Perceiver: General Perception with Iterative Attention
Highlights
- New architecture that can handle multiple modalities without tailoring the architecture to each
Introduction
Biological systems perceive the world by simultaneously processing high-dimensional inputs from modalities as diverse as vision, audition, touch, proprioception, etc.
Convolutional neural networks have demonstrated tremendous performances on vision tasks, but are virtually useless for other modalities. Transformers, on the other hand, are highly suited for text-based tasks, but scale poorly to vision tasks. Previous architecture focused on multiple modalities often had to make several choices on when and how to merge them.
In this work, the authors introduce the Perceiver architecture, able to leverage arbitrary modalities by iteratively projecting each one to a latent space using attention mechanisms and transformers.
Methods
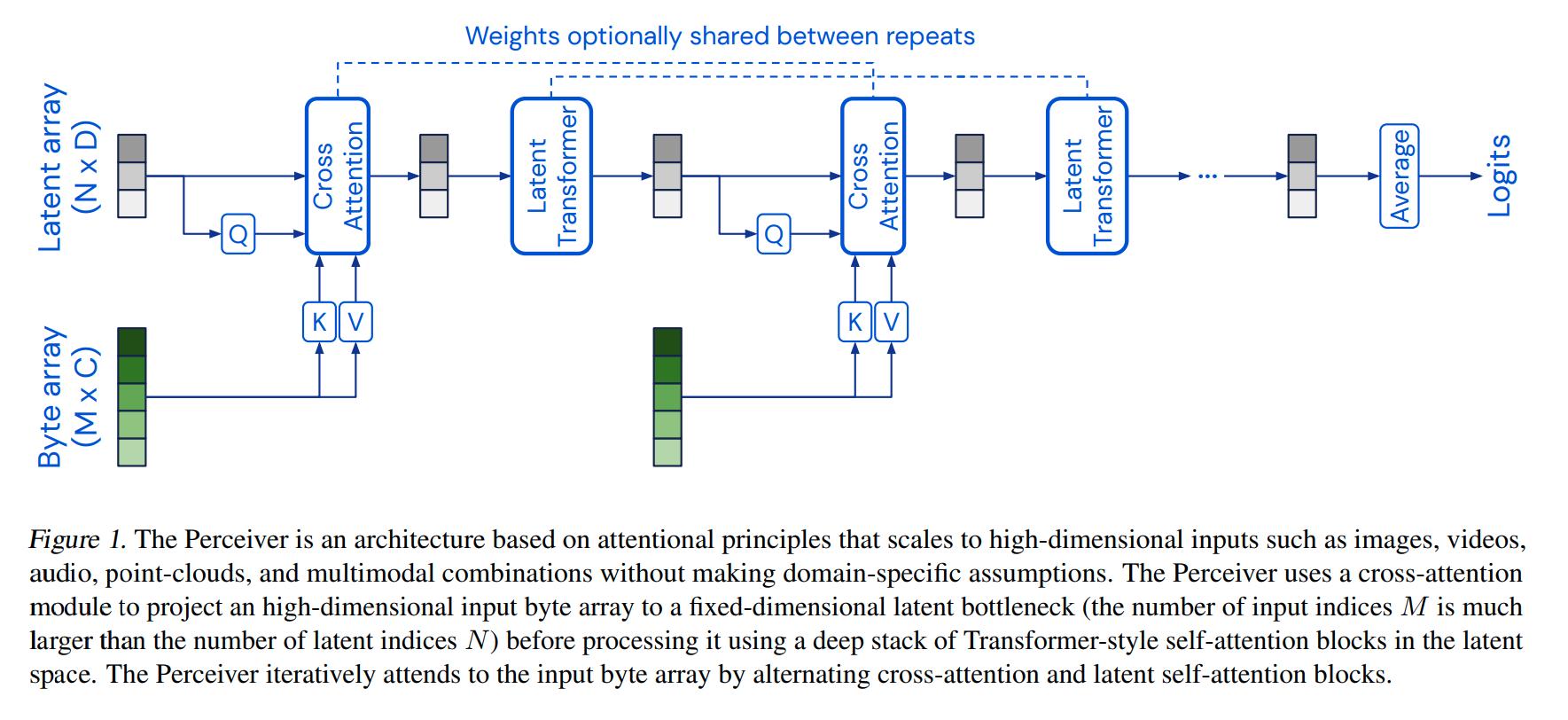
Figure 1. sums up the method. “Byte array” represents arbitrary inputs unrolled as an array. The method iteratively uses two components to tame the input complexity and variety: cross-attention modules and transformers. Each modality is input one after the other. As such, the Perceiver architecture can be seen as an RNN where each input is not a timepoint but a new modality.
Cross-attention is related to self-attention, but the Query (Q) network receives a different input than the Key (K) and Value (V) networks. In this case, Q maps from a latent space and K,V map from the input. This allows the attention mechanism to map an arbitrarily-large input to a much smaller latent space.
Transformers can be used as part of the architecture because their input comes from the small latent space instead of the large input modalities. Their small input size allows for deep transformers. The authors base their latent transformer architecture on GPT-2.
Because attention mechanisms are positionally-invariant, but “spatial relationships are essential for sensory reasoning”, the authors propose to use Fourier feature position encodings. The encodings take the values
\[[\sin(f_{k}{\pi}x_d), \cos(f_{k}{\pi}x_d)],\]where \(f_k\) is the \(k^{\text{th}}\) frequency from a bank of predetermined frequencies and “\(x_d\) is the input position along the \(d^\text{th}\) dimension” \(\in [-1, 1]\).
Data
The authors test their method on ImageNet, AudioSet (audio event classification in video) and ModelNet40 (point clouds).
Results
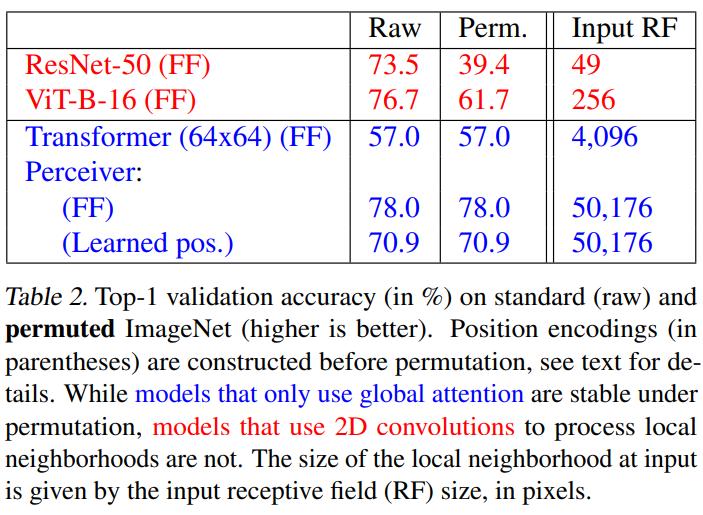
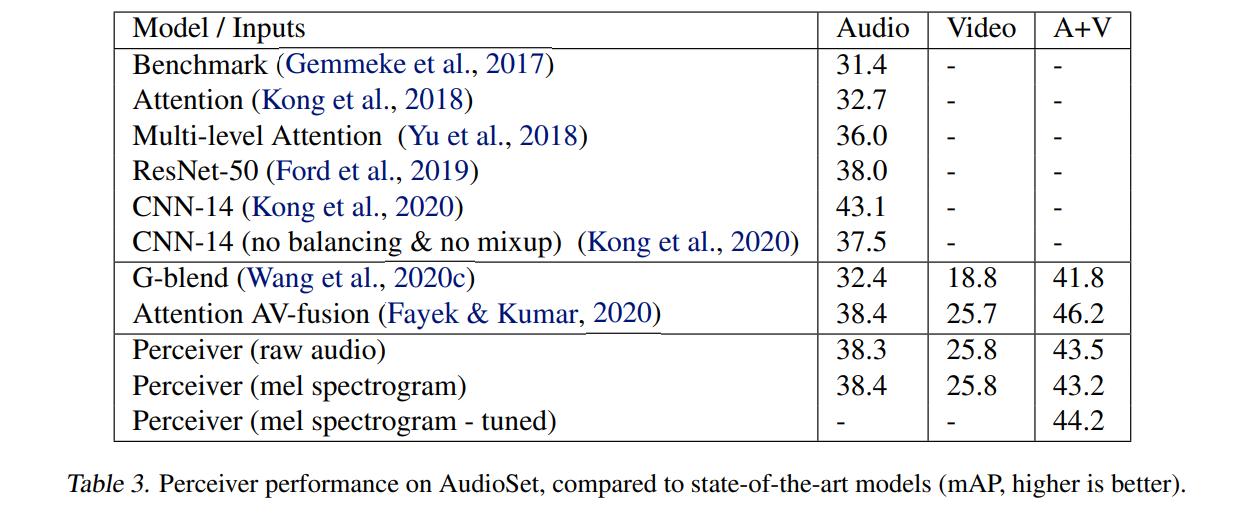
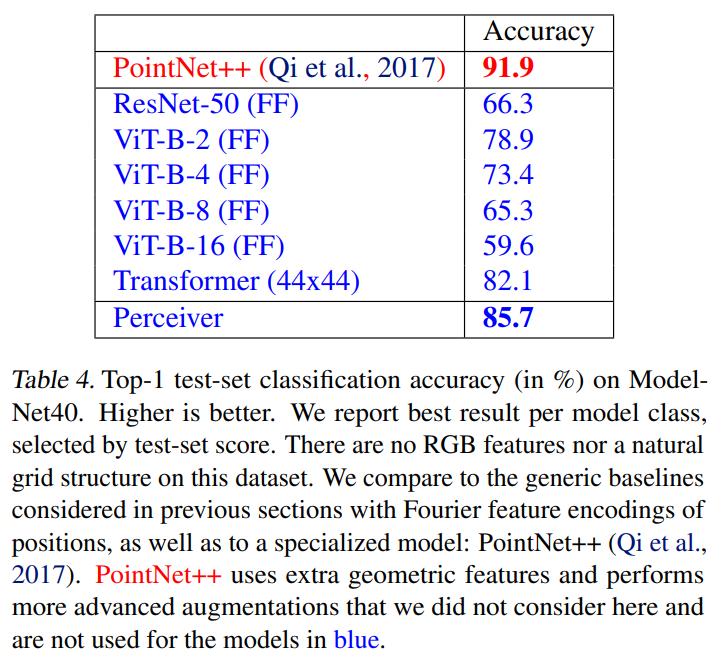
Conclusions
The Perceiver architecture is able to obtain competitive performances without tailoring the architecture to multiple modalities.
Remarks
- Current DL datasets rarely make use of multiple modalities.
- The model was nevertheless tweaked for every experiment (different number of attention layers, transformer blocks, etc.)
- “While we reduced the amount of modality-specific prior knowledge in the model, we still employ modality-specific augmentation and position encoding. End-to-end modality agnostic learning remains an interesting research direction.”