Accelerating Online Reinforcement Learning with Offline Datasets
Highlights
- Reinforcement Learning (RL) method for training an agent using offline data then finetuning it online
Introduction
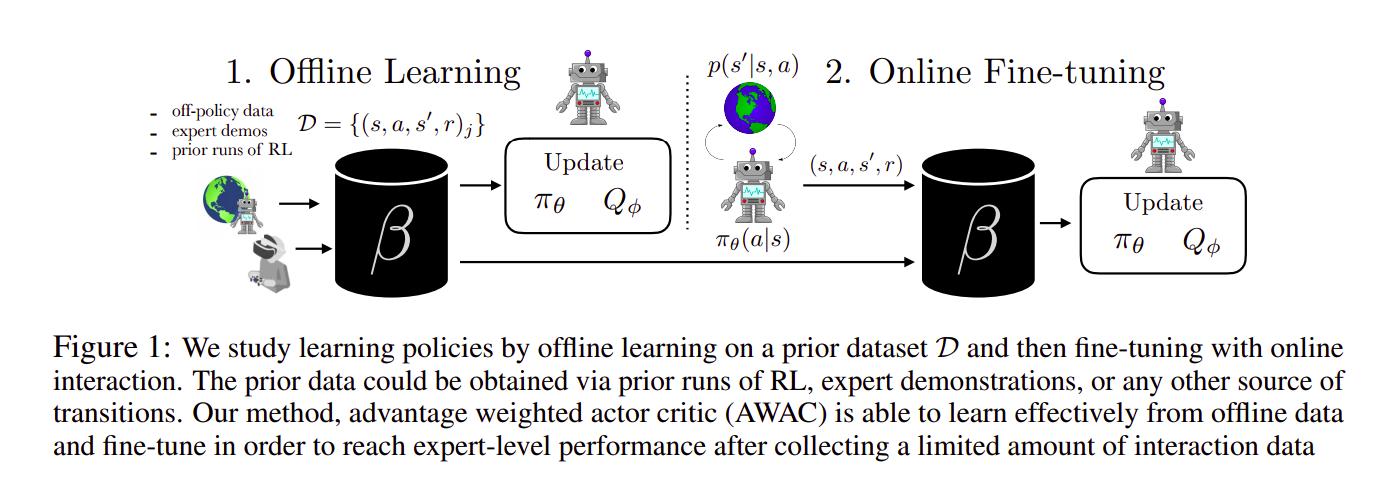
Online vs. offline training refers to having access or not to the environment and being able to sample trajectories from it. Offline training for RL agents allows them to learn, through imitation learning in the simplest case, from static datasets, which is usually much more data-efficient and might be your only possibility in cases of high-risk environments (such as autonomous driving).
Learning entirely offline, however, might not produce the optimal policy as the data in the dataset might come from sub-optimal policies. Finetuning agents with online training after they were trained offline might be a way to counter this problem.
Problems with finetuning offline-trained agents
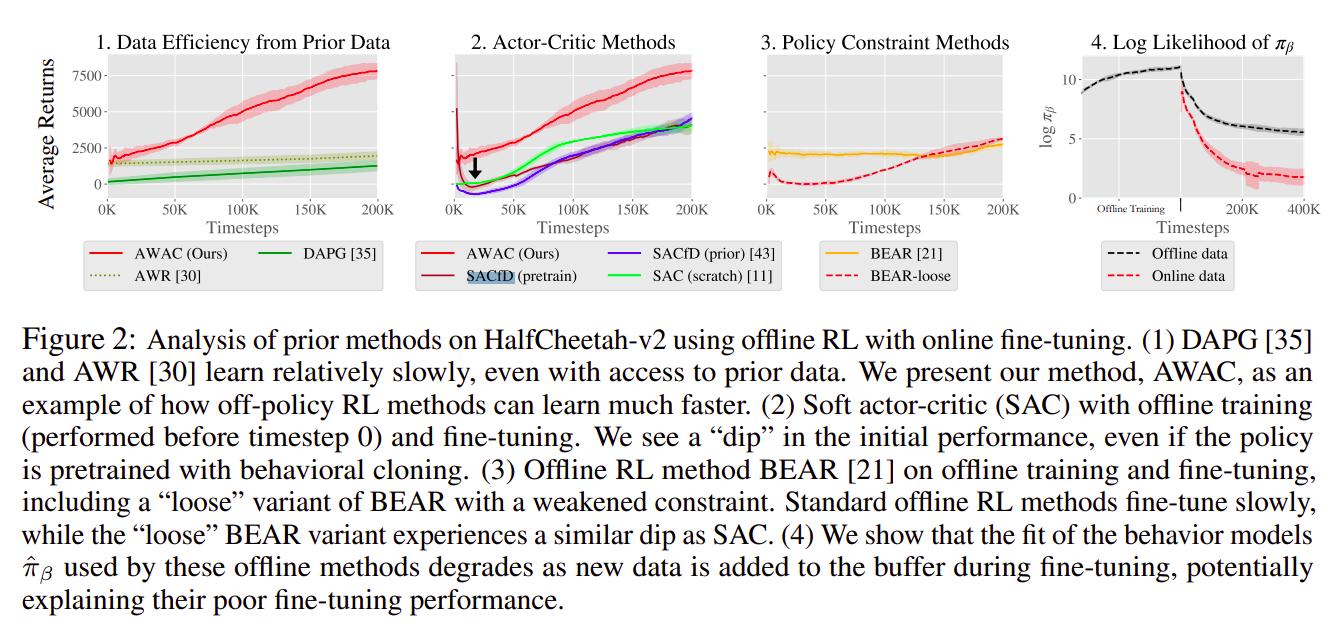
Fig. 2 describes well the problems associated with finetuning agents online, but let’s go into a bit more details
Data efficiency
Naively training offline then finetuning online is wasteful if the data acquired offline cannot be reused once offline training is over. Methods like AWR1 and others are guilty of this, and they also learn very slowly during the finetuning state, as shown in Fig. 2 plot 1.
Boostrapping errors in offline learning with actor-critic methods
As discussed in the BEAR paper2, bootstrapping errors occur when the learnt Q-function produces wild values for out-of-distribution actions. This causes agents to experience a decrease in performance as finetuning goes on, as the Q-function has to re-learn the correct values for the actions. This is shown in Fig. 2 plot 2.
Offline algorithms cannot learn online
Purely offline algorithms (like BEAR2) perform very well in the offline setting but struggle to show any improvements when trained online as shown in Fig. 2 plot 3. The authors argue it is because they try to learn the behavior policy distribution \(\beta\), which is stable when offline but becomes unstable online as new samples appear in the dataset.
Methods
The authors propose to use the following actor update
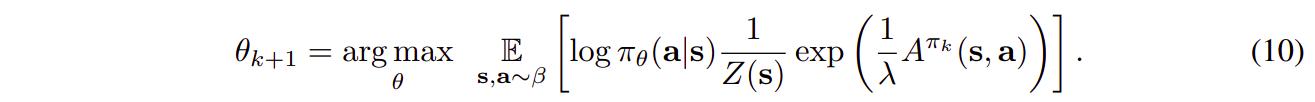
which they argue amounts to simple weighted maximum likelihood regression (derivation details are available). \(Z\) is a partition function that is in practice ignored and \(\lambda\) a Lagrange multiplier set between 0.3 and 1.
The complete algorithm is available below

where Eq. 3 is simply the Bellman error minimization.
Data
The authors tested their method on dexterous manipulations, tabletop manipulations and MuJoCo control tasks.
Results
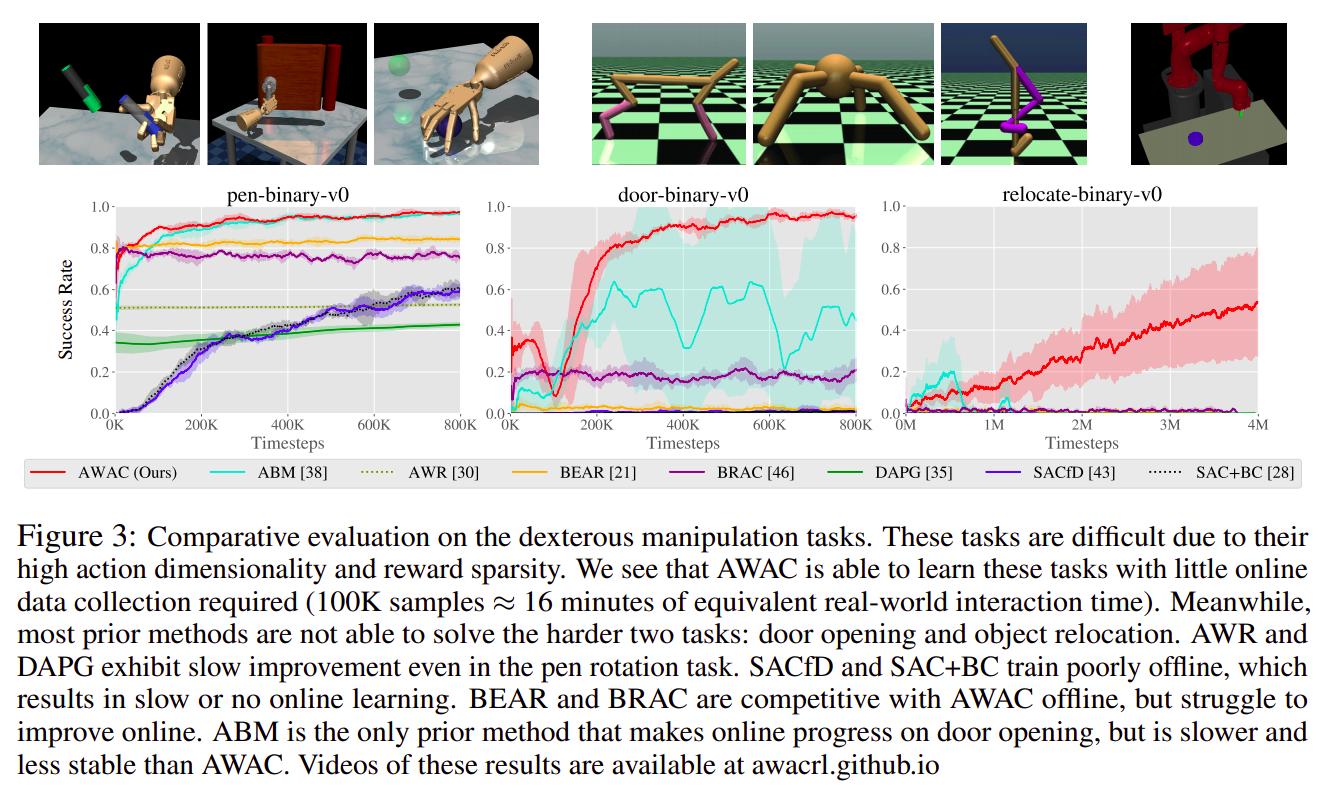
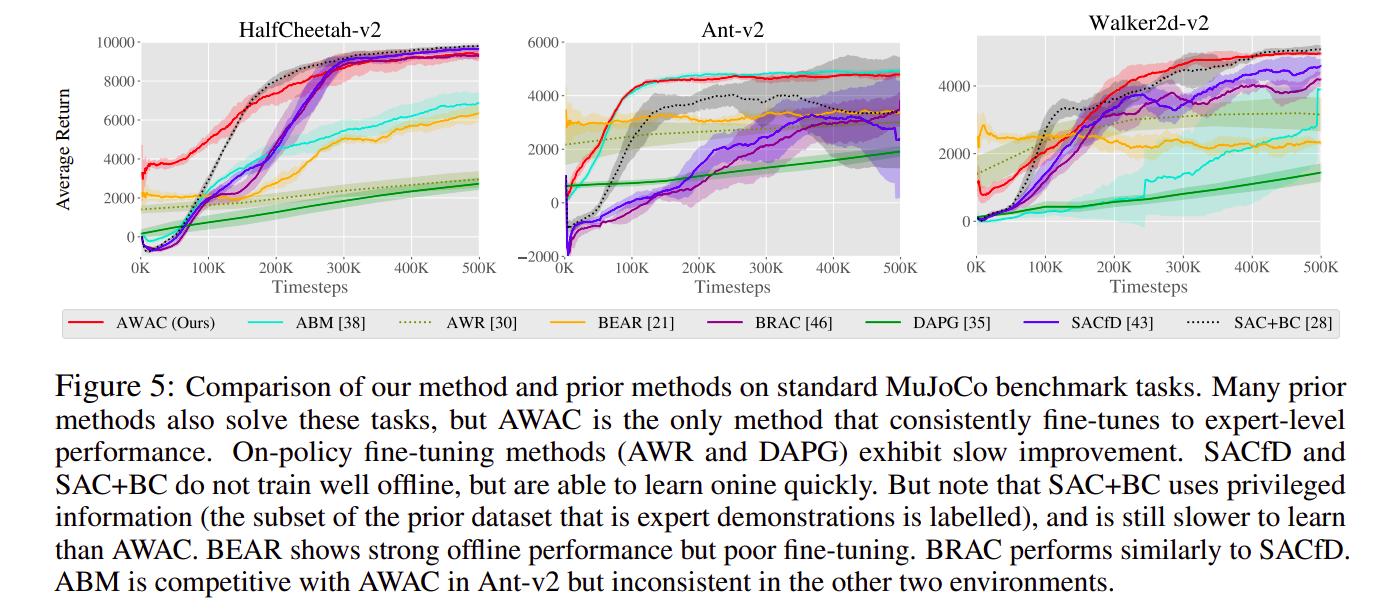
Conclusions
The key insight in AWAC is that enforcing a policy update constraint implicitly on actor-critic methods results in a stable learning algorithm amenable for off-policy learning. With an informative action-value estimate, the policy is weighted towards high-advantage actions in the data, resulting in policy improvement without conservative updates.
Remarks
- The paper is still in preprint and has a couple of formatting issues, but otherwise is a very good read and is thorough.