Don't Worry About the Weather Unsupervised Condition-Dependent Domain Adaptation
Introduction
This paper underlines the fact that performance degrades quickly when the input conditions change event a little. The authors present a domain adaptation system that uses light-weight input adapters to preprocesses input images, irrespective of their appearance, in a way that makes them compatible with off-the-shelf computer vision tasks that are trained only on inputs with ideal conditions.
The paper shows a hybrid method, where multi-modal data generated in an unsupervised fashion with approximated ground truth. The method is followed by supervised training of domain-adapters, for multiple computer vision tasks, using this generated data and approximated ground truth.
This approach has for goal to incrementally adapt to a new, unseen domain. If the condition of the input images does not match one that the system has been previously trained on, the unsupervised style transfer pipeline will select a model that is the closest to the current condition, clone it, and fine-tune this cloned model. This way, the model will be able to change the style of the reference sequence so that it matches the style of the current input images. Those images will be used to train, in a supervised fashion, an additional condition-specific image adapter that will allow upstream computer vision tasks to perform well on the new input image condition.
The main contributions:
-
Using cycle-consistency GANs to generate multi-condition training data with approximated ground truth for a battery of off-the-shelf computer vision tasks.
-
Training input image adaptors by using the off-the-shelf computer vision models to generate a supervisory signal.
-
Enabling online learning of new, unseen domains by leveraging the unsupervised data generation pipeline along with domains on which the data generation models have already been trained.
-
Showing that training multiple light-weight adapter modules is better than training monolithic computer vision models that are invariant to input distributions.
Learning Condition-Dependent Representations
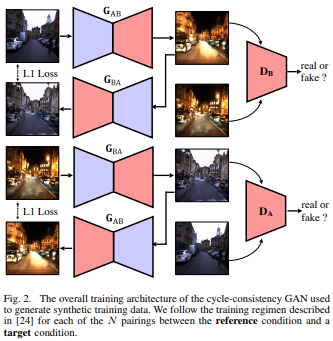
Synthetic Multi-Condition Data
They select a reference sequence of images: daytime, clear, and overcast. Besides, they add some traversals with conditions (night, rain, snow, etc.), along with a cycle-consistency GAN, that can apply style transfer to the reference condition creating synthetic sequences that maintain the structure and geometry of the reference condition.
Adversarial loss:
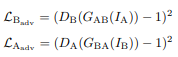
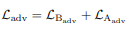
Loss for discriminators:
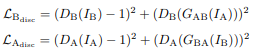
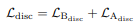
Reconstruction and Generator Loss:
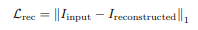
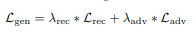
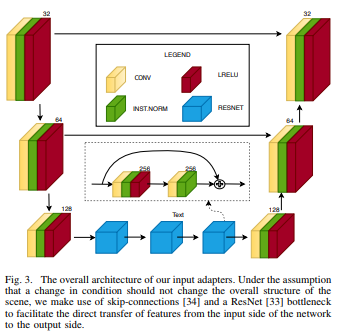
Input Adapters
The second step, in this approach, is to use the data generated in the previous step to train a bank of adapters that preprocess the input images. This way, they follow a distribution similar to that of the training sets used to train the bank of tasks.
The adaptors input is a 3-channel RGB image, while the output is a 3-channel image compatible with the inputs of many well-known models (semantic segmentation, object detection, depth estimation, etc.). This configuration provides a light-weight solution that is easy to train using labeled data, with reduced storage requirements and use a small amount of memory.
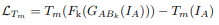
Domain Classifier
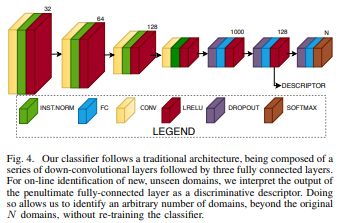
They employ a domain classifier \(D\) to select the most suitable input adapter \(F_k\) that enables optimal performance on the input images with the \(k^{th}\) condition. Given an input image \(I_A\) and a domain label \(t\), the goal is to find the parameters of the classifier \(D\) that minimizes the cross-entropy between the output of the classifier and the target label \(t\).
Online Learning
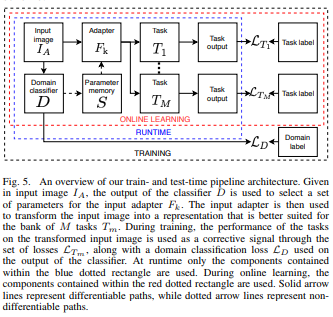
The previous subsections can extend to incremental unsupervised, online learning of new unseen domains without requiring any significant modifications to the existing system. This process is used to:
- Give a continuous sequence of incoming images, storing the current frame and \(T−1\) past frames in a buffer of length \(T\) that gets updated using a First-In-First-Out scheme.
- Compute each frame in the buffer using the penultimate layer of the classifier and average all the descriptors, yielding one single length-128 average descriptor.
- Average descriptor condition if they differ(in Euclidean space) by more than a threshold from the descriptors of any conditions previously trained on.
If the following training pipeline is triggered:
- The cycle-consistency GAN models closest to the current condition is selected (using the condition descriptor).
- The newly trained generators from above is used to apply the new style to the reference condition to create a new training sequence.
- The input adapter that is closest to the new condition(again using the descriptor) is selected, cloned and train it using the newly created training sequence from above.
- This new adapter is used until the input condition changes significantly again.
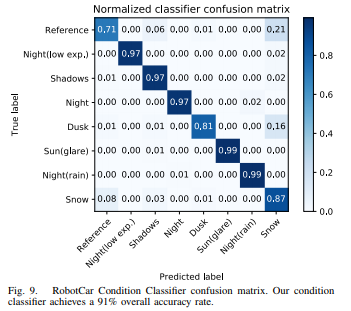
Results