ipA-MedGAN: INPAINTING OF ARBITRARILY REGIONS IN MEDICAL MODALITIES
Highlights
- Authors propose a new generative framework for medical image inpainting that bypasses the limitations of previous frameworks by enabling inpainting of arbitrarily shaped regions without a prior localization of the regions of interest.
Introduction
Distortions in medical images (e.g. motion artifacts, diffusion signal attenuation and dropouts, etc.) are tackled using a variety of methods. Inpainting methods have been proposed as an alternative to common, non-deep learning-based techniques.
In a previous work 1 authors proposed an inpainting framework that had two major limitations:
- It is restricted to square-shaped inpainting regions
- It demands exact localization of the masked region of interest
The work proposed in this paper overcomes these limitations.
Methods
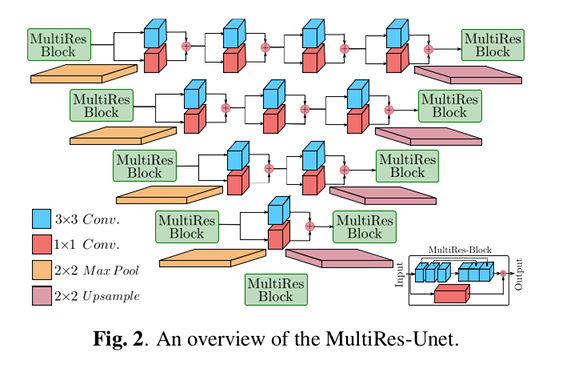
The proposed method, called ipA-MedGAN (for inpainting of arbitrarily regions in medical images using GANs), is constructed using a new cascaded generator network based on MultiRes-UNets, and two discriminator networks trained jointly as a conditional GAN (cGAN).
Their previous ip-MedGAN framework’s discriminator receives as input only the inpainted regions of interest instead of the full output and target images.
Authors argue that the need for localization is overcome using a combination of two discriminator networks with different receptive fields and different depth, one focusing on global properties, and the other on finer details. These contribute to the adversarial loss.
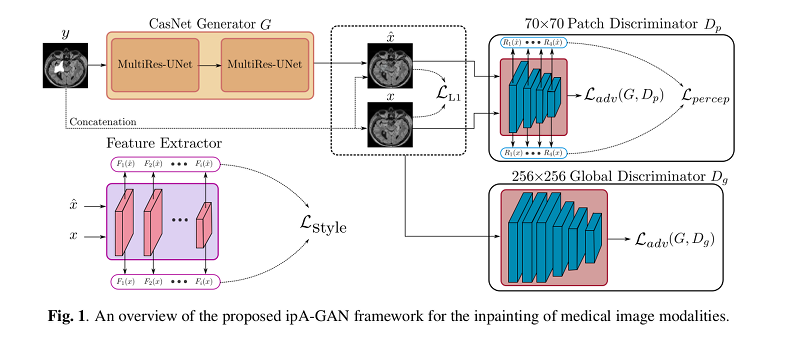
The non-adversarial loss is composed of three terms:
- Reconstruction loss (an \(L1\) error)
- A “perceptual loss” minimizing the discrepancy of the the resultant and the target images in the feature-space.
- A “style-reconstruction” loss inspired from neural style-transfer. This is achieved by using the feature-maps extracted from a pre-trained feature extractor network.

The contributions of each loss term were determined using Bayesian optimization.
Data
T2-weighted (FLAIR) brain MRI images from 44 subjects: 3028 scans from 33 subjects for training and 1072 scans from 11 subjects for testing.
Results
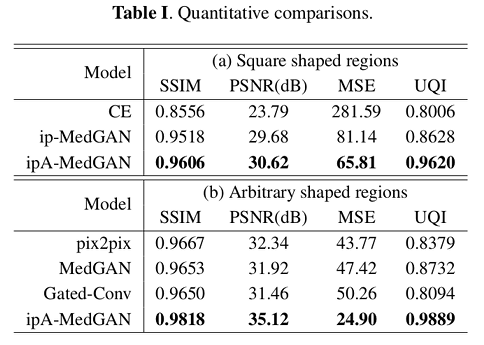
Square and random-shaped regions were cropped for the evaluation of the performance. Quantitative comparisons were carried out on the basis of:
- Universal Quality Index (UQI) 2
- Structural Similarity Index Measure (SSIM) 3
- Peak Signal to Noise Ratio (PSNR)
- Mean Squared Error (MSE)
Their baseline methods were
Results show an improvement in quantitative and qualitative performance.
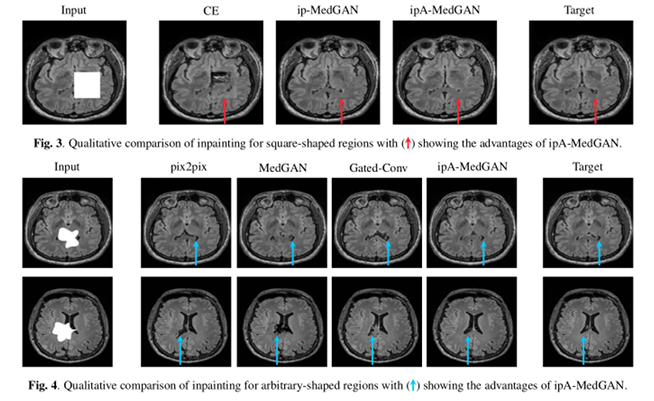
Conclusions
Authors have proposed an inpainting framework capable of correcting distortions on medical images over arbitrarily shaped regions with no a priori knowledge on the pixel locations of the regions of interest.
Comments
The proposed framework works on 2D images, and authors have left using 3D images as future work.
The factor that allows to correct for arbitrarily-shaped regions is unclear.
Medical image distortions are not revealed as blank regions, so further experiments are needed to tell whether the approach provides a good accuracy when using typical medical image dropouts.
References
-
Karim Armanious, Youssef Mecky, Sergios Gatidis, and Bin Yang. Adversarial inpainting of medical image modalities. IEEE International Conference on Acoustics, Speechand Signal Processing (ICASSP), May 2019, pp. 3267-3271. ↩ ↩2
-
Zhou Wang and Alan C. Bovik. A universal image quality index. IEEE Signal Processing Letters, March 2002, vol. 9, pp. 81-84. ↩
-
Zhou Wang, Alan C. Bovik, Hamid R. Sheikh, and Eero P. Simoncelli. Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing, 2004, vol. 13, pp. 600-612. ↩
-
Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor Darrell, and Alexei A. Efros. Context encoders: Feature learning by inpainting. IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 2536-2544, 2016. ↩
-
Jiahui Yu, Zhe Lin, Jimei Yang, Xiaohui Shen, Xin Lu and Thomas Huang. Free-form image inpainting with gated convolution. https://arxiv.org/abs/1806.03589, 2018, arXiv preprint. ↩
-
Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. Conference on Computer Vision and Pattern Recognition (CVPR), 2016, pp. 5967-5976. ↩
-
Karim Armanious, Chenming Jiang, Marc Fischer, Thomas Küstner, Konstantin Nikolaou, Sergios Gatidis, and Bin Yang. MedGAN: Medical image translation using GANs. http://arxiv.org/abs/1806.06397v1, 2018, arXiv preprint. ↩