Adversarial Examples Are Not Bugs, They Are Features
Highlights
Authors demonstrate that adversarial examples can be attributed to the presence of non-robust feature: features derived from patterns in the data distribution that are highly predictive, yet brittle and incomprehensible to humans.
Introduction
Adversarial examples are inputs to a deep learning algorithm that have been slightly perturbed to cause unintended behavior or response.
Classifiers are trained to solely maximize (distributional) accuracy. Consequently, classifiers tend to use any available signal to do so, even those that look incomprehensible to humans.
Methods
The research team leveraged standard image classification datasets to show it is possible to disentangle robust from non-robust features.
For any given dataset, they are able to build
- A “robustified” version from robust classification by removing non-robust features from the dataset: standard training yields good robust accuracy on the original, unmodified test set.
- A “non-robust” version for standard classification by adding small adversarial perturbations. Inputs are apparently incorrectly labeled. The input-label association is based purely on non-robust features. Training on this dataset yields good accuracy on the original, unmodified test set.
They define a feature to be a function mapping from the input space to the real numbers; a useful feature is one that is correlated with the true label in expectation; a robust feature is one when perturbed still remains useful; and a useful, non-robust feature is a useful feature, but not a robust one.
Useful features:
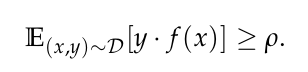
Robust features:
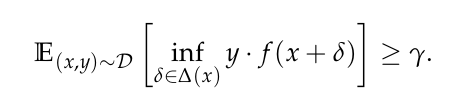
These useful, non-robust features help with classification in the standard setting, but may hinder accuracy in the adversarial setting.
In a standard classification task, there is no distinction between robust and non-robust features when minimizing the loss. The classifier will use any useful feature to decrease the loss.
In the presence of an adversary, useful but non-robust feature may be anti-correlated with the true label, and the general loss minimization strategy is no longer sufficient for proper robust training.
So authors define a adversarial loss function that can distinguish between robust and non-robust features. Minimizing this loss can be viewed as preventing the classifier from learning useful but non-robust features.
Experiments
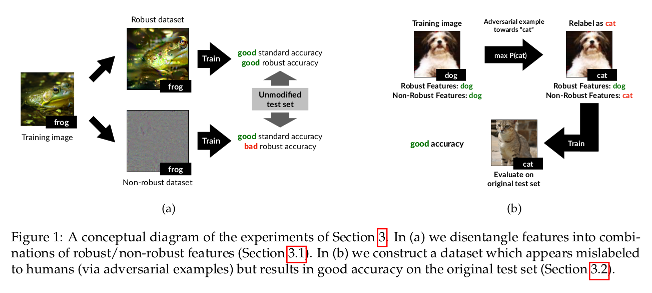
Disentangling robust and non-robust features
Since high-dimensional, complex features cannot be directly manipulated, they leverage a robust model and modify the dataset to contain only the features that are relevant to that model.
They use the set of activations in the penultimate layer to build a mapping for each input image to the set of robust images. They enforce the features maps to be similar for the original images and their robust versions.

Given the new, robust training data set, they train a standard classifier using standard (non-robust) training, and test it on the original test set.
As a control, they use a standard (non-robust) classifier on the non-robust dataset.
The adversarial-training methodology is based on 1.
Non-robust features suffice for standard classification
They construct a non-robust dataset where the only features that are useful for classification are non-robust features.
To accomplish this, they modify each input-label \((x,y)\) pair selecting some target class \(t\). Then, they add a small adversarial perturbation to \(x\) in order to ensure it is classified as \(t\) by a standard model.
Now, since \(\vert \vert x_{adv} - x \vert \vert\) is small, by definition the robust features of \(x_{adv}\) are still correlated with class \(y\) (and not \(t\)). After all, humans still recognize the original class.
And since every \(x_{adv}\) is strongly classified as \(t\) by a standard classifier, it must be that some of the non-robust features are now strongly correlated with \(t\) (in expectation).

Results
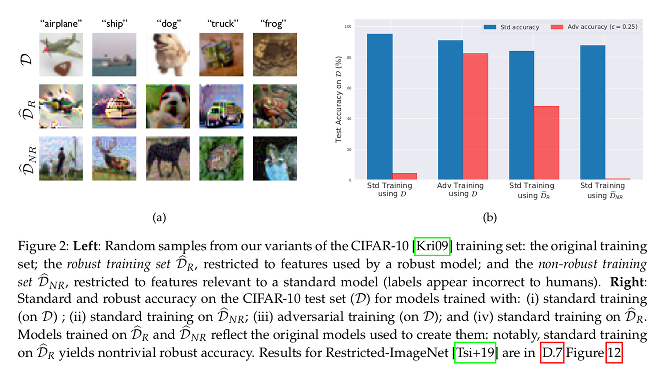
-
By restricting the dataset to only contain features that are used by a robust model, standard training results in classifiers that are robust.
-
When training on the standard dataset, non-robust features take on a large role in the resulting learned classifier.
-
They also show that transferability in adversarial attacks can arise from non-robust features.
Conclusions
By filtering out non-robust features from the dataset (e.g. by restricting the set of available features to those used by a robust model), one can train a robust model using standard training.
According to these findings, adversarial vulnerability is not necessarily tied to the standard training framework, but is rather a property of the dataset.
Authors conclude that the adversarial vulnerability is a direct result of our models’ sensitivity to well-generalizing features in the data.
Their findings lead them to view adversarial examples as a fundamentally human phenomenon.
They prove it by explicitly disentangling robust and non-robust features in standard datasets, as well as showing that non-robust features alone are sufficient for good generalization.
References
A few interesting posts that explain the main findings of the article:
Artificial Intelligence may not ‘hallucinate’ after all - wired.com
Adversarial Examples Aren’t Bugs, They’re Features - syncedreview.com
-
Aleksander Madry et al. “Towards deep learning models resistant to adversarial attacks”. In: International Conference on Learning Representations (ICLR). 2018. ↩