Implementation Matters in Deep RL: A Case Study on PPO and TRPO
Highlights
- Much of the performance of PPO over TRPO comes from code-level optimization and not the original paper’s main selling points
- PPO code-optimizations are significantly more important in terms of final reward achieved than the choice of general training algorithm (TRPO vs. PPO)
Introduction
Deep reinforcement learning (RL) algorithms have fueled many of the most publicized achievements in modern machine learning. However, despite these accomplishments, deep RL methods still are not nearly as reliable as their (deep) supervised counterparts. Indeed, recent research found the existing deep RL methods to be brittle, hard to reproduce, unreliable across runs and sometimes outperformed by simple baselines. The prevalence of these issues points to a broader problem: we do not understand how the parts comprising deep RL algorithms impact agent training, either separately or as a whole. This unsatisfactory understanding suggests that we should re-evaluate the inner workings of our algorithms. Indeed, the overall question motivating our work is: how do the multitude of mechanisms used in deep RL training algorithms impact agent behavior ?
The authors focused their work on PPO, the current state of the art (SotA) algorithm in Deep RL (at least in continuous problems). PPO is based on Trust Region Policy Optimization (TRPO), an algorithm that constrains the KL divergence between successive policies on the optimization trajectory by using the following update rule:
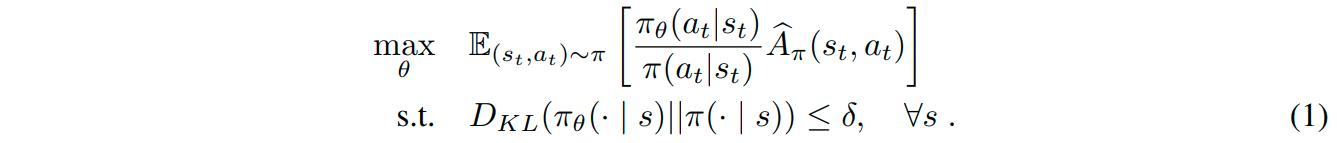
The need for trust regions come from the fact that update steps computed at any specific policy \(\pi_{\theta_t}\) are only guaranteed predictiveness in a neighborhood around \(\theta_t\)
However, TRPO is computationally expensive, requiring the computation of multiple Hessian-vector products. To address this issue, PPO was proposed and approximates the KL-constrained objective of TRPO by clipping the objective function:
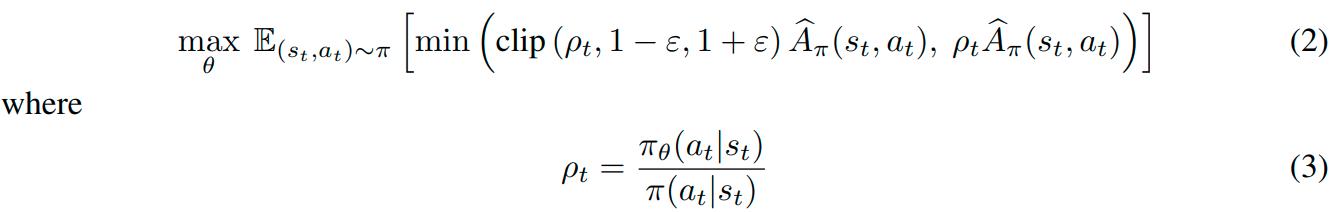
Code-level optimizations have algorithmic effects
The authors found that the standard implementation of PPO1 contains many code-level optimizations barely-to-not described in the original paper.
- Value function clipping, where the Value Function update is clipped in the same way as the policy update
- Reward scaling, where the rewards are divided through by the standard deviation of a rolling discounted sum of the rewards
- Orthogonal initialization and layer scaling: The implementation uses an orthogonal initialization scheme with scaling that varies from layer to layer instead of the default weight initialization.
- Adam learning rate annealing: the implementation sometimes anneals the learning rate of Adam.
- Reward clipping: The implementation also clips the rewards within a preset range.
- Observation normalization: The states are normalized to mean-zero variance-one vectors.
- Observation clipping: The states are also clipped within a range
- Hyperbolic tan activation: Hyperbolic tangent function activations are used between layers in the policy and value networks.
- Global Gradient Clipping: After computing the gradient with respect to the policy and the value networks, the implementation clips the gradients such the “global \(l_2\) norm does not exceed 0.5
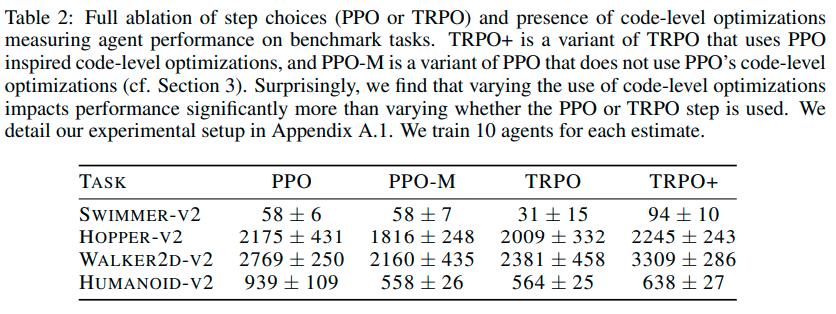
Due to computational resources restrictions, the authors could only perform ablation studies on the first four optimizations. They also implemented PPO-Minimal (PPO-M), which has none of the above optimizations.
Here is a summary of the algorithms implemented

With TRPO+ being TRPO with the above code-level implementations
Data
The tests were performed on Mujoco Tasks such as Hopper and Humanoid.
Results
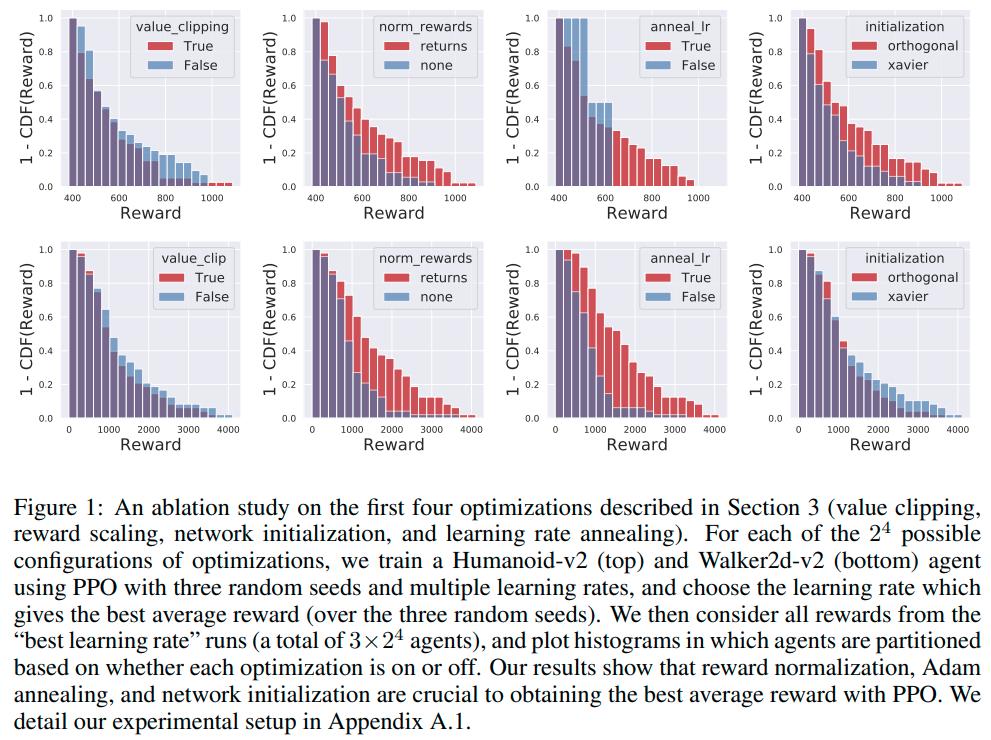
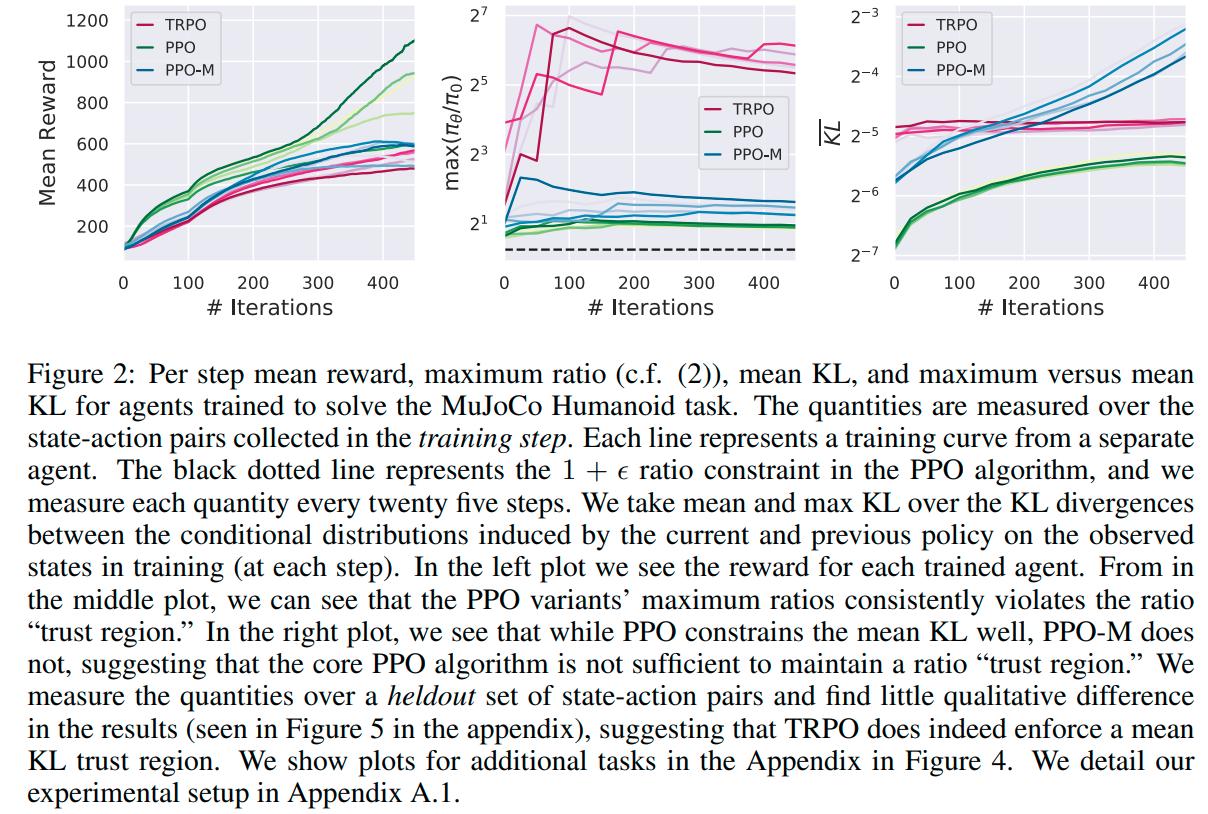
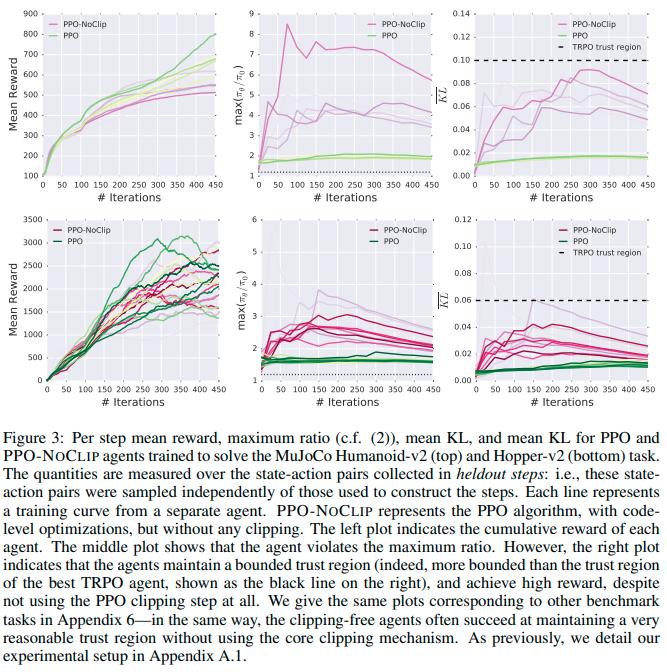
Conclusions
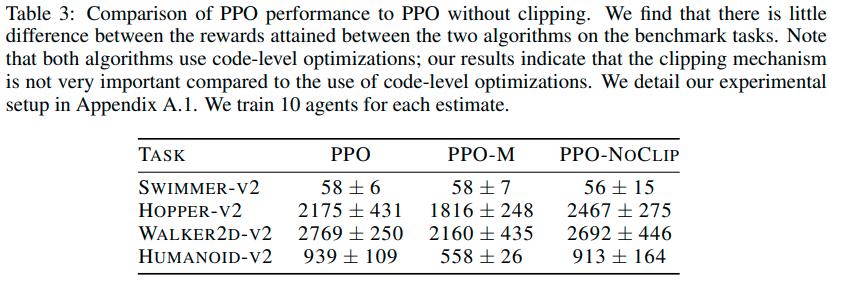
From the above results we can see that
- Code level optimization are necessary to get good results with PPO
- PPO without optimizations fails to maintain a good trust region
- PPO without clipping can still maintain a reasonable trust region and can achieve similar results to PPO with clipping
- The success of PPO over TRPO could come from code-level optimizations and not the objective clipping
Overall, our results highlight the necessity of designing deep RL methods in a modular manner. When building algorithms, we should understand precisely how each component impacts agent training—both in terms of overall performance and underlying algorithmic behavior. It is impossible to properly attribute successes and failures in the complicated systems that make up deep RL methods without such diligence.
Remarks
The paper got accepted for a talk at ICLR 2020
References
-
From the OpenAI baselines GitHub repository: https://github.com/openai/baselines ↩