Emergent Tool Use from Multi-Agent Interaction
Highlights
-
Through multi-agent competition, agents create a self-supervised autocurriculum inducing multiple distinct rounds of emergent strategy, many of which require sophisticated tool use and coordination.
-
These learned strategies transfer well to new problems
Introduction

Creating intelligent artificial agents that can solve a wide variety of complex human-relevant tasks has been a long-standing challenge in the artificial intelligence community.
One way of trying to train such agents is through self-play, where agents will compete and cooperate. When an agent finds a successful strategy, it changes the implicit task distribution the other agents need to solve and forces them to come up with better strategies. This process is called implicit autocurricula and has been leveraged to solve games like Dota and Starcraft.
The authors present six strategies learned by agents playing team hide-and-seek.
Methods

The agents play hide and seek in an environment composed of various-shaped boxes and ramps as well as unmovable walls.

The agents can move by setting a force on themselves in the x and y directions as well as rotate along the z-axis, see objects in their line of sight and within a frontal cone, sense distance to objects, walls, and other agents around them using a lidar-like sensor, grab and move objects in front of them and lock objects in place.
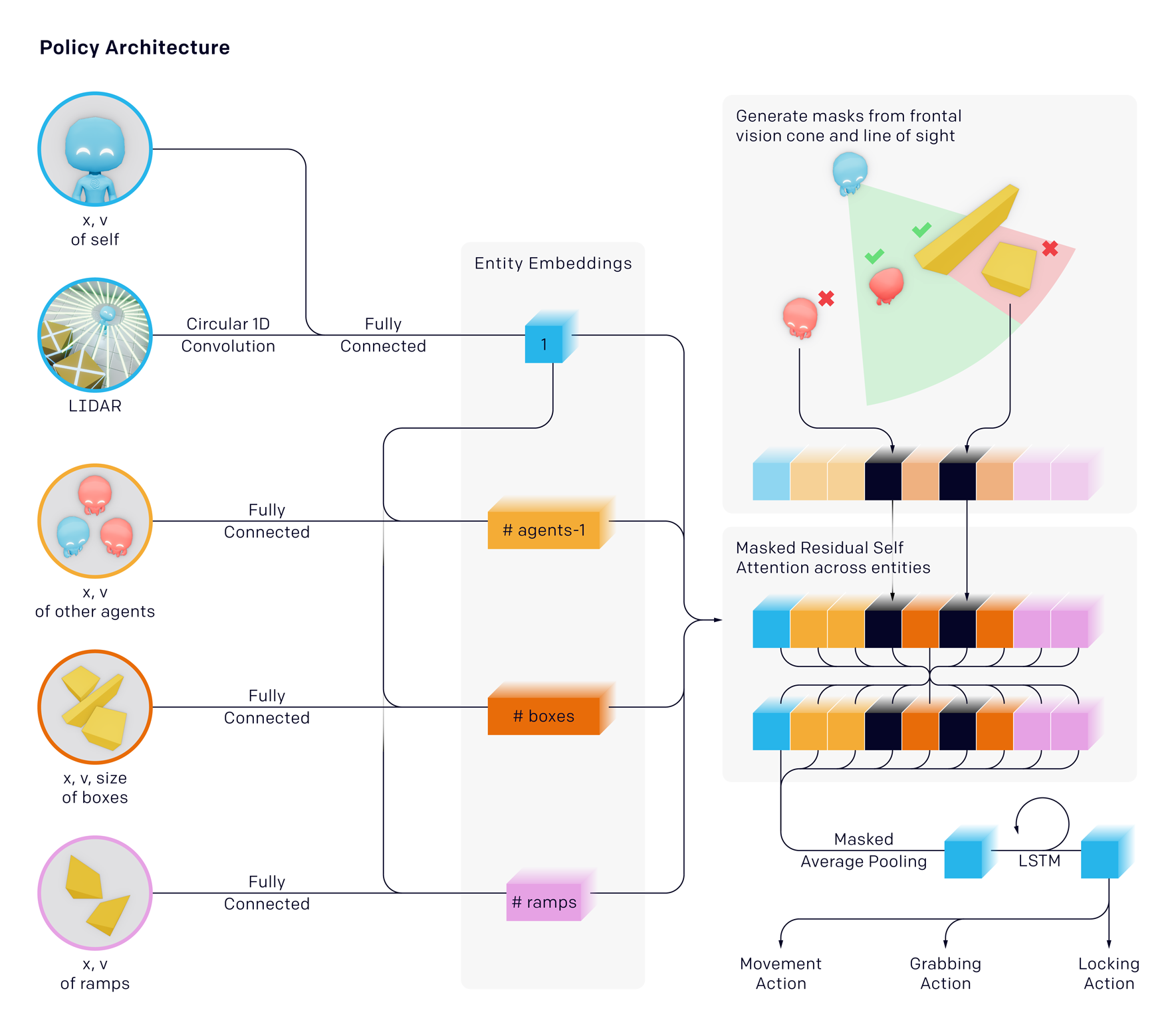
Each agent acts independently and passes it’s observations through a masked residual self-attention block then through an LSTM. Agent policies are trained with self-play and PPO. During optimization, agents can use privileged information about obscured objects and other agents in their value function. They found that their agents converge the fastest using mini-batches of 64 000 10-transitions per update.
Results
The authors found that the agents always came up with the same strategies throughout learning

To see if autocurricula was the only way to learn these complex strategies, the authors also taught the agents through intrinsic motivation, where agents are rewarded for exploring the state space. However, as shown below, the learned behaviors were less meaningful.

To quantitatively measure progress, the authors devised a suite of domain-specific intelligence tests that target capabilities they believe agents may eventually acquire
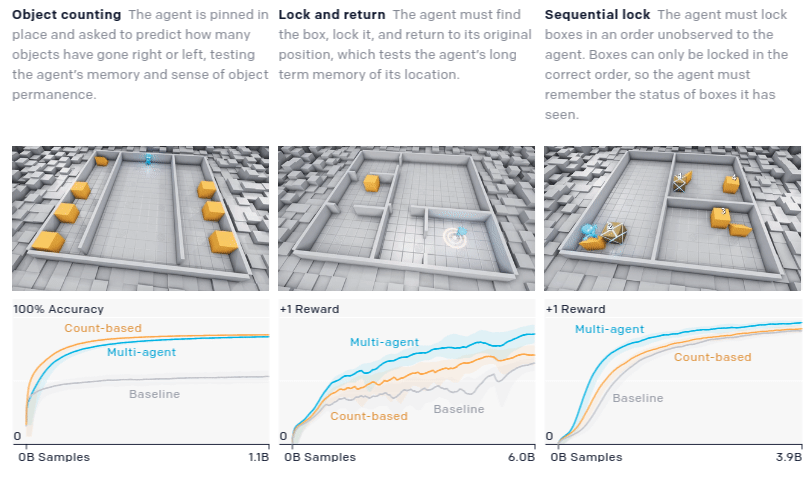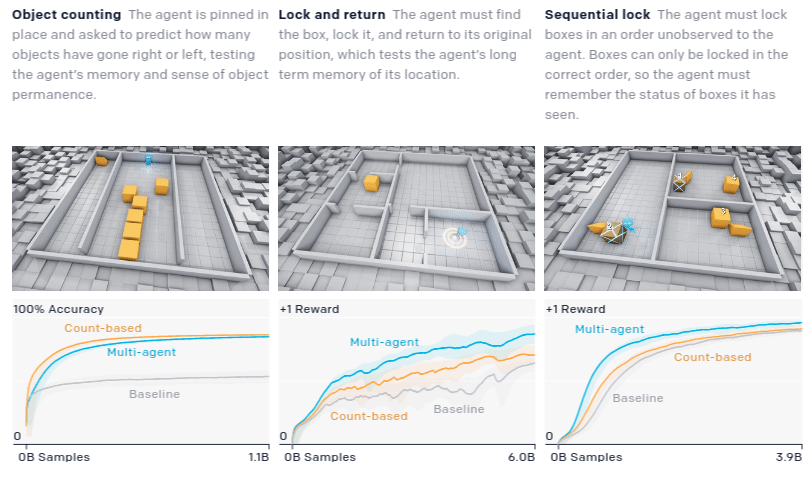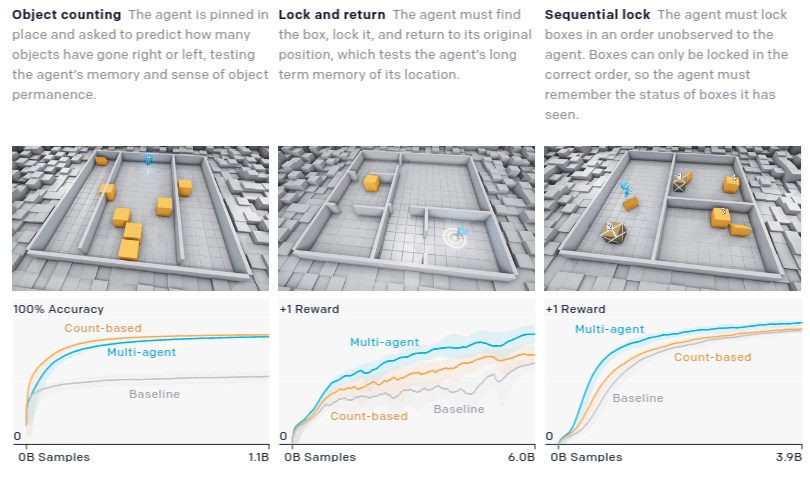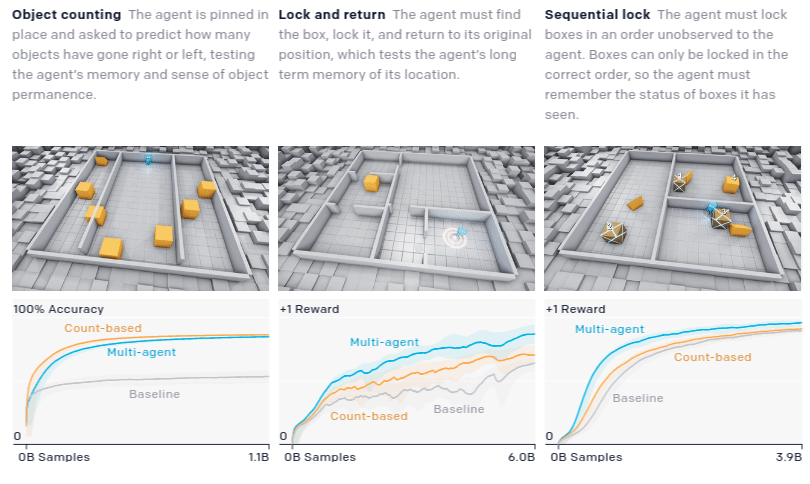

Though the hide-and-seek agent performs better on many of the transfer tasks, it does not drastically improve performance or convergence time. It is clear it has the latent skill to move objects in a precise manner to construct shelter in the hide-and-seek game; however, it does not have the capability to use this skill in other contexts when trained with a low number of samples.
Conclusions
The authors provided evidence that human-relevant strategies and skills, far more complex than the seed game dynamics and environment, can emerge from multi-agent competition and standard reinforcement learning algorithms at scale.
Remarks
The video linked above is a good summary of the base experiment, and the blog post provides a lot of insight on how the experiment was done.