Straight to the point: reinforcement learning for user guidance in ultrasound
Highlights
- System to guide inexperienced users towards the acquisition of clinically relevant images of the heart in ultrasound
- Environments to simulate offline any (reasonable) acquisition trajectory the user may take while scanning the patient by making use of tracked video sequences
- Comparison of the performances of the method with the ones obtained by training a classifier to learn a policy on the same data in a fully supervised manner
Introduction
The authors propose a method for guiding inexperienced users in the acquisition of clinically relevant images of the heart in ultrasound through the parasternal long axis (PLAx) sonic window on the heart. Up until now, an experienced user must provide, in real time, accurate instruction for fine manipulation of the ultrasound probe in order for the probe to gather clinically relevant images. The goal of this paper is thus to train a RL policy to predict accurate guidance information to be displayed to the probe’s user, based on the image produced by the probe.
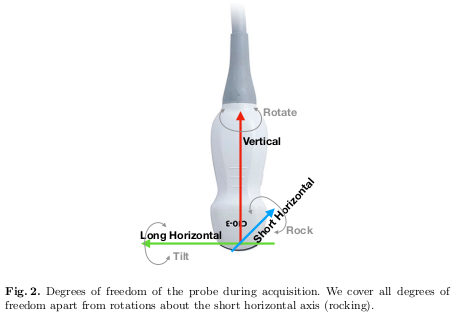
The degrees of freedom covered by the automatic guidance system proposed in the paper are detailed in Figure 2.
Methods
Environment
It would be impossible to collect data according to the RL agent’s policy since it would require to scan a patient during training, so a large number of spatially tracked video frames was acquired to navigate the chest area offline. To limit the near infinite range of possible image acquisition points on the chest, the authors divided a large portion of the chest into 7 x 7 spatial bins, and acquired images only at these positions. In the bins characterized as “correct” for the acquisition of images, more images were acquired along at various positions along the other degrees of freedom.
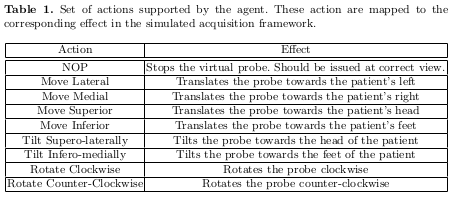
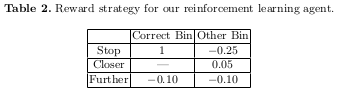
Table 1 shows how the acquisition’s degrees of freedom where represented in possible actions, while Table 2 describes the reward strategy.
RL Agent
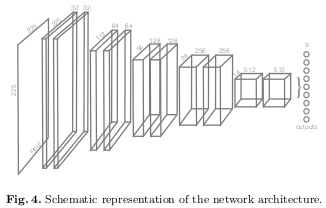
The agent is trained using the DQN learning paradigm, with the policy network being a CNN. The input of the model are ultrasound images, and its output is represented by nine Q-values, one for each action. Figure 4 shows the proposed architecture for the policy network.
The objective function used to update the parameters is the following equation:
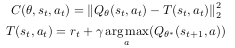
Supervised policy learning
Each image acquired in each bin was labelled with one action, which would be the optimal action to perform in that state if we relied only on the Manhattan distance \(\mid x - x_{goal} \mid\).
The authors train a classifier with the same architecture shown in Figure 4, with the only exception that the last layer is followed by a soft-max activation function.
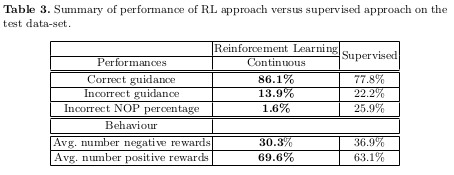
Results
Conclusions
The authors explain the intuition behind the better results for the DQN approach compared to the supervised policy. They state that RL is able to avoid and go around areas that are highly ambiguous as the Q-Values in correspondence of the actions leading to those states should not be very high. They also hypothesize that RL implicitly learns the spatial arrangement of the different pictures on the chest, since it must be able to differentiate between them to produce different ranges of Q-values (low when far away, and higher near the goal).
Remarks
- Very long training time limits the possibility of experimenting with different sets of hyper-parameters
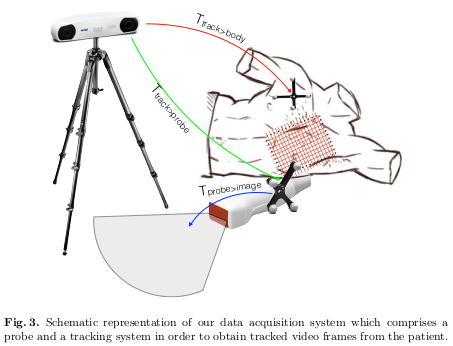
- Issues with the scalability of data acquisition strategy; tedious scanning procedure with dedicated and costly equipment (show in Figure 3) that can last up to 20 minutes per patient