ETNet - Error Transition Network for Arbitrary Style Transfer
Code available Here
Highlights
- The paper introduces the concept of error-correction mechanism to style-transfer by evaluating errors in stylization results and correcting them iteratively.
- Computing the features for perceptual loss in a feed-forward network, each refinement is formulated as an error diffusion process.
- The overall pyramid-based style transfer framework for style transfer and synthesized detailed results with favored styles.

Introduction
In this paper, they focus on how to transfer arbitrary styles with one single model. Even with their current success, the current methods still suffer from artifacts, such as distortions in the semantic structures and detailed style patterns. This is because, when there is a large variation between content and style images, it is difficult to use the network to synthesize the stylized outputs in a single step for example Figure 1(a).
To solve those artifacts they propose an iterative error-correction mechanism to break the stylization process into multiple refinements like in Figure 1(b). Given an insufficiently stylized image and computing what is wrong with the current estimate to transit the error information to the whole image.
The detected errors evaluate the residuals to the ground truth, which thus can guide the refinement effectively. Both the stylized images and error features encode information from the same content-style image pairs. Thus, a novel error transition module is introduced to predict a residual image that is compatible with the intermediate stylized image. Compute the correlation between the error features and the deep features extracted from the stylized image. Then errors are diffused to the whole image according to their similarities.
Method
Figure 2 show the overall framework implemented using a Laplacian pyramid, which has 3 levels. Each refinement is performed by an error transition process with an affinity matrix between pixels followed by an error propagation procedure in a coarse-to-fine manner to compute a residual image. Each element of the affinity matrix is computed on the similarity between the error feature of one pixel and the feature of stylized result at another pixel, which can be used to measure the possibility of the error transition between them.
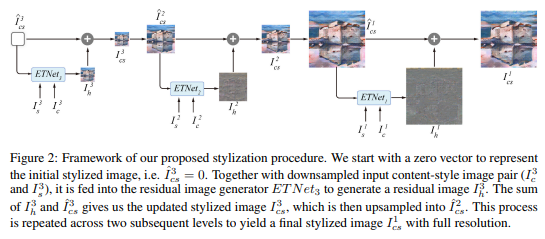
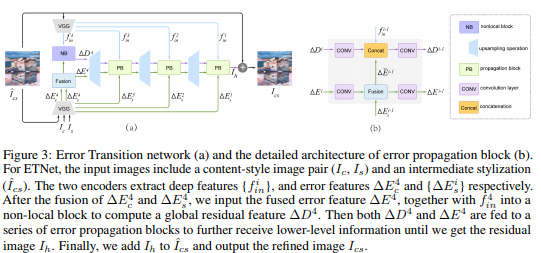
The Error Transition Network has to generate a residual image for each level of a pyramid. As illustrated in Figure 3, it contains two VGG-based encoders and one decoder. Taken a content-style image pair (\(I_c\) and \(I_s\)) and an intermediate stylized image (\(\hat{I}_{cs}\)) as inputs, one encoder (\(\theta_{in}(\cdot)\)) is used to extract deep features \(\{f^i_{in}\}\) from \(\hat{I}_{cs}\), \(f^i_{in} = \theta^i{in}(\hat{I}_{cs})\) and the other encoder (\(\theta_{err}(\cdot)\)) is for the error computation._
Results
Ablation Study
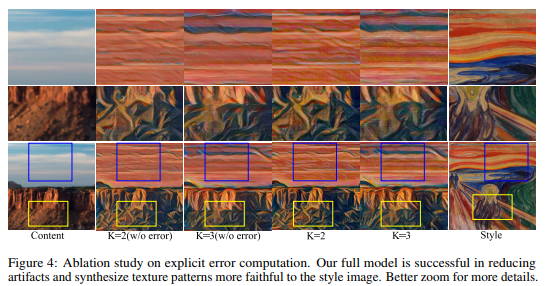
The model without error information can still somehow improve the stylization a little bit, since the plain deep features also contain error features, but comparing to our full model of feeding error explicitly, it brings more difficulty for the network to exact the correct residual info. Figure 4 shows a visual comparison.
Qualitative Comparison
Figure 6 presents the qualitative comparison results to state of the art methods.

The output style patterns are more faithful to the target style image, without distortion and exhibiting superior visual detail. Meanwhile, this model better respects the semantic structures in the content images, making the style pattern be adapted to these structures.
Figure 7 show close-up views of transferred results to indicate the superiority in generating style details. For the compared methods, they either fail to stylize local regions or capture the salient style patterns. This approach performs a better style transfer with clearer structures and good-quality details.

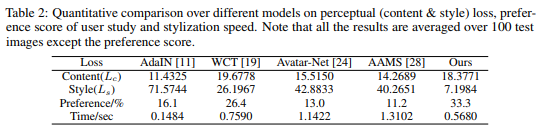
Quantitative Comparision
To quantitatively evaluate each method, they conduct a comparison regarding perceptual loss and report the results in the first two rows of Table 2. It shows that, the proposed method achieves a significant lower style loss than the baseline models, whereas the content loss is also lower than WCT but higher than the other three approaches. This indicates that this model is better at capturing the style patterns presented in style images with good-quality content structures.