Attention Branch Network: Learning of Attention Mechanism for Visual Explanation
The authors propose a modification applicable to most CNN architectures: adding an “Attention Branch”. This modification allows to output a visual explanation while improving accuracy.
Attention Branch
Some previous works like Class Activation Mapping do not apply a loss on the attention maps it produces. For Attention Branch Networks (ABN), the attention maps are trained. Below is a comparison of the two approaches:
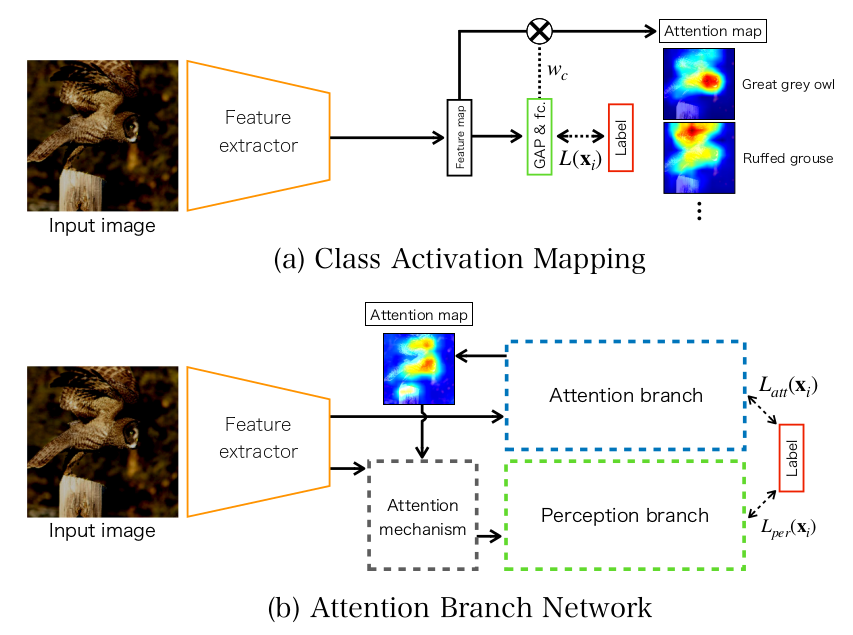
As you can see in the figure above, the original CNN is split in two sequential parts: the feature extractor and the perception branch; the attention branch is then connected right after the feature extractor. It would be misleading to call the attention branch “parallel” to the perception branch, since the output of the attention branch is fed into the perception branch. I cannot bear unnecessary crossing of lines, so I made this alternate diagram:
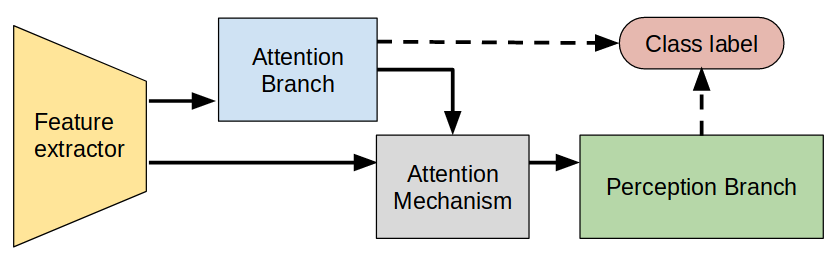
Aaah. I feel better. The figure below has more details about the attention branch and the usage of the attention maps:
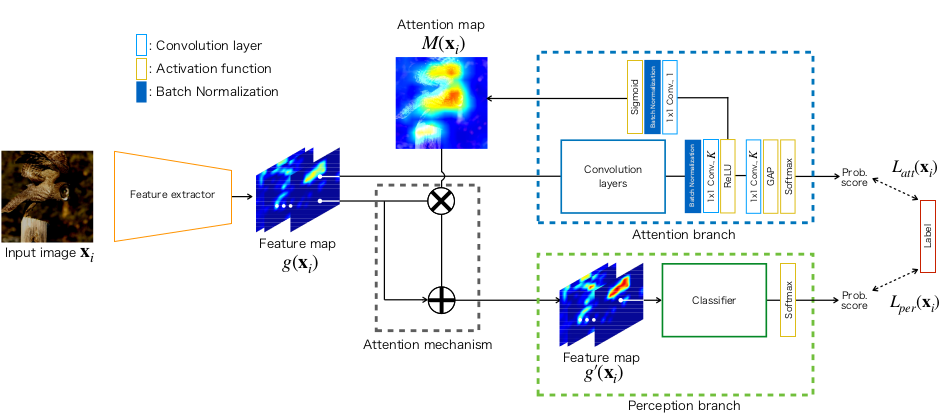
As you can see above, the attention branch itself has two branches; one branch produces the attention maps that is used in the attention mechanism, the other branch has a small auxiliary classifier that helps train the attention maps. Notice also the attention mechanism, in which the attention maps have an additive effect. They also tried a strictly multiplicative effect, but it was performing similarly or slightly worse.
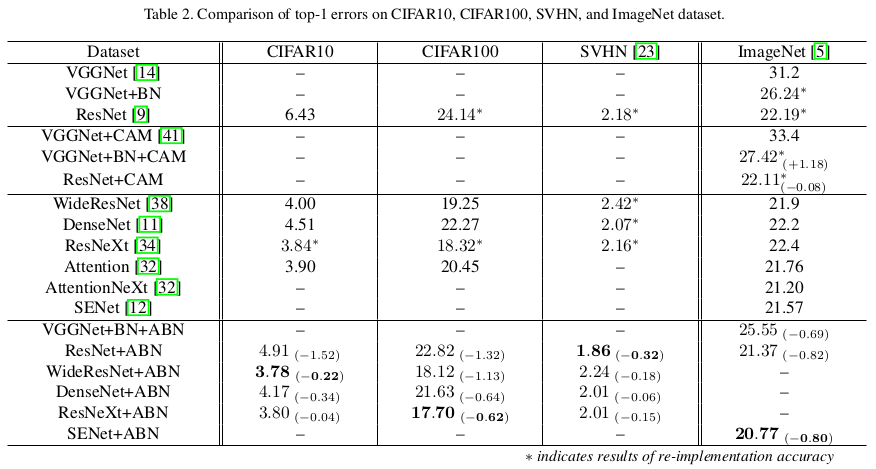
Results
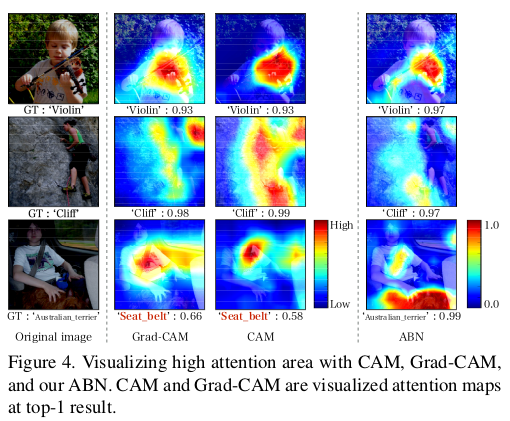
In their experiments, the method has improved the accuracy of all architectures for all datasets. However, the statistical significance of the improvement is not studied. Since the method adds parameters to the architectures, it should not be surprising to observe an improvement. Authors do not provide an analysis of resource consumption or inference speed. Fortunately, the attention maps produced do seem to significantly improve visual explanation.