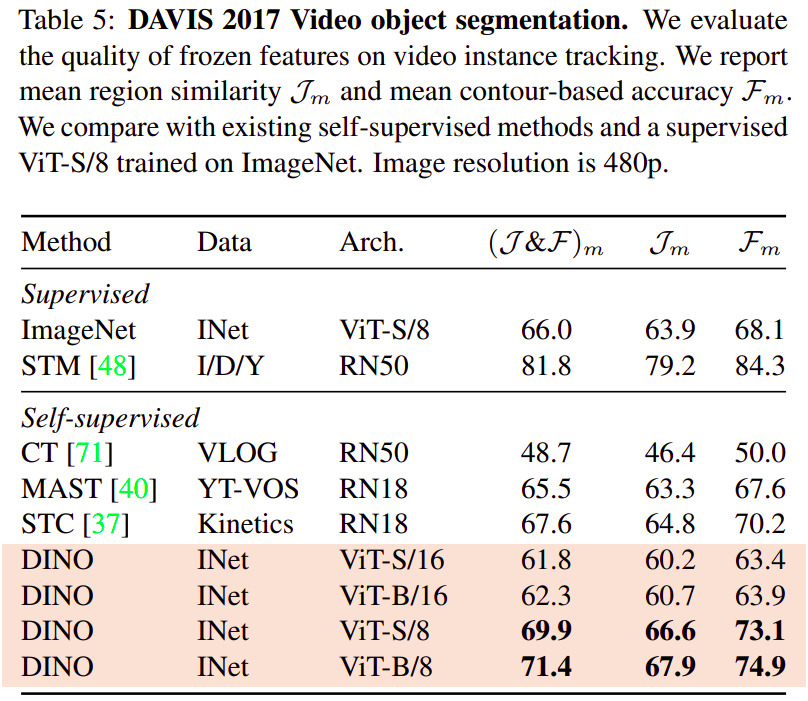
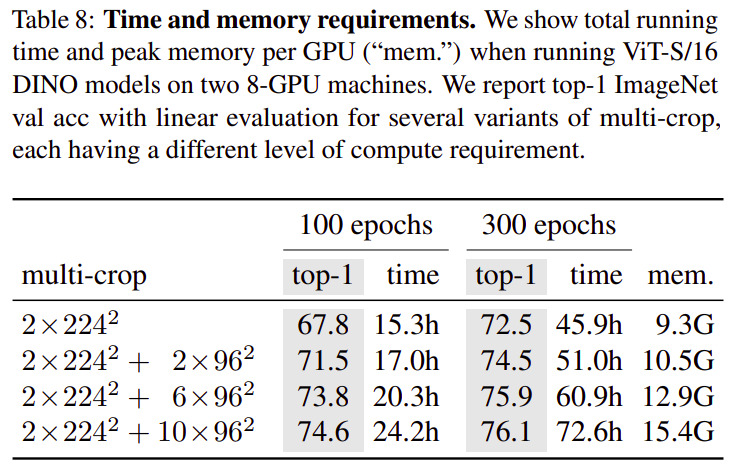
The figures/tables below were selected because they detail results on common image tasks/datasets.


References
- Code is available on GitHub: https://github.com/facebookresearch/dino