Challenging Common Assumptions in the Unsupervised Learning of Disentangled Representations
A major goal of unsupervised representation learning is to learn disentangled representations. Basically, we want to disentangle each underlying property of the subject, so that, ideally, each property is assigned its own axis in the latent space. Crucially, we want to avoid having two or more properties entangled in a single axis.
In this large scale study, the authors evaluate six state-of-the-art models and six disentanglement metrics. In total, they train and evaluate 12,800 models on seven data sets.
Example
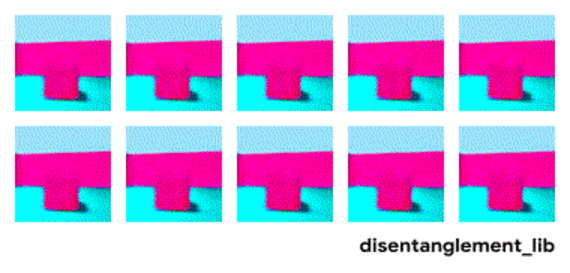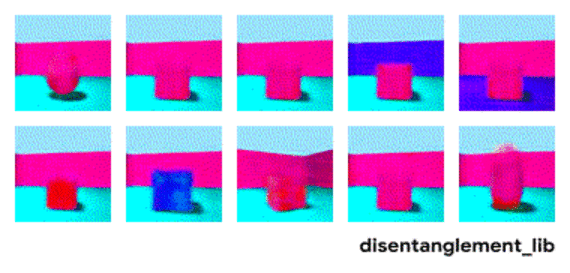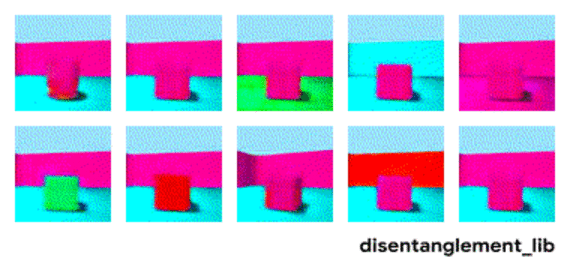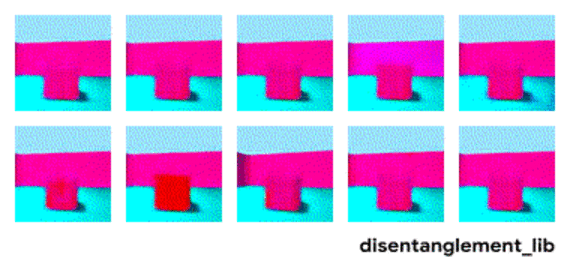
3dshapes is a dataset of images containing one 3D shape in a simple environment. The goal of this dataset is to be a benchmark for disentanglement. Below is an animation describing all six latent factors:
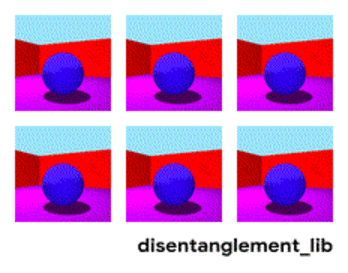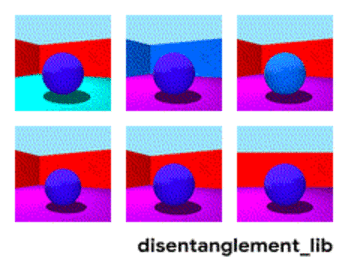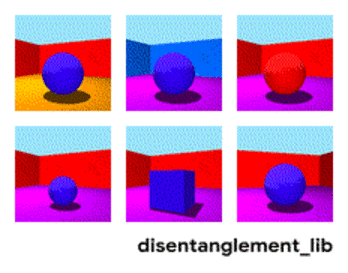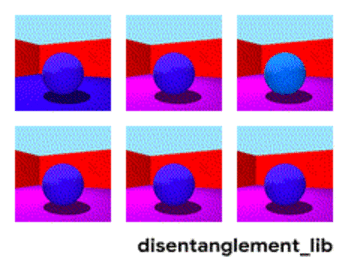
We would like to have a representation learning method that could produce results similar to the figure above. However, current methods have not solved this problem, and can produce results like below. Notice the entangled factors on the left (e.g. size and color):
Key Findings
Following this large scale study, the authors…
- …did not find evidence that the six models can reliably learn disentangled representation without supervision. Even if such representation can be obtained, they cannot be identified without access to ground-truth labels.
- …present a theorem that states the following: “unsupervised learning of disentangled representations is impossible without inductive biases on both the data set and the models”. In other words, assumptions about the data have to be incorporated in the model.
- …could not validate the assumption that disentanglement is useful for downstream tasks.
- …found that hyperparameters do not transfer across tasks, and are less important than random seeds (see figure below).
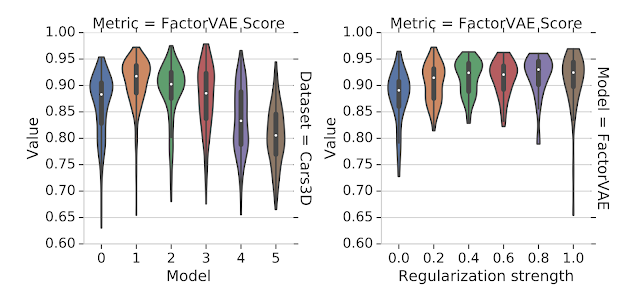
Observations relevant to future research
- Since inductive biases are necessary, future work should clearly describe the ones they use;
- Finding inductive biases that work across datasets is a key open problem;
- Practical benefits of disentanglement should be demonstrated;
- Experiments should be conducted in a reproducible experimental setup on a diverse selection of data sets.
For this last point, the authors release their disentanglement_lib to the community.