Speech2Face: Learning the Face Behind a Voice
Highlights
- Successfully recognize general physical traits such as gender, age, and ethnicity from a voice clip
Introduction
“How much can we infer about a person’s looks from the way they speak?”. In this paper, the authors reconstruct a “canonical” (front facing, neutral expression, uniformly lit) face from a 6 seconds voice clip using a voice encoder.
Methods
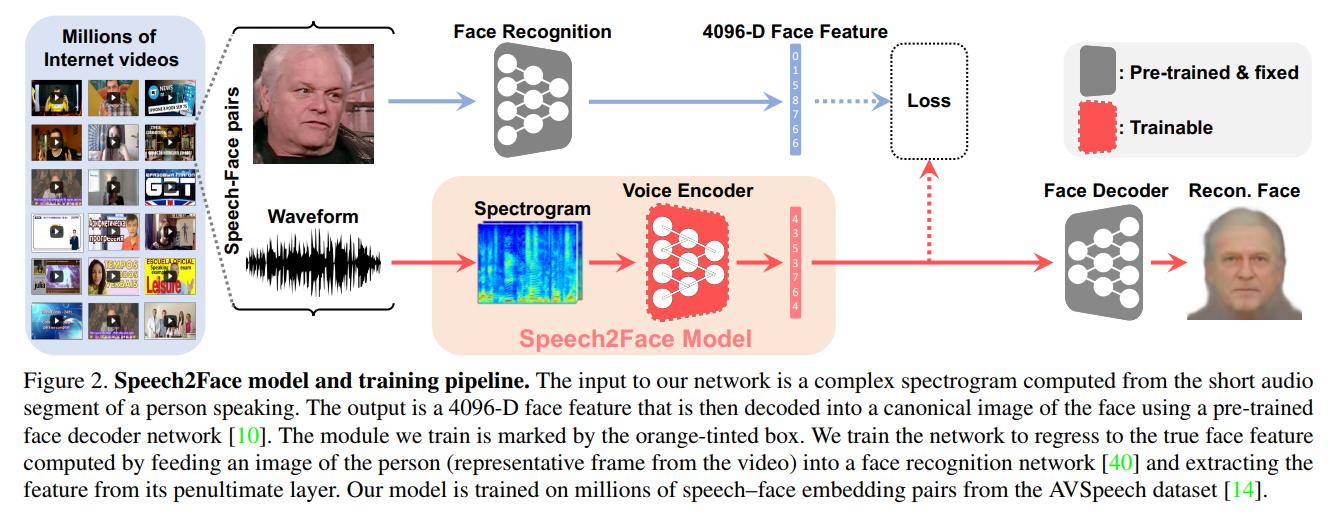
The idea is really simple: You take a pre-trained face synthetiser[1] network. You then train a voice encoder to match its last feature vector \(v_s\) with the face synthesiser \(v_f\). If the two encoders project in a similar space, the face decoder should decode similar faces.
A natural choice for a loss would be the \(L_1\) distance between the \(v_s\) and \(v_f\). However, the authors found that the training was slow and unstable. They, therefore, used the following loss:
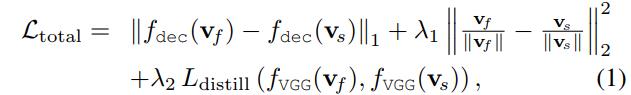
where \(f_{dec}\) is the first layer of the face decoder and \(f_{VGG}\) the last layer of the face encoder.
Data
The authors used the AVSpeech dataset and extracted 1 frame and a 6 seconds audio clip from each video clip. If the video clip was shorter than six seconds, they looped it. The audio clip was then turned into a spectrogram and fed to the speech encoder.
Results
The authors tested both qualitatively and quantitatively their model on the AVSpeech and VoxCeleb dataset.
Qualitative results are available here
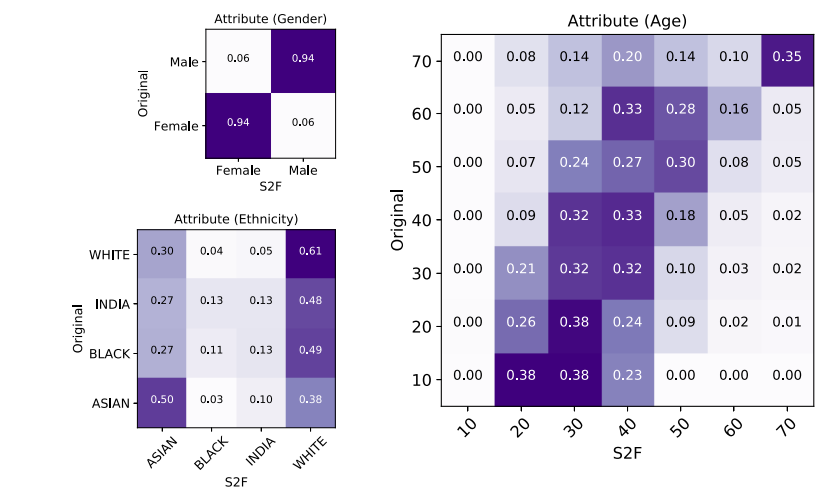
For quantitative results, the authors used Face++ to compare features from the original images and the reconstructed faces. The Face++ classifiers return either “male” or “female” for gender, a continuous number for age, and one of the four values, “Asian”, “black”, “India”, or “white”, for ethnicity. The corresponding confusion matrices are available below
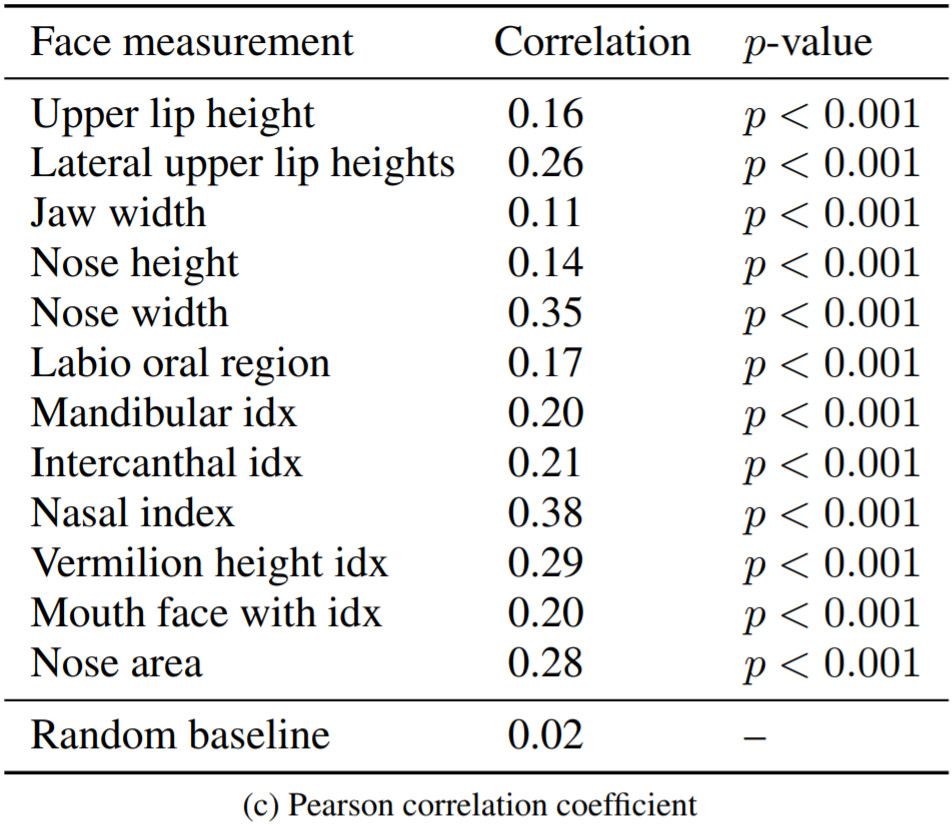
The authors also extracted craniofacial attributes from the reconstructed F2F and S2F images that resulted in a high correlation between the two.

They also performed top-5 recognition to determine how much you could retrieve the true speaker from the reconstructed image.

Supplementary results are aailable here
Conclusions
The authors showed that they can recover physical features from a person’s speech fairly well.
Remarks
The authors stress throughout the paper, including in an “Ethical Considerations” section that a person’s true identity cannot be recovered from this.
To quote the paper:
More specifically, if a set of speakers might have vocal-visual traits that are relatively uncommon in the data, then the quality of our reconstructions for such cases may degrade. For example, if a certain language does not appear in the training data, our reconstructions will not capture well the facial attributes that may be correlated with that language. Note that some of the features in our predicted faces may not even be physically connected to speech, for example, hair color or style. However, if many speakers in the training set who speak in a similar way (e.g., in the same language) also share some common visual traits (e.g., common hair color or style), then those visual traits may show up in the predictions.
A similar paper has also emerged recently from Carnegie Mellon, but in this case, the authors use GANs to generate the images.
The hacker news thread has some interesting discussions, like different physiological features like overbite, size of vocal tracts, etc. could have been predicted instead. Also, the implications of this paper in the field of sociolinguistics; to understand how the model could predict that a certain speaker has a goatee, for example.
References
[1]: Synthesizing Normalized Faces from Facial Identity Features, Cole et. al, 2017