Why ReLU Networks Yield High-Confidence Predictions Far Away From the Training Data and How to Mitigate the Problem
Introduction
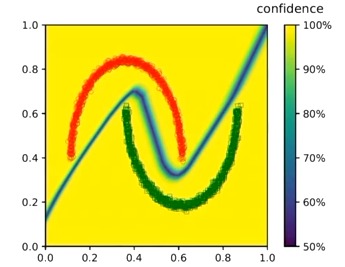
ReLU neural networks are known for being overconfident when predicting unrelated data. As shown in the paper, this is due to the fact that the output of the network is piece-wise linear.

While this problem cannot be solved per se, it can nonetheless be mitigated.
Methods
The authors propose a method to enforce a uniform confidence for any point far away from the training data. They do this with a so-called Adversarial confidence enhanced training (ACET)
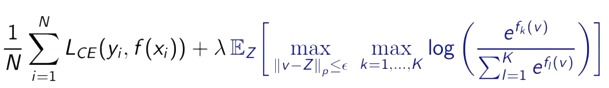
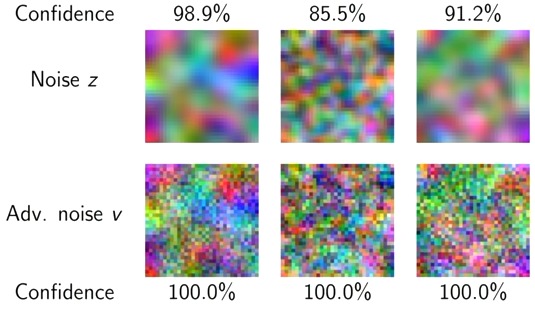
where the first term is the usual cross-entropy and the second term is a penalty term based on random adversarial images \(Z\) drawn from a noise distribution. Illustration of these images for the training of CIFAR10 is as follows:
In the following image we see the effect of training on CIFAR10 and testing of SVHN.

as well as on the synthetic 2D example
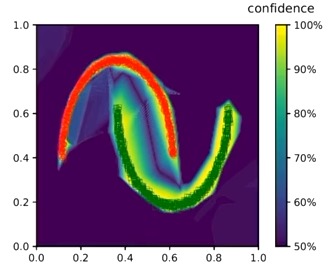
Limitations
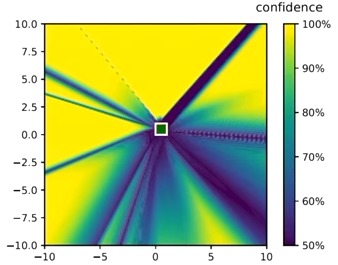
The method is not void of limitations as the network is still overconfident very far away from the training data
Results
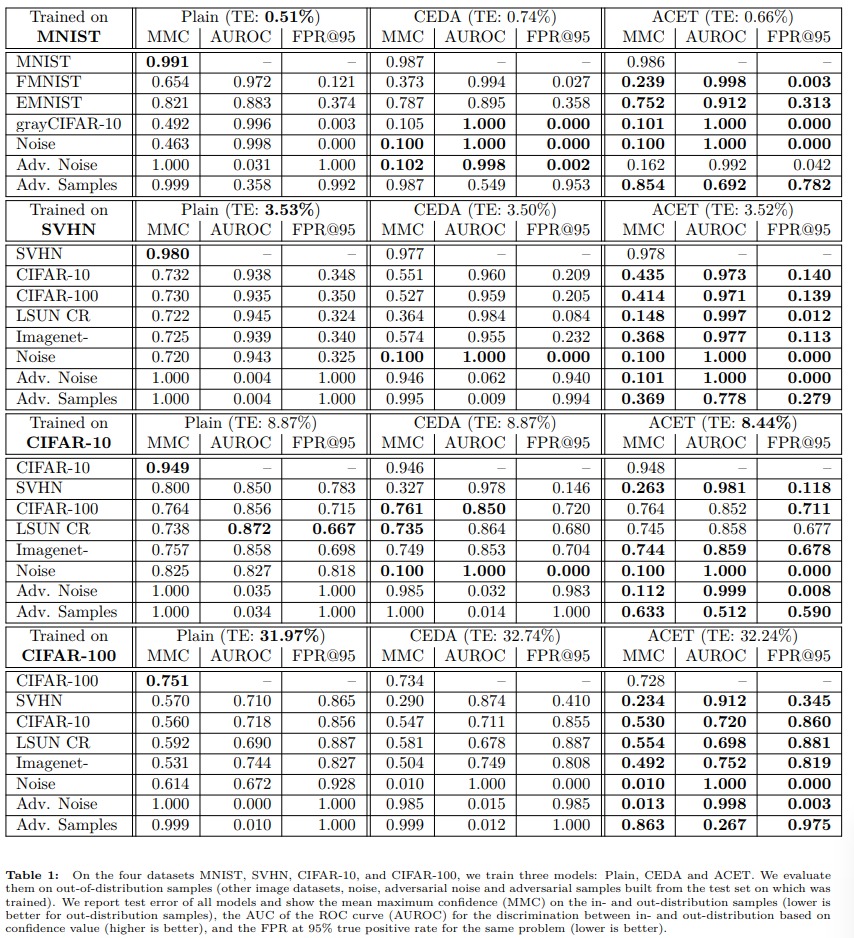
The proposed method is effective for various dataset combinations: