State-Reification Networks: Improving Generalization by Modeling the Distribution of Hidden Representations
Highlights
- Help RNNs “stay on track” without teacher forcing (make them more robust to their own generated sequences that may differ from the training sequences)
- Make classification networks more robust to adversarial data
- Achieved by adding a Denoising Autoencoder (DAE) / Attractor Network inside a hidden layer
Introduction
- The general idea is to find a way to map hidden states that may differ from the training examples towards the distribution seen during training.

Methods
-
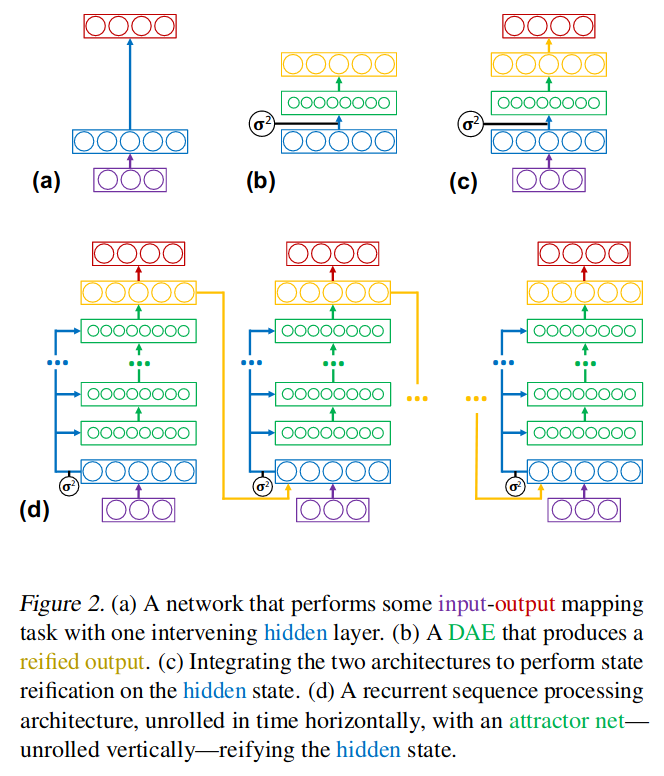
Feed-forward Network: Add a DAE inside a hidden layer; see Figure 2 (c)
-
RNN: Add an Attractor Network inside a hidden layer of the RNN; see Figure 2 (d)
- An Attractor network is a DAE with recurrent steps
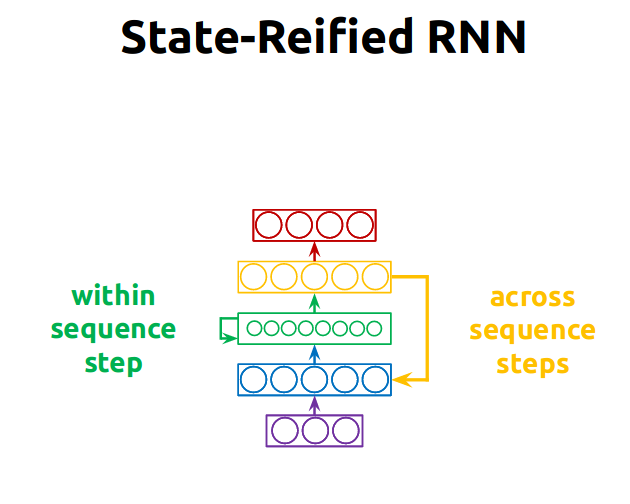
- Rolled-up graph:
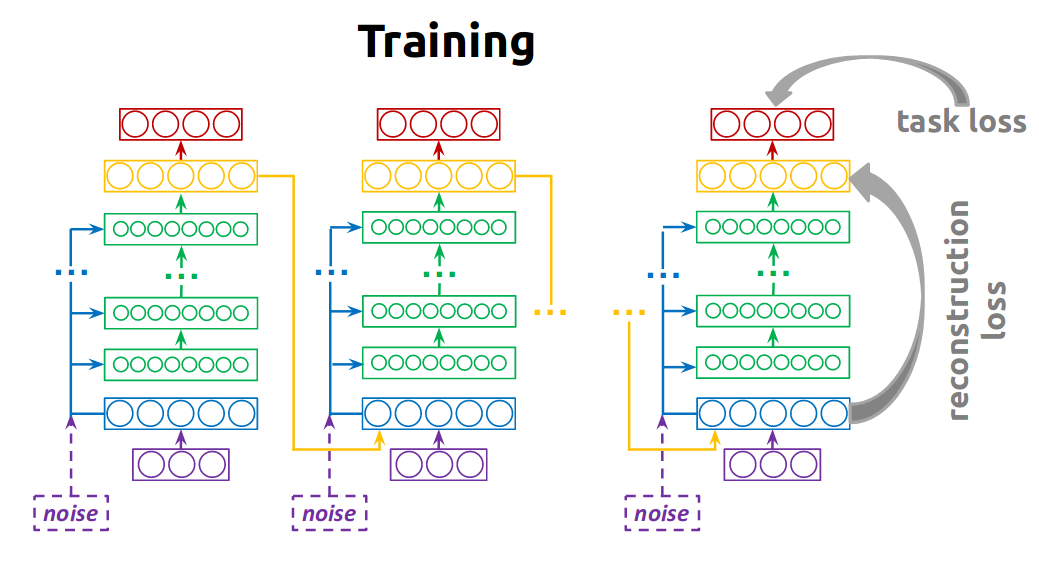
- Complete figure (taken from the presentation slides):
Data
- Random binary sequences for Parity and Majority classification
- MNIST for adversarial classification
- Text8 (Wikipedia) for text generation
Results
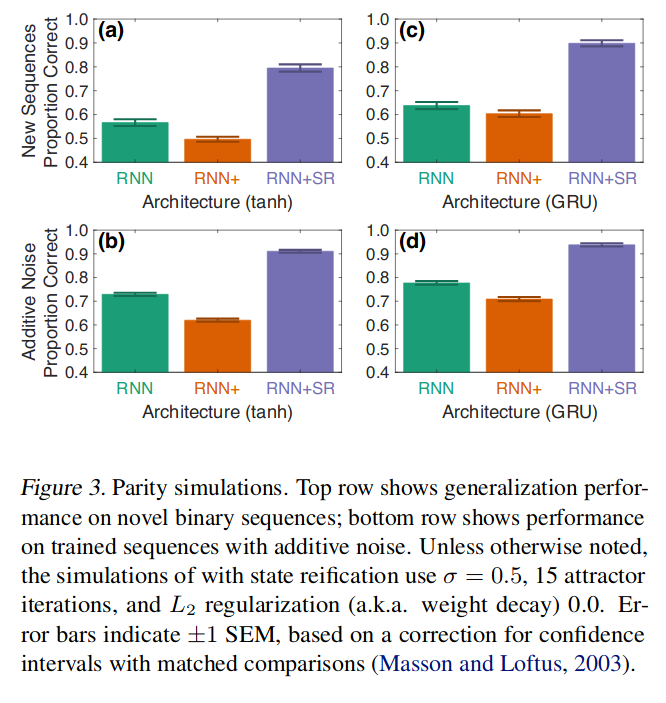
- Bit sequence classification for parity tests
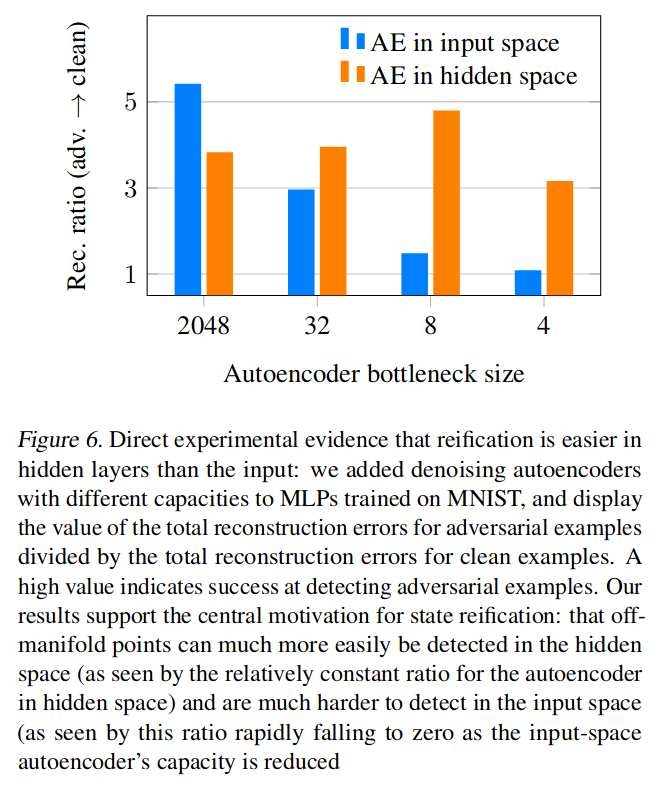
- MNIST classification to test whether reification is more useful in input space or hidden space
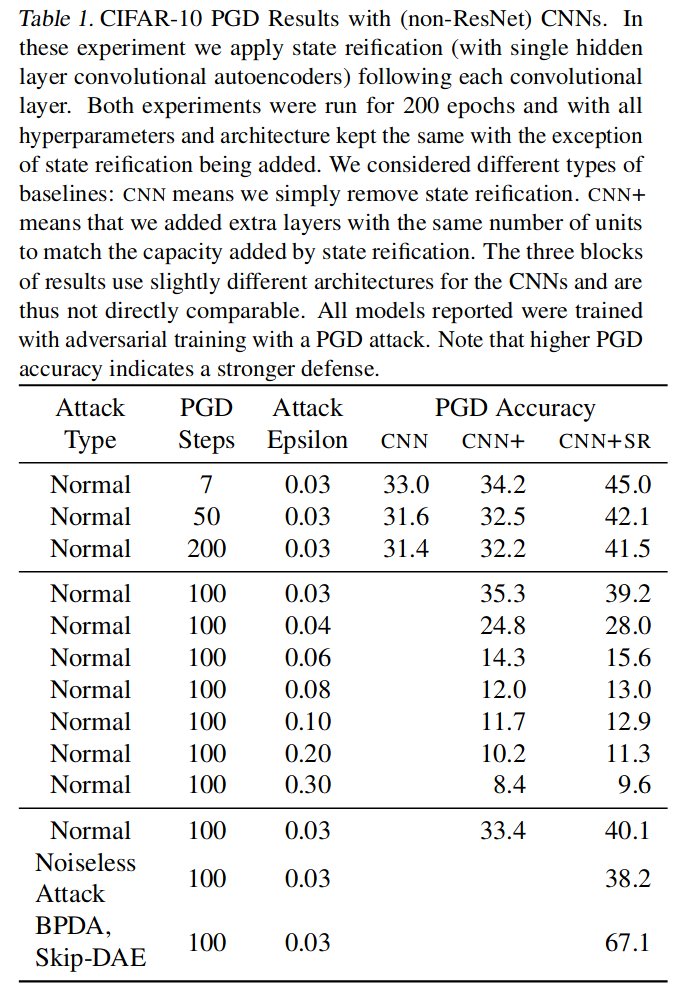
- CNN adversarial experiments
Conclusions
- No clear experiments for RNN generation, but overall looks easy to implement
- Seems to improve generalisation to new or noisy sequences, but needs more pratical experiments