Single Headed Attention RNN: Stop Thinking With Your Head
Highlights
- Simple RNN architecture provides (almost) state of the art results
- “Tokenization attacks” make comparing results difficult
Preface
The currently reviewed article requires a very good understanding of NLP, attention and the transformer module. These two articles (1. 2.) provide a good summary of these concepts.
Introduction
State of the art (SotA) NLP architectures are massive and require enormous resources to train, which makes meaningful research hard to do for smaller research teams. The author painfully introduces their own NLP architecture, based on a previous paper of his[^1] called SHA-RNN.
Methods
BERT<[^2], the current SotA architecture for NLP problems uses transformers and multi-headed attention modules to prevent the usage of RNN, which makes it more more stable during training and removes temporal dependencies between words. It does, also, add a lot of parameters to the model because the RNN is replaced with a (much bigger) feed-forward (FF) network.
The author decided instead keep using RNNs, namely a single layer LSTM module with a single head of attention and a “Boom” module, apparently similar to a Transformer module. The architecture is pictured below:
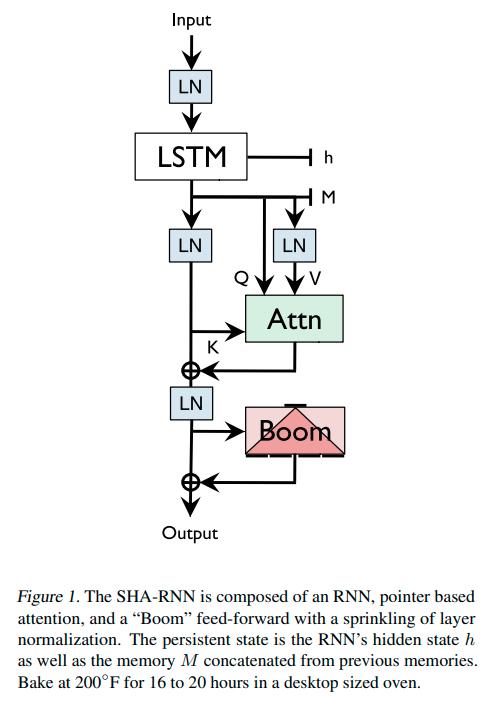
Note that ‘LN’, ‘M’ and the ‘plus’ operator are never explained.
The author also mentions he simplified the attention module, with its architecture pictured below:
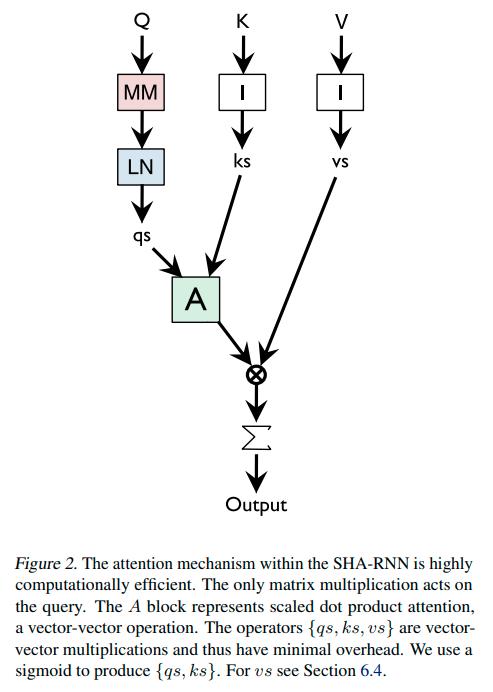
Note that ‘MM’, ‘I’ and the ‘cross’ operator are not defined.
The ‘Boom’ Layer is ‘explained’ in this paragraph:

Note that ‘H’, ‘N’ are never explained.
Data
The model was tested on three datasets, enwiki8, WikiText-2 and WikiText-3, the last two also introduced in a previous paper by the author.
Results
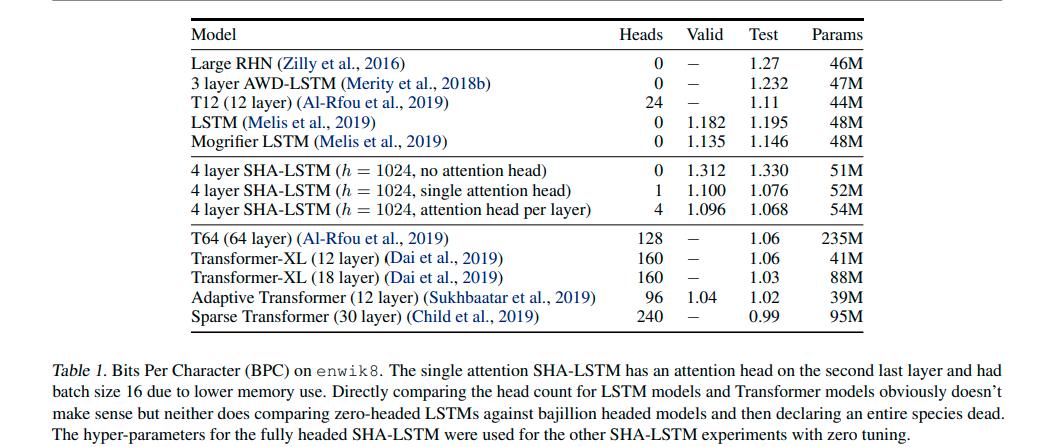
For BPC, lower is better.
Tokenization attacks
All NLP models use tokenization to simplify their input, which makes sense because you don’t want to have your softmax classifier to give a probability for every word in the dictionary and more. Therefore, tokenization algorithms will break words into, usually, prefixes and suffixes, common letter grouping, etc. Any good tokenizer will give you the option of breaking your dictionary into the amount of token that you want, and an extreme example would be to have your dataset broken into tokens representing the ASCII table.
However, the author mentions that breaking your dataset into fewer tokens actually makes things easier. Indeed, while training your model, you have much more feedback if you apply the loss and do teacher forcing on a letter-per-letter case instead of a word-per-word case. The author does not provide any experiment results backing up these claims.
Conclusions
The author mentions ‘alternative research history’ and fighting the direction of research and provides valid points that sometimes, following the research “trends” might hinder research and be harmful for researchers, such as using massive models. The author successfully used a smaller model to reach SotA results and introduced the concept of “tokenization attacks”
Remarks
- The paper is written in a very “humorous way” which makes gather useful information really hard.
- It might be because I don’t follow NLP news too much but a lot of concepts and important aspects of the architecture were not explained
- The “SotA” results are not really state of the art
- The paper would have served a better purpose as a blog post
References
[^1] Stephen Merity, Nitish Shirish Keskar: “Regularizing and Optimizing LSTM Language Models”, 2017; http://arxiv.org/abs/1708.02182 arXiv:1708.02182.
[^2] Jacob Devlin, Ming-Wei Chang, Kenton Lee: “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”, 2018; http://arxiv.org/abs/1810.04805 arXiv:1810.04805.
Code: https://github.com/Smerity/sha-rnn
Discussion on HN: https://news.ycombinator.com/item?id=21647804
Discussion on reddit.com/r/MachineLearning: https://www.reddit.com/r/MachineLearning/comments/e2ch4t/r_single_headed_attention_rnn_stop_thinking_with/