On Boosting Semantic Street Scene Segmentation with Weak Supervision
Highlights
-
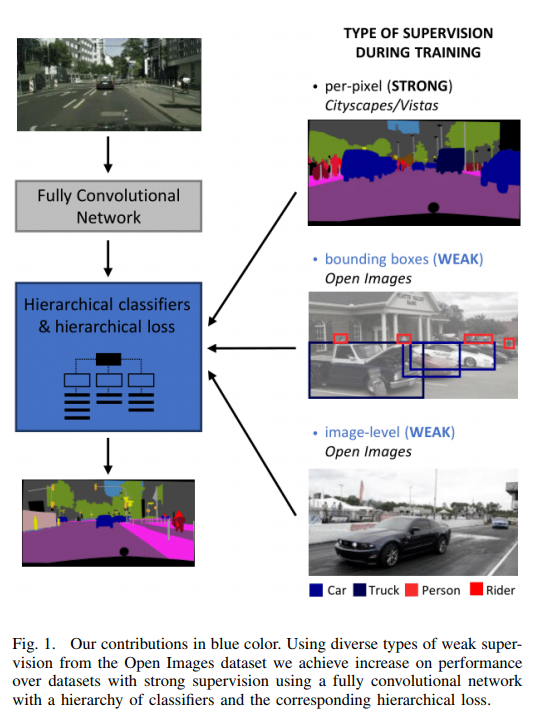
Authors propose a methodology for training semantic segmentation networks on datasets with diverse supervision, including per-pixel, bounding box, and image-level labels.
-
Authors introduce a new dataset OpenScapes dataset: a large, weakly labeled dataset with 200 000 images and 14 semantic classes for street scenes recognition.
Introduction
They develop a hierarchical deep network architecture and the corresponding loss for semantic segmentation that can be trained from weak supervision, such as bounding boxes or image-level labels, as well as from strong per-pixel supervision. Even from separate datasets, their model consistently increases the performance against per-pixel only training.
Method
This method facilitates the training of any fully convolutional network for per-pixel semantic segmentation and only requires a specific structure of classifiers and a specialized loss to train them.
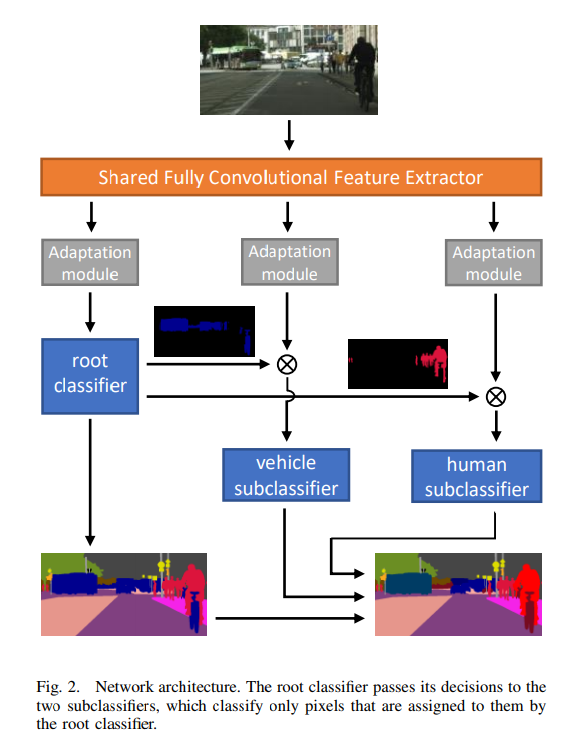
Convolutional Network Architecture
The hierarchy of classifiers is constructed according to the availability of strong and weak labels for each class. The root classifier contains high-level classes with per-pixel labels. Each one of the subclassifiers corresponds to one high-level class of the root classifier and contains subclasses with per-pixel and/or weak supervision. The shared feature representation is pass through two shallow, per-classifier adaptation networks, which adapt the common representation, its depth, and receptive field to meet the requirements of each classifier.
Generation of pseudo per-pixel ground truth from weak labels
The goal is to train the network with per-pixel labels, thus need to generate per-pixel ground truth from bounding boxes and image-level labels. That method is valid only for square-shaped, compact objects, like traffic signs, and cannot be applied to image-level labels.
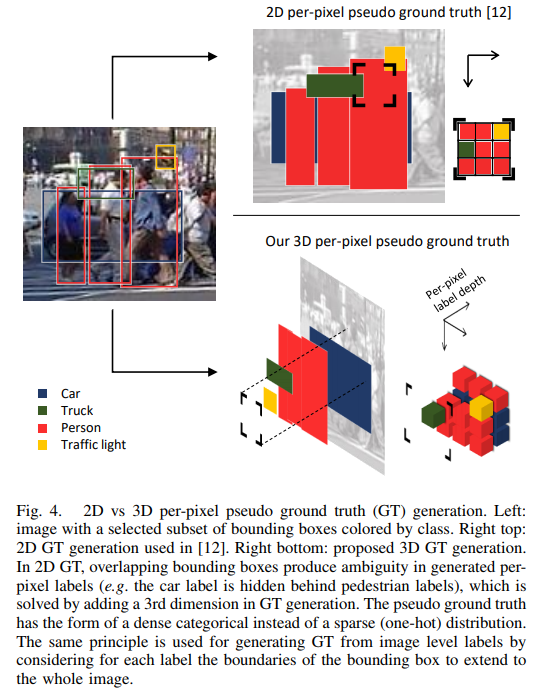
This approach model per-pixel labels as a dense or multi-hot categorical probability distribution, and thus the ground truth for each image becomes 3D. This model assigns to each pixel a probability for every class, and the sum of probabilities for all classes must be 1. They normalize across all classes, in order for the labels to represent a valid probability distribution.
Hierarchical loss
To help the network, they construct the hierarchical loss, namely the loss is accumulated unconditionally for per-pixel labeled datasets and conditionally for per bounding box or per image-level labeled datasets.
For each classifier, a general form of a categorical cross-entropy loss is used. For the root classifier, they use a sparse version of the categorical cross-entropy loss.
Results