An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
This paper is in review for ICLR 2021: https://openreview.net/forum?id=YicbFdNTTy
Highlights
- The transformer architecture, known for its performance on NLP tasks, is applied to image classification
- The proposed architecture, “ViT” (Vision Transformer) is shown to perform as well or better than CNNs for image classification on large scale datasets
- The usefulness/superiority of the proposed transformer over CNNs only appears when the number of images in the dataset reaches about 100 million
- The proposed architecture brings a reduction of FLOPS of a factor of 2 to train, compared to CNNs, for a given performance
- The authors have used more than 25,000 TPUv3 * days over their experiments
Methods
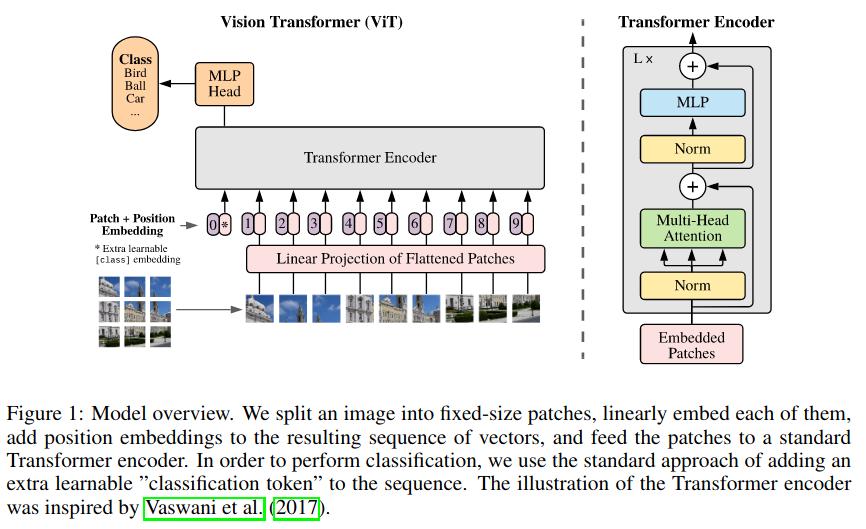
Architecture
- Images are split into patches (16x16 yields the best results)
- The patches are flattened, and become the tokens (or “words”)
- The flattened patches are projected using a MLP
- Each flattened patch is concatenated with a vector which represents the position of the patch. A positional embedding is learned, which maps a one-dimensional patch index to a vector representation.
- Note that this allows the very first layer to attend to any part of the image, in comparison with CNNs for which the receptive field develops over many layers.
- The first token is a dummy, and is only there because the feature vector of the image will appear at that position at the last layer of the network.
Experiment design
- The models are pre-trained on either ImageNet (1k classes, 1.3M images), ImageNet-21k (21k classes, 14M images) or JFT (18k classes, 303M images).
- The models are then fined-tuned on one of the datasets listed in the “Benchmarking datasets” section below.
- Sometimes, the model is not fine tuned, but is evaluated in a few-shot regime. This is not well described in the paper: “Few-shot accuracies are obtained by solving a regularized linear regression problem that maps the (frozen) representation of a subset of training images to \(\{−1,1\}^K\) target vectors. Though we mainly focus on fine-tuning performance, we sometimes use linear few-shot accuracies for fast on-the-fly evaluation where fine-tuning would be too costly.”
- They also have tried self-supervised pre-training, in which the model predicts masked patches. This is given little importance, and the results are “only” promising, so I will not write about this further.
Benchmarking datasets
The experiments have been run on a number of datasets of image classification:
- ImageNet
- ImageNet ReaL (“Reassessed Labels”, from Beyer et al. 2020) Code
- CIFAR10/100
- Oxford Pets, Oxford Flowers
- VTAB (Zhai et al., 2019b) (“VTAB evaluates low-data transfer using 1 000 examples to diverse tasks. The tasks are divided into three groups: Natural– tasks like the above, Pets, CIFAR, etc. Specialized– medical and satellite imagery, and Structured– tasks that require geometric understanding like localization.”) Blog post
Results
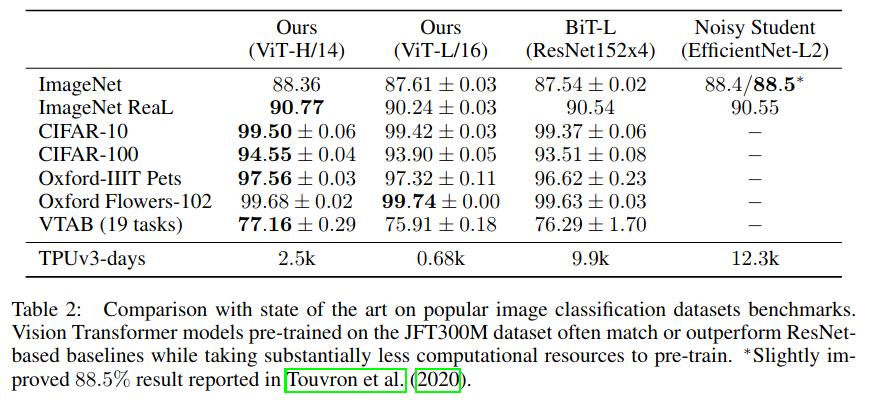
As seen in the table below, ViT performs slightly better than a very large ResNet, and does so using significantly less FLOPS (for the fine-tuning phase).
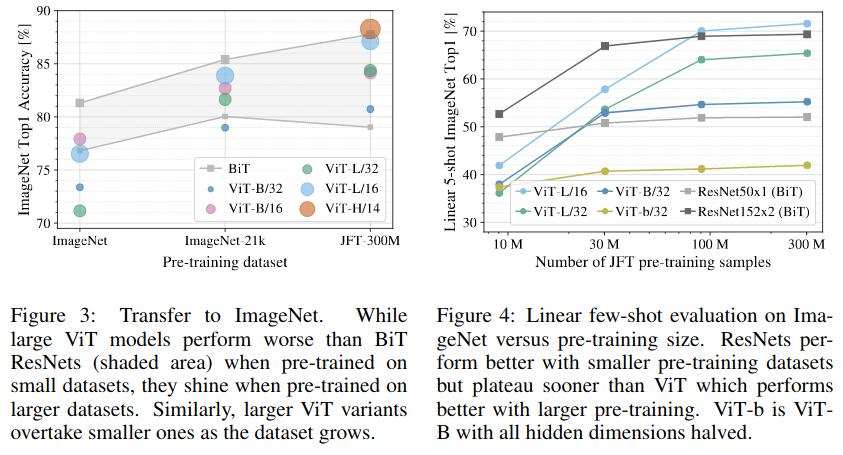
However, the pre-training has to involve a very large number of training samples: when this number exceeds 100 million, ViT starts to shine. Else, the ResNet performs better. See below:
ViT also compares favourably in terms of pre-training FLOPS, as seen below:
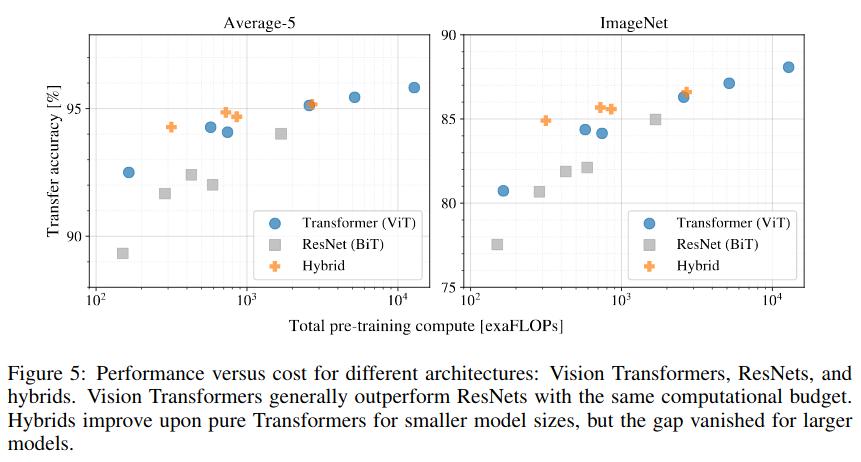
The “Hybrid” approach uses CNN feature vectors as tokens; it is not considered very important by the authors.
The figures below serve to inspect the vision transformer architecture:
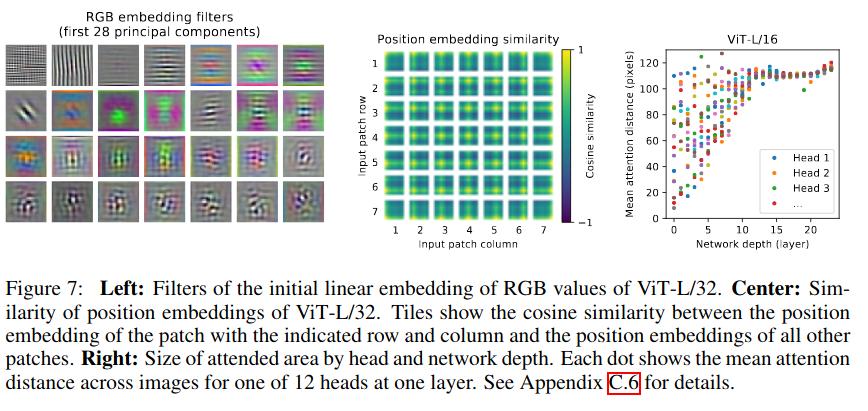
Conclusions
The Vision Transformer is an architecture that can outperform CNNs given datasets in the 100M-image range. It required less FLOPS to train than the CNNs used in this paper.
Remarks
- This video is a good commentary on the paper. It offers this interpretation: the transformer is a general architecture, with less priors than a CNN. It can learn the spatial structure of the problem, and a CNN cannot.