Superhuman AI for multiplayer poker
Highlights
- First AI to beat humans in six-players no-limit Texas hold’em poker
Introduction
Poker has always been the poster child for imperfect/hidden information games in game theory and AI. Prior breakthroughs in Poker AI, like Libratus, and games in general (Starcraft, Go, Dota, etc.) have been limited to two-player zero-sum games. While such AI typically approximates a Nash equilibrium strategy, however, finding or even approximating such equilibria in more-than-two-player games can be extremely hard and possibly not even worth it.
Tree search algorithms, like ABP and MCTS, have also been used extensively in prior algorithms. However, using such algorithms in hidden information games lead to intractable search spaces.
Methods
Nash equilibrium
A Nash equilibrium is reached when all players of a game are assumed to know the equilibrium strategies of the other players, and no player can gain by changing their own strategy. An example of this is the lemonade stand game, where every player must stay as far from every other player as possible.

source: ai.facebook.com
In this game, there are infinite ways the equilibrium can be reached. However, if every player computes this equilibrium separately, it is very unlikely the players will end up equally spaced. In six-player poker, the authors decided that the algorithm should not try to find such equilibrium, and instead focus on creating an AI that beats humans empirically.
Hidden information
A successful poker-playing AI must reason about the game’s information and pick the optimal strategy. However, Poker involves bluffing, where the optimal strategy might not only depend on your cards. It is, therefore, necessary to balance the probability of your opponent having a strong hand versus them bluffing. Perfect information games can use tree search algorithms such as Alpha-Beta Pruining to estimate future action outcomes. In imperfect information games, the value of an action is dependant on the probability of it being taken.
Pluribus was trained via self-play, where the agent plays against copies of itself, with a modified version of Monte-Carlo Counterfactual Regret Minimization(MCCFRM) to update its policy.
MCCFRM explores the decision tree up to a certain depth and then backtracks and explores what would have happened if other actions would have been selected. A “regret” is then calculated based on how high the value of other paths are. The regret then influences the probability of selecting actions in the future. The video below shows how Pluribus updates its policy.
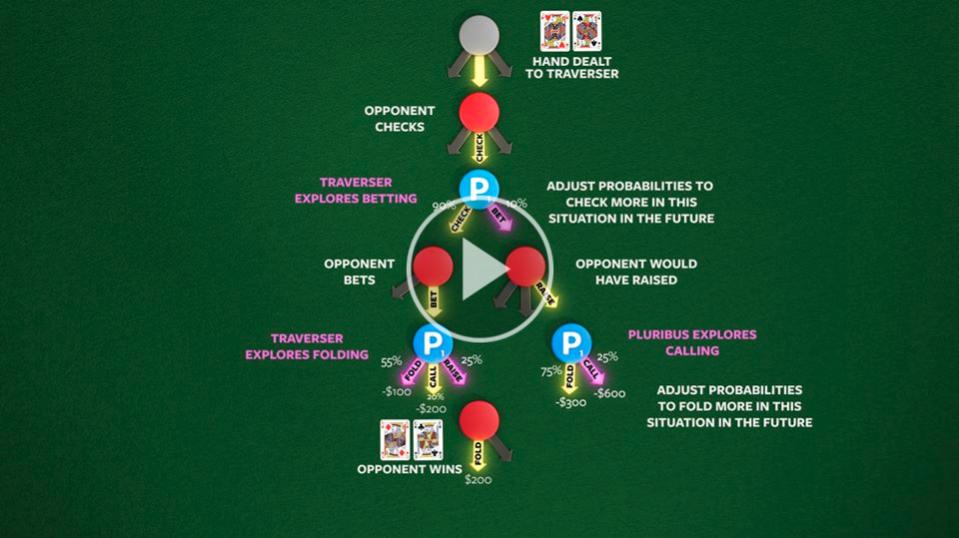
source: ai.facebook.com
Because the agent is playing against itself, it can know what would have happened if a different action had been chosen. As you can imagine, maintaining regret for every action in a game would be intractable. Therefore, the authors used “bucketing”, where similar actions and states are grouped together. For example, raising 200$ or 201$ dollar will provide similar outcomes, and an opponent having a 10-straight or a 9-straight will usually act the same.
The self-play training provides only a “blueprint” strategy that influences only the first betting round. Afterward, the agent uses MCCFRM to adapt its strategy to opponents. Moreso, tree search algorithms usually presume that the opponent will stick to a single strategy throughout the whole game, which is not something poker players do. Pluribus instead uses an approach where it will assume that each player may act according to different strategies beyond the leaf nodes. With Pluribus, the different strategies are variations of the blueprint, each more biased towards folding, calling or raising.
Finally, in Poker, the optimal strategy depends on how the opponents perceive the player’s hand. If the player never bluffs, the opponents will know to fold in response to a big raise. To add uncertainty, Pluribus computes the probability of reaching the current situation regardless of the hand it is holding. Once the strategy balanced across all hands is computed, it executes an action for the hand it is actually holding.
Data
Pluribus was trained for eight days on a 4-core server and required less than 512GB of RAM. No GPU were used.
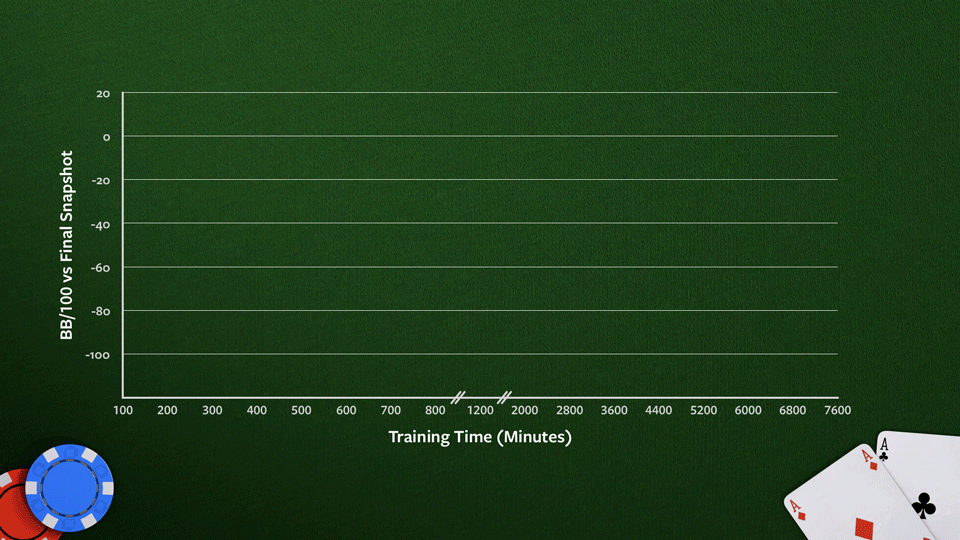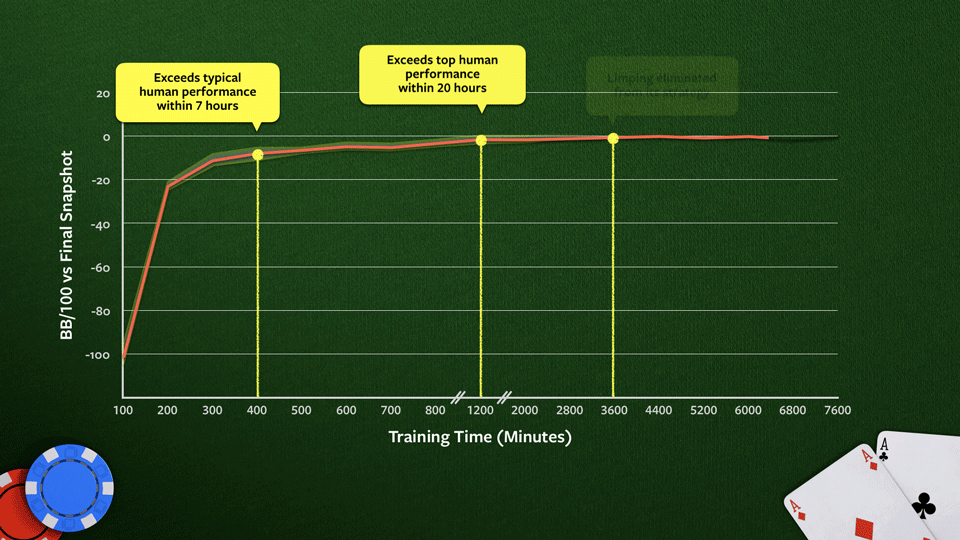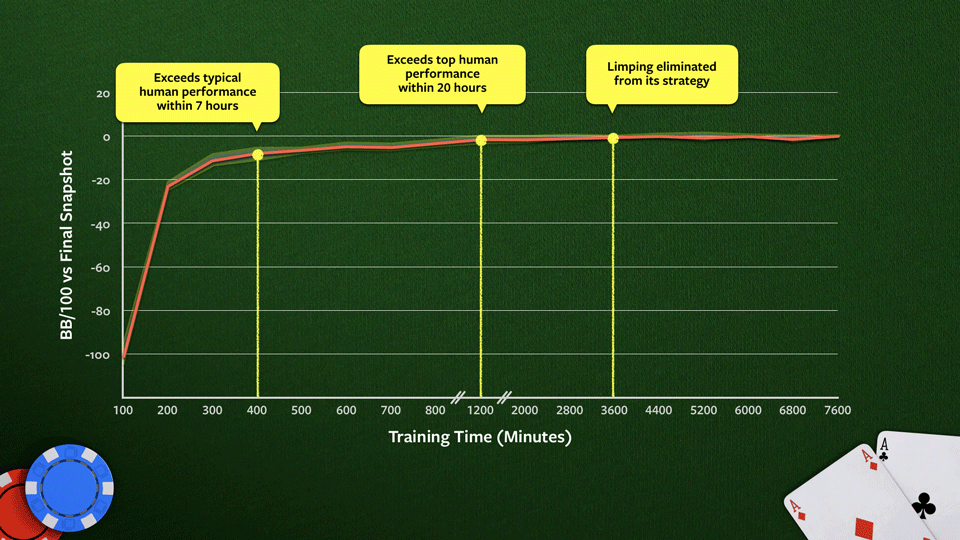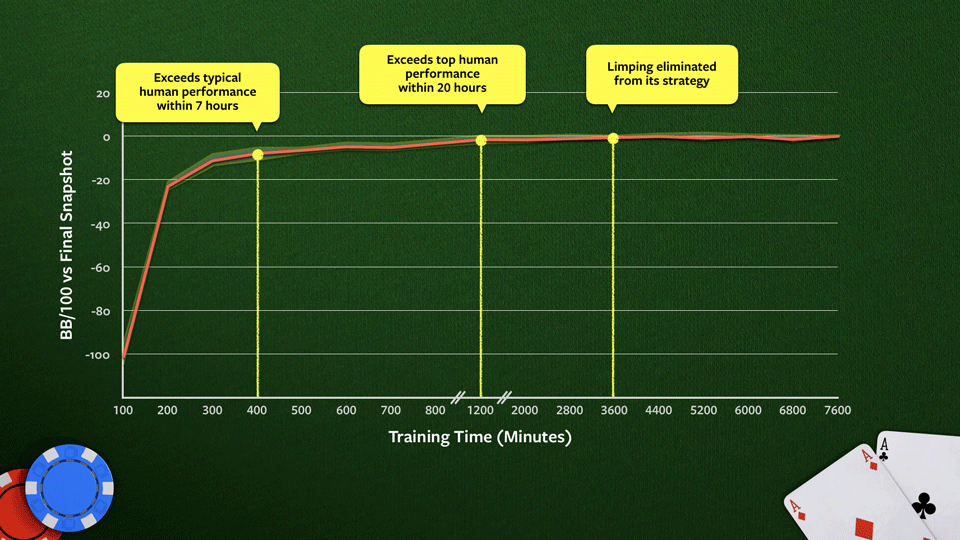
source: ai.facebook.com
The score is reported against the final snapshot of the bot, and “BB/100” means the number of big blinds won per 100 games. Limping is a strategy often employed by beginner players where the player bets the absolute minimum to stay in a hand. More advanced players prefer to be more aggressive.
Results
Pluribus was tested against five poker professionals over 12 days where 10 000 hands were played. A prize of 50 000$ was divided amongst the human pros to incentivize them to play their best. Pluribus was estimated to have a win rate of 5 BB/100, which means an average of 5$ per hand.

source: ai.facebook.com
And here it is in action

source: ai.facebook.com
Remarks
-
Unless it was not clear, Pluribus does not use neural networks and its policy is solely modified through CFR
-
Pluribus tends to do “donk betting”, where a player starts a round with a bet after ending the other with a call, which is contrarian to the folk wisdom saying it is not a good idea to do so.
-
On the opposite, it confirmed that limping is not a good strategy.
-
Human pros generally say that Pluribus plays very differently from humans
-
A lot of info is available in the supplementary material, including the MCCFR algorithm
Supplementary materials (includes pseudo code and a most of the technical stuff) Blog post HN discussion