Lookahead Optimizer: k steps forward, 1 step back
Highlights
This paper proposes a new gradient descent algorithm. As mentioned by the authors, the recent attempts to improve SGD can be broadly categorized into two approaches: (1) adaptive learning rate schemes,such as AdaGrad and Adam, and (2) accelerated schemes, such as heavy-ball and Nesterov momentum. In this paper, they propose a new optimization algorithm called Lookahead, that is orthogonal to these previous approaches.
The main benefit of that method is a lower variance and a better stability.
Proposed method

As shown in Fig.1, the algorithm updates two sets of weights: the fast and the slow weights. The algorithm chooses a search direction by looking ahead at the sequence of fast weights generated by a third-party optimizer, be it SGD, adam, adagrad, etc. The slow weights are updated by picking up a position between the first and the last fast weights.
By doing so, they show that their method implements a Polyak-style running average
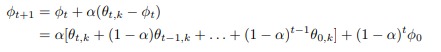 |
which they use to prove that their method has a better stability and a lower variance.
Results
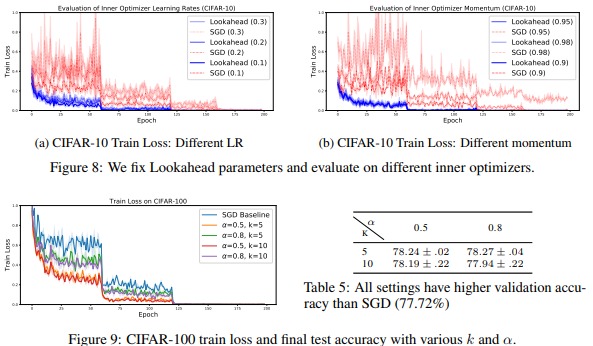
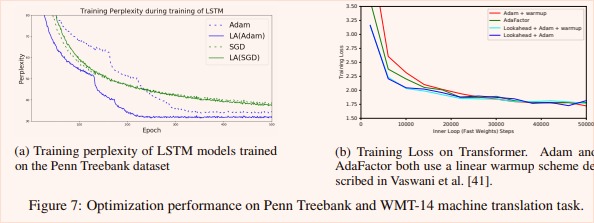
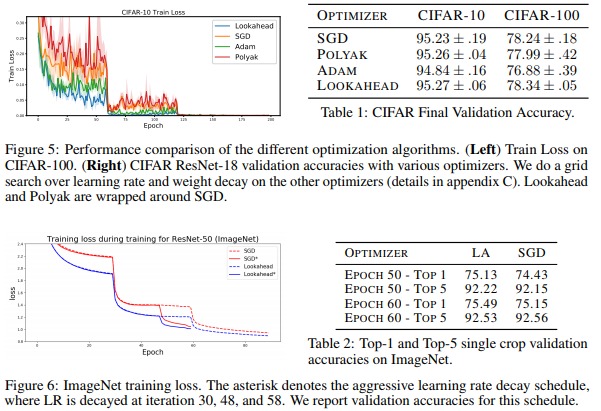
While some results show a spectacular lower variance and a faster convergence (c.f. Fig.5, 8 and 9) the true benefit of that method is more or less obvious when only considering accuracy / training loss after several epochs (Fig.7, 5, 6).