CLIP : Learning Transferable Visual Models From Natural Language Supervision
Highlights
CLIP (Contrastive Language-Image Pre-Training) is a SOTA image/text joint representation learning method trained from scratch on a dataset of 400 million (image, text) pairs downloaded from the internet. CLIP is SOTA on several datasets, in particular when used as a zero-shot learning method. Surprisingly, without having seen a single ImageNet image during training, it outperforms on ImageNet a fully-trained ResNet-50!
Contrastive training
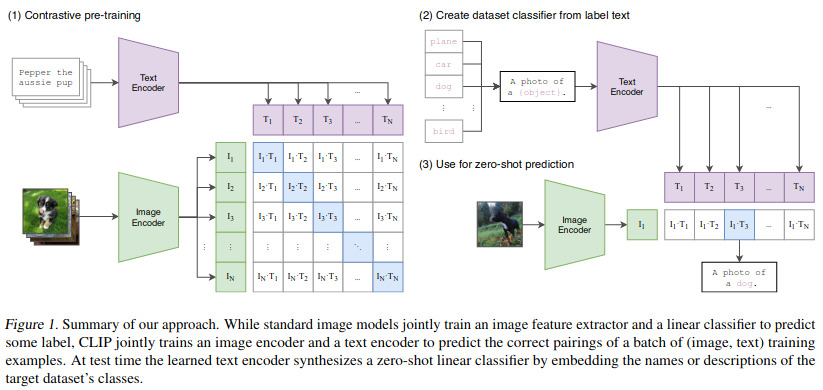
The main idea of the method is fairly easy to understand. As shown in figure 1, the system has a text and an image encoder which are both fed with a batch of N elements : N images for the image encoder and N text descriptions for the text encoder. For each batch, the i-th image fits the i-th description. Following the algorithm of figure 3, the image and text feature vectors of each data are projected to a joint latent space and scaled with a pairwise cosine similarity function. This results into an \(N\times N\) set of (image,text) embedding pairs. Of these pairs, \(N\) are positive pairs and \(N\times N-N\) are negative pairings. The resulting cross entropy loss is a positive-vs-negative contrastive loss.

Test time
At test time, one image is fed to the image encoder while N text sentences are fed to the text encoder. Notice that all sentences is a text prompt such as “A photo of a” which includes the class name (plane, car, dog, etc). The authors advocate that engineering the right prompt is a key to success. For example, in order to disambiguate the word boxer (dog breed vs the sport) the prompt could be “photo of a boxer, an animal” in the case of an animal dataset. At the end, the image is classified according to the sentence whose pairwise cosine similarity is the largest.
Results
The paper contains numerous results obtained with different image encoders (ResNet and Vision Transformer) and a Transformer network as text encoder. From these results, I kept the following three:
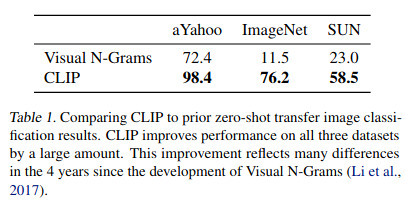
- In Table 1, we get the accuracy of CLIP on 3 datasets compared to Visual N-Grams, a well-known zero-short learning method. Notice the 76,2% accuracy on ImageNet, on par with ResNet trained on that dataset!
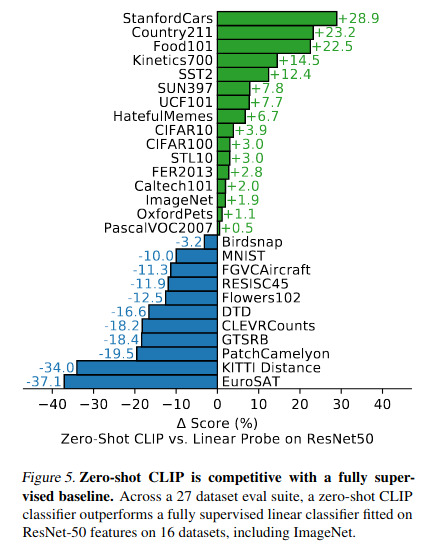
- Figure 5 shows that zero-shot CLIP is very competitive on 27 datasets. Here it is compared with a linear classifier fitted on ResNet-50 features.
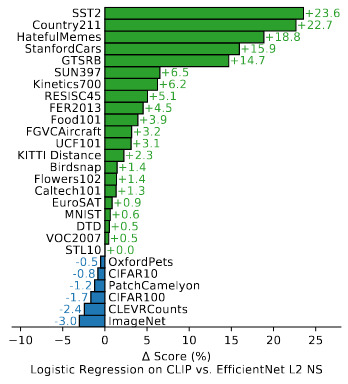
- Figure 11, CLIP feature space is better than that of the best ImageNet pretrained model.