Unadversarial examples: designing objects for robust vision
Highlights
In this paper, the authors assume a setting where the users have access to both the model and the objects they want to detect with the model.
-
The authors develop a method to produce textures and patches for robust detection and classification for vision tasks.
-
The main idea comes by dualizing the notion of adversarial examples. Instead of boosting the wrong label (like adversarial examples) they boost the right label to produce a patch/texture for robust classification.
Introduction
Consider the vision task of detecting a landing pad from a drone, or classifying manufacturing components from a factory robot. In both these tasks, reliable in-distribution performance is a necessity and a number of possible distribution shifts may occur at deployment time.
In these scenarios, the system designer has control over not only the model that is used but also the physical objects that the model operates on.
The authors demonstrate that the designer can use this capability to modify these objects to majorly boost the model’s ability to solve the problem at hand.
-
For the drone example: in addition to training a detection model, we can also paint a landing pad bright yellow. But this choice of painting the landing pad yellow is rather ad hoc, and likely rooted in the way humans recognize objects.
-
An abundance of research has been focusing precisely on that humans and machine learning models tend to use very different sets of features to make their decisions (adversarial examples).
Unadversarial examples
Adversarial examples are small, carefully constructed (by optimization) perturbations to natural images that can induce arbitrary (mis) behaviour from machine learning models. They are constructed by maximizing the loss of a model with respect to the input, that is

The goal of the authors is to modify the design of objects so that they are more easily recognizable by computer vision systems. They instead minimize the loss of the system, that is,
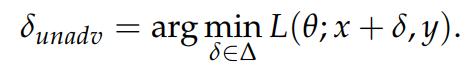
But such access to test inputs is unrealistic. Instead, we have limited control over some physical objects; these objects are in turn captured within image inputs, along with many signals that are out of our control, such as camera artifacts, weather effects, or background scenery.
If we look again at the research on adversarial examples, physical objects can be constructed that act as adversarial examples when introduced into the scene in any one of a variety of ways (adversarial patches, adversarial glasses, etc.).
In this paper, the authors construct physically realizable objects optimized to minimize (rather than maximize like for adversarial examples) the loss of a target classifier.
- To train unadversarial patches, in addition to the pre-trained model, it is required access to image-label pairs from the dataset. At each iteration, we sample a pair \((x,y)\) from the training set, and place the patch corresponding to class \(y\) onto the image with random orientation and position.

- To train unadversarial textures, it is not required access to the dataset, but instead a set of 3D meshes for each class of objects that we would like to augment, as well as a set of background images that we can use to simulate sampling a scene. For each 3D mesh, the goal is to optimize a 2D texture which improves classifier performance when mapped onto the mesh. At each iteration, they sample a mesh and a random background, then they use a 3D renderer to map the corresponding texture into a mesh. They overlay the rendering onto a random background image, and then feed the resulting composed image into the pretrained classifier, with the label being that of the sampled 3D mesh.

Note that rendering is non-differentiable, so they use a linear approximation of the rendering process in order to compute the gradient of the model’s loss with respect to the utilized texture.
Experimental evaluation
Clean data and synthetic corruptions
The authors constructed unadversarial patches of different sizes for pre-trained ResNet-50 on CIFAR10 and ImageNet. For evaluation, they add these patches at random positions, scales and orientations to the validation set images.

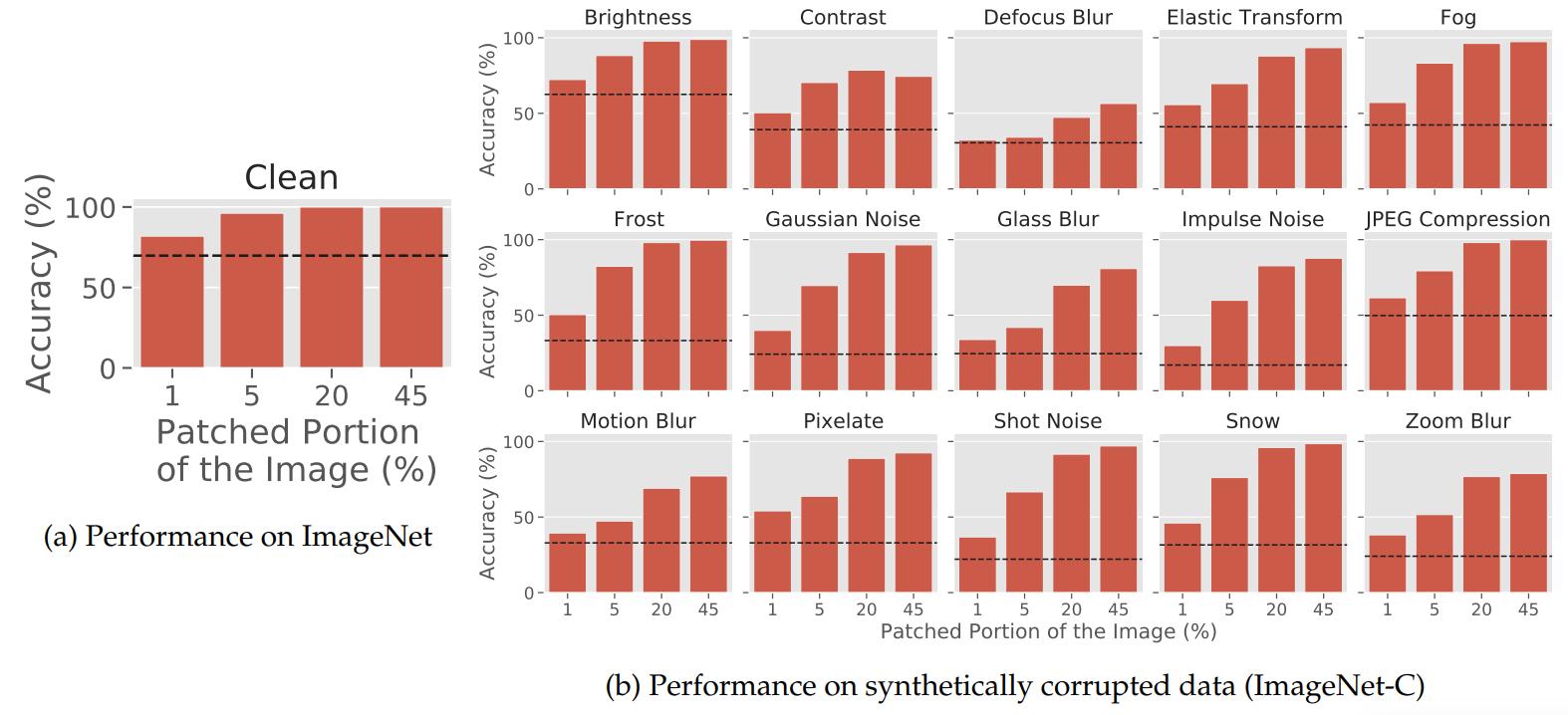

- Baseline They use the minimum loss training image as a patch for baseline. They also compare to QR Codes as patches and random Gaussian noise patches.
Classification in 3D simulation
They collect a set of 3D meshes corresponding to 4 ImageNet classes: warplane, minibus, containership and trailer truck.

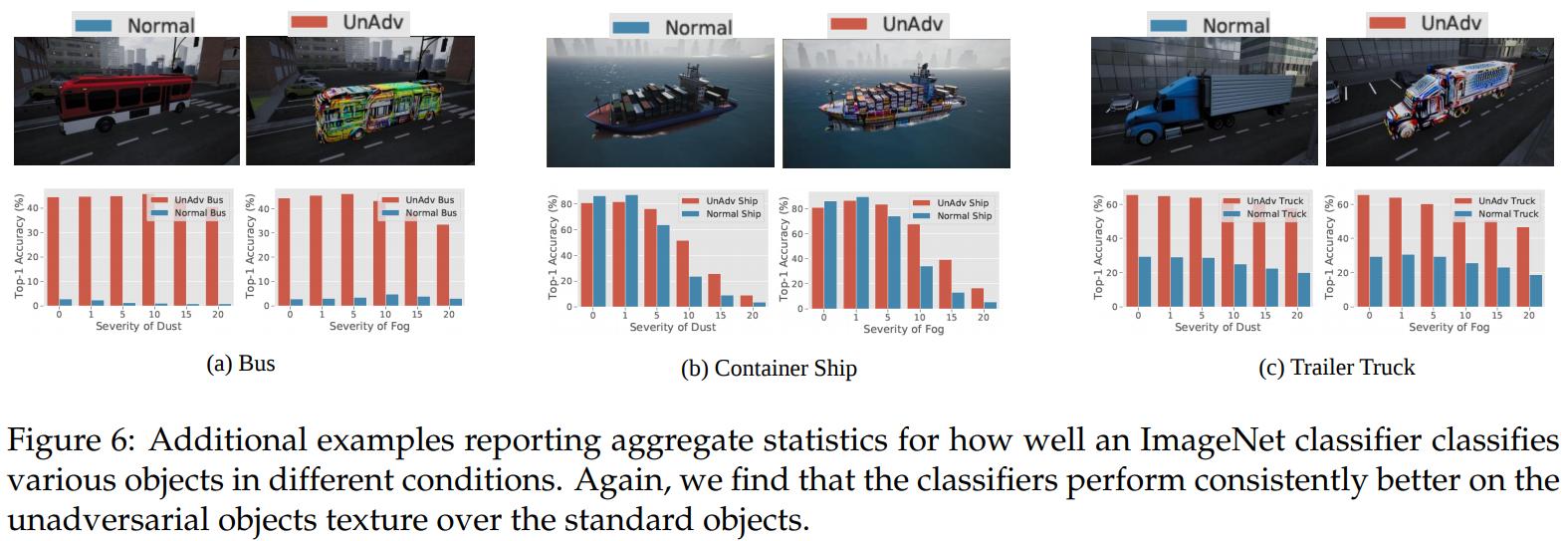
Localization for simulated drone landing

Physical world unadversarial examples

Conclusion
- The idea of adversarial examples can be dualized to boost robustness under strong and unforeseen distribution shifts.
- Unadversarial examples apply to any model that is vulnerable to adversarial examples.
- The method presented requires no modification on the training nor the model.
- The paper has more interesting experiments in the appendix that are worth looking at.