AAVAE: Augmentation-Augmented Variational Autoencoders
Highlights
- New VAE training scheme that outperforms original VAEs in downstream classification
- The KL divergence term is removed
- “Denoising” is introduced
Introduction
Authors propose a new scheme for training VAEs. They want to revive the idea of using VAEs for self-supervised representation learning. A popular benchmark for self-supervised representation learning is to first train an encoder without supervision, then train a single-layer classifier with supervision that takes the latent vectors as input. SimCLR is very strong in this benchmark. AEs and VAEs obtain very poor results. AAVAE (Augmentation-Augmented VAE) obtains results competitive to SimCLR.
Augmentation-Augmented VAE is a silly name1.
Methods
In short, here is what changes from VAE to AAVAE:
- Images fed to the encoder are randomly transformed (using a data-augmentation pipeline typical for images)
- The decoder has to recover the original, non-transformed image
- The KL-divergence term is removed from the loss
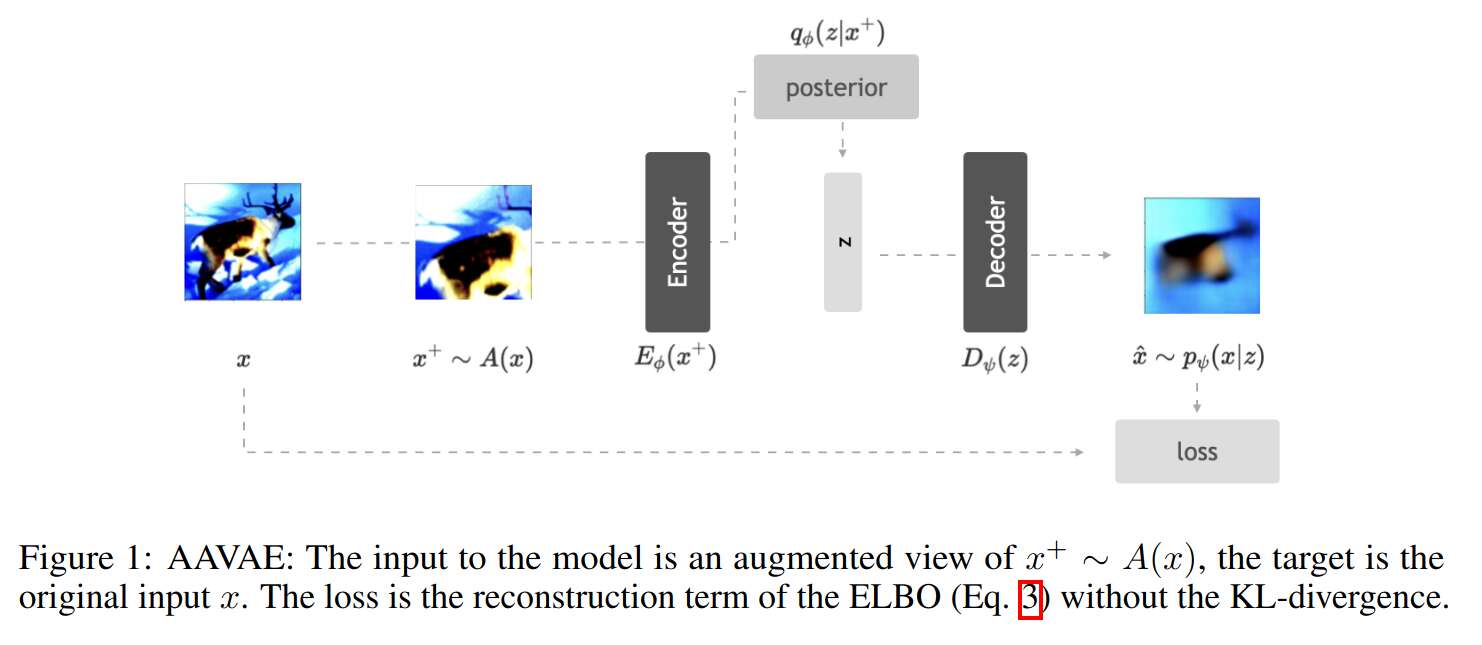
Data
Experiments are done on CIFAR-10 and STL-10. (STL-10 is similar to CIFAR-10, but tailored to unsupervised learning, and its images are 96x96.)
Results
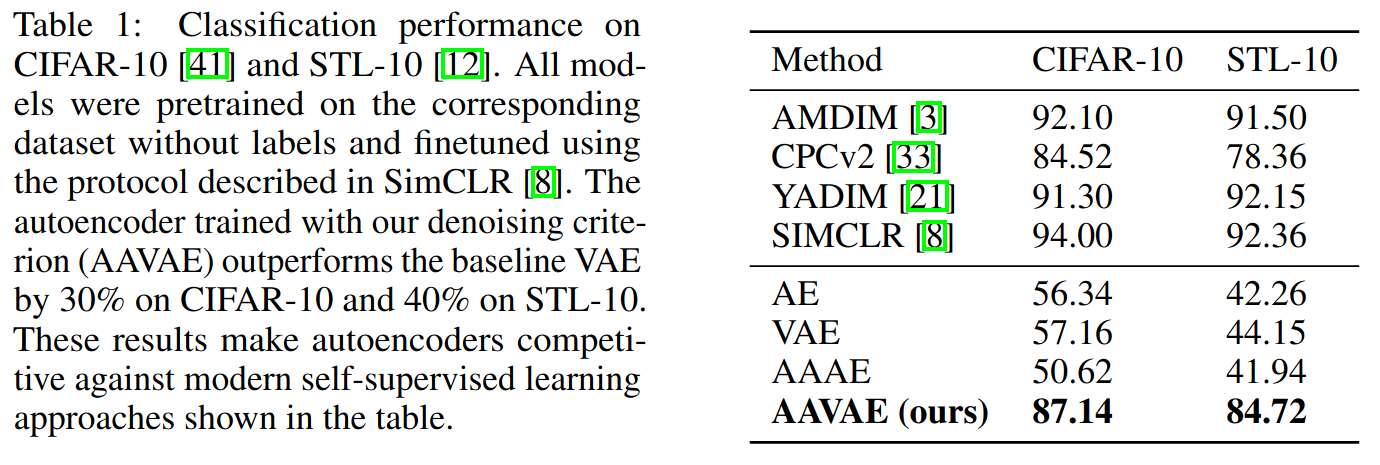
As a measure of the quality of learned representations, a single-layer classifier is trained on these latent vectors and evaluated:
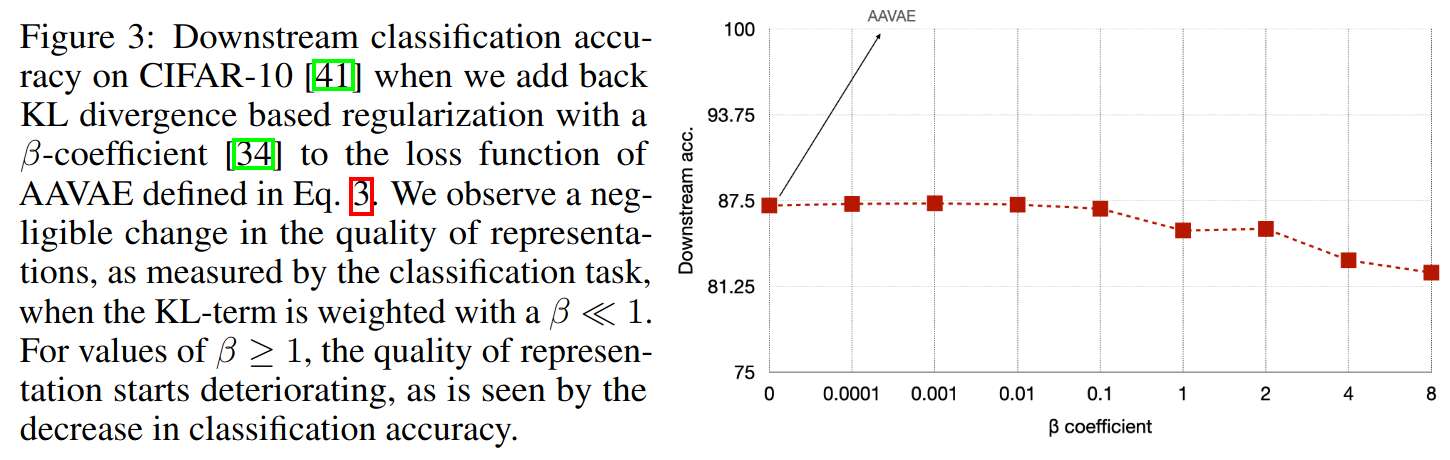
Authors study the importance of the KL term by weighting it by a \(\beta\) coefficient:
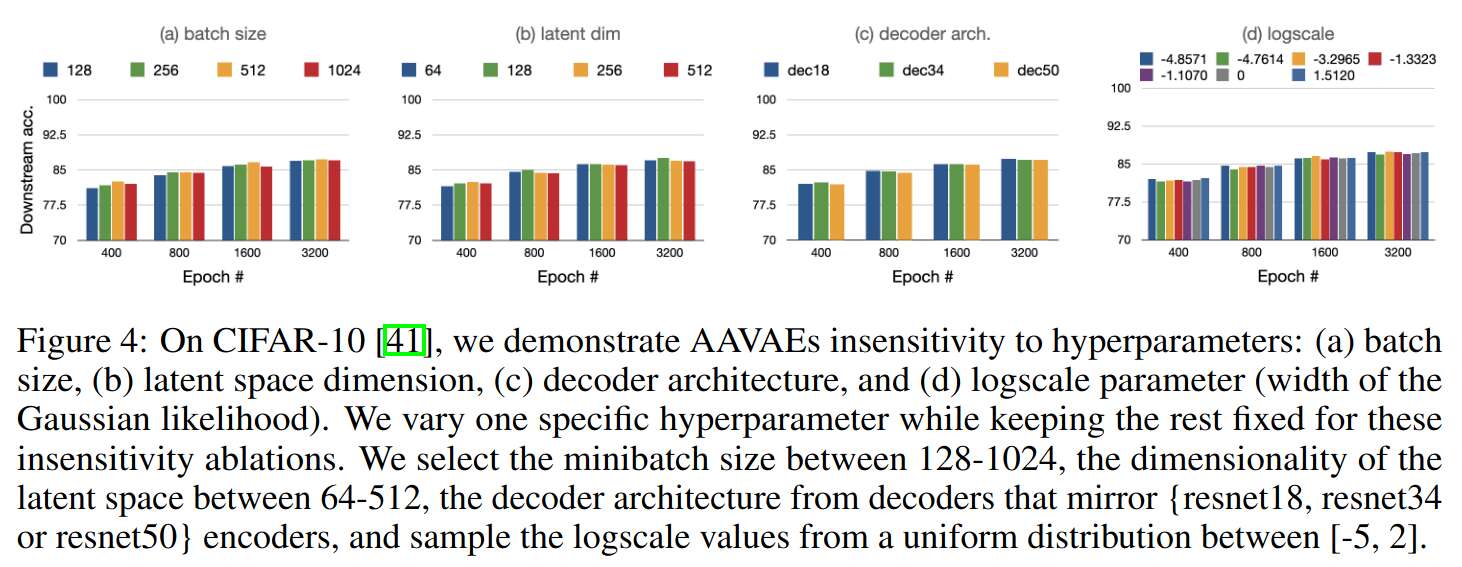
Authors study the sensitivity of AAVAE to hyperparameters:
Authors study the similarity of latent vectors, and find that transformed versions of the same image are more similar than those with a different source; this is not the case for VAE:
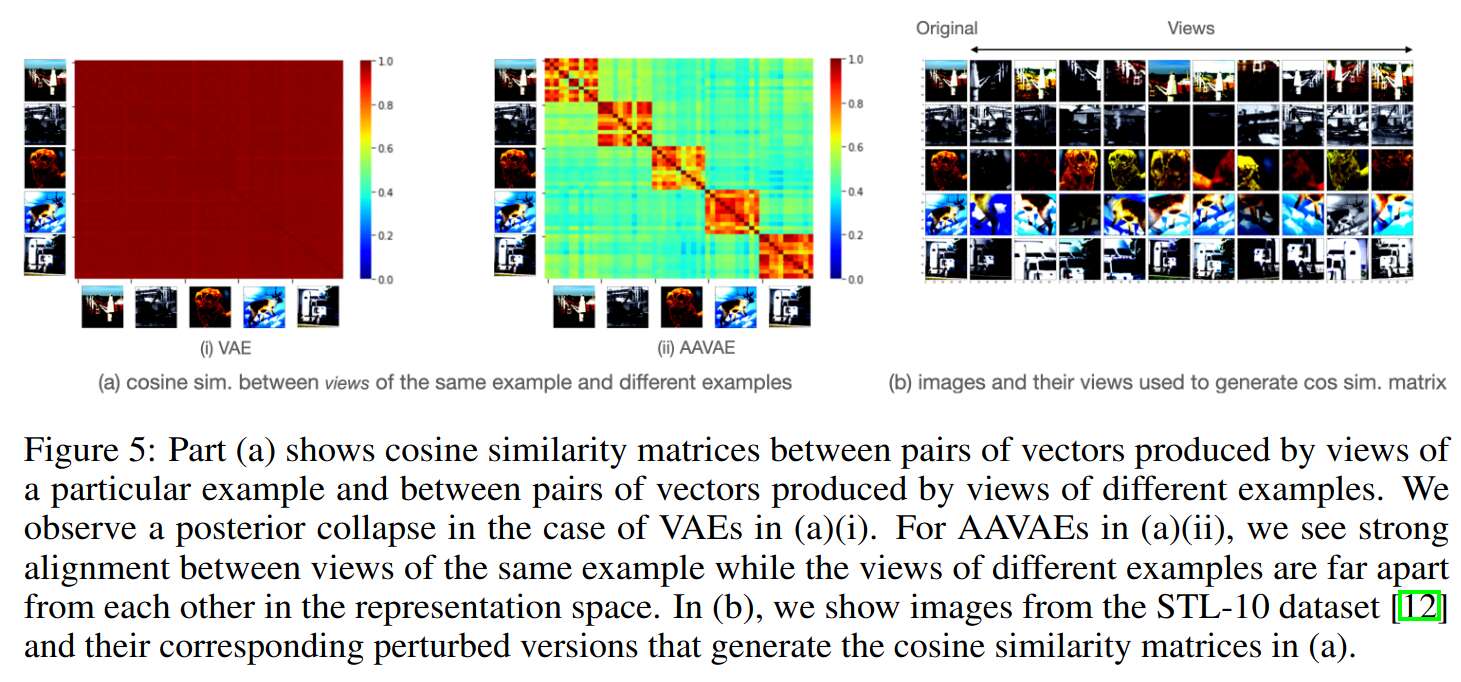
Conclusions
- Data augmentation has been shown to be important in self-supervised learning. KL-divergence based regularization is domain-agnostic, and authors argue it is inadequate for representation learning. These two arguments motivate AAVAE.
- AAVAE is much better than VAE in terms of downstream classification performance. Authors say that this means the representations produced are higher quality.
- AAVAE is less sensitive to hyperparameters.
- AAVAE does not outperform SimCLR in downstream classification. However, it has generative capabilities, which SimCLR does not have.
References
-
Lemaire (2021). ↩