Representational drift in Recurrent Reinforcement Learning
Highlights
- Off-policy RL can suffer from representational drift when using RNNs
- A burn in period can help alleviate the problem
Training recurrent RL agents with experience replay
Reinforcement Learning (RL) has seen a rejuvenation of research interest recently due to repeated successes in solving challenging problems such as reaching human-level play on Atari 2600 games (Mnih et al., 2015), beating the world champion in the game of Go (Silver et al., 2017), and playing competitive 5-player DOTA (OpenAI, 2018b). The earliest of these successes leveraged experience replay for data efficiency and stacked a fixed number of consecutive frames to overcome the partial observability in Atari 2600 games. However, with progress towards increasingly difficult, partially observable domains, the need for more advanced memory-based representations increases, necessitating more principled solutions such as recurrent neural networks (RNNs).
The Deep Q-Network agent that made the news in 2015 used 4-frame stacking to represent its input for a feed-forward neural network (NN). The A3C algorithm, which is on-policy, has been adapted to use an LSTM, but trains directly on acquired trajectories and does not store any transitions.
Off-policy reinforcement learning allows the agent to store past transitions in a buffer with no regards to which policy acquired the transition. With a RNN, the hidden state of the network also becomes part of the network’s input and has to be stored as well in the replay buffer. To train a RNN on replayed experiences, two strategies are available:
- Zero-ing out the hidden state at associated with the transitions
- Storing the hidden state associated with the transitions
- Replaying whole episode trajectories
The first strategy is very simple but prevents the network from using the temporal information that it had when sampling the transition. The second strategy might suffer from representational drift, where the hidden state produced by the network might no longer correspond to the hidden state stored in the replay buffer. The third strategy creates a number of practical and computational issues and is generally not considered.
To alleviate the problems with option one and two, the authors propose to train on fixed-size episode chunks and allow the network a burn in period before the training begins by unrolling the network on part of the sampled episode chunk and training on the rest, allowing the network to produce it’s own meaningful hidden state.
Methods
To measure recurrent state staleness and representational drift, the authors measured the difference in Q values produced by the network when fed the stored hidden state versus it’s own, called Q-value discrepancy:
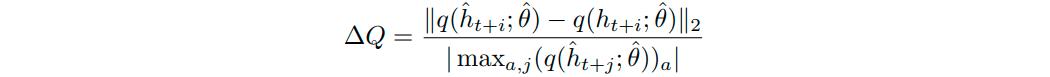
Results
Conclusions
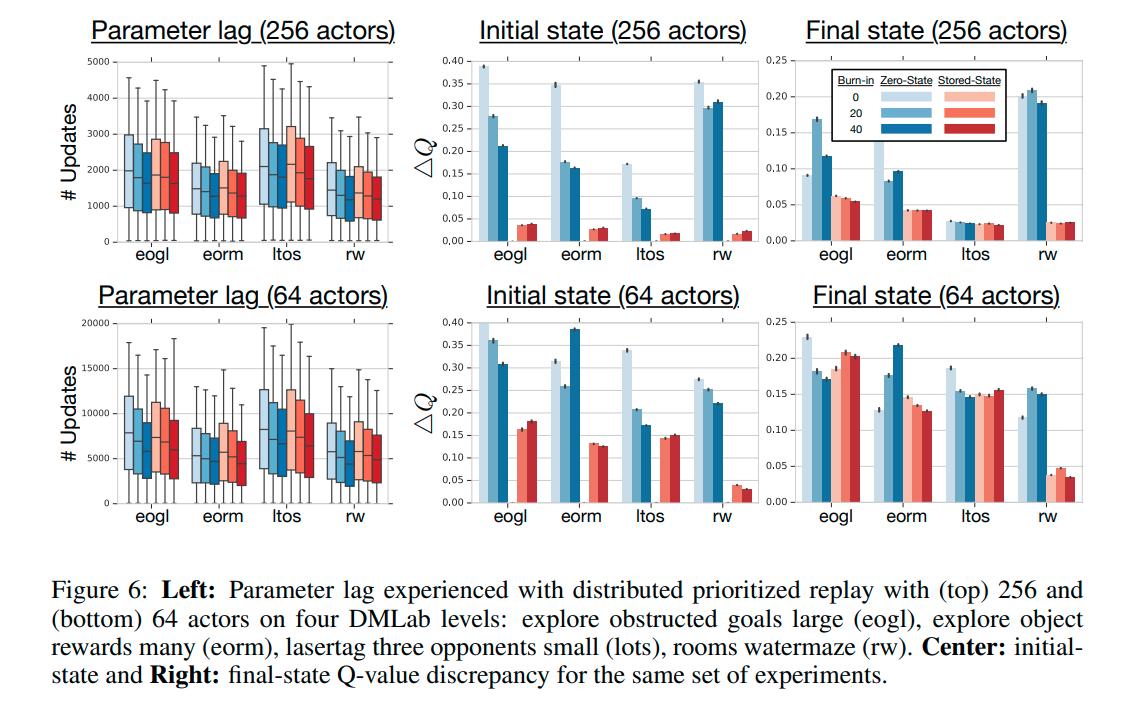
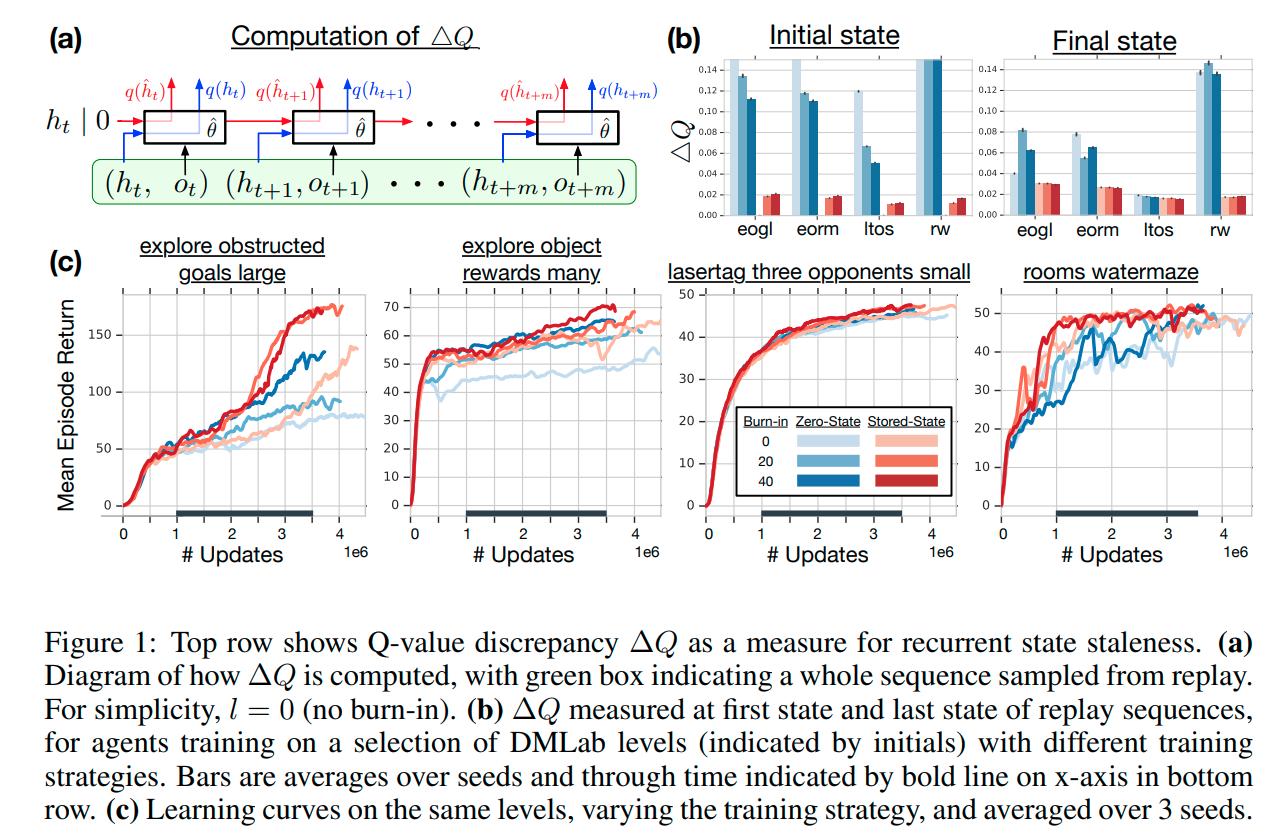
- It can be seen that the zero start state heuristic results in a significantly more severe effect of recurrent state staleness on the outputs of the network, and the effect is less present at the last state since the network had time to recover from the unusual start state.
- The burn in period does not seem to help with Q-value discrepancy but does help with the final reward achieved
- Storing the state is an overall better strategy than zeroing the state
Remarks
- Storing fixed-length episode chunks instead of single transitions also has its own share of computational and practical issues.
- The paper also presented a distributed reinforcement learning agent called R2D2 but I thought that part was less interesting. One thing to note is that, in the context of a distributed RL algorithm, having more actors did seem to also help with the problem of Q-value discrepancy