ENet: A Deep Neural Network Architecture for Real-Time Semantic Segmentation
Idea
Recent deep neural networks aimed at real-time pixel-wise semantic segmentation task have the disadvantage of requiring a large number of floating point operations and have long run-times that hinder their usability. In this paper, they authors propose a new deep neural network architecture named ENet for efficient neural network, created specifically for tasks requiring low latency operation. They claim that the ENet is up to 18×faster, requires 75×less FLOPs, has 79×less parameters, and provides similar or better accuracy to existing models like the SegNet. They have tested it on CamVid, Cityscapes and SUN datasets.

Network
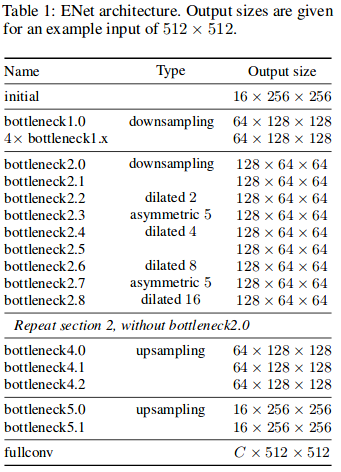
The architecture of this network is in the table below. It is divided into several stages, as highlighted by horizontal lines in the table and the first digit after each block name.
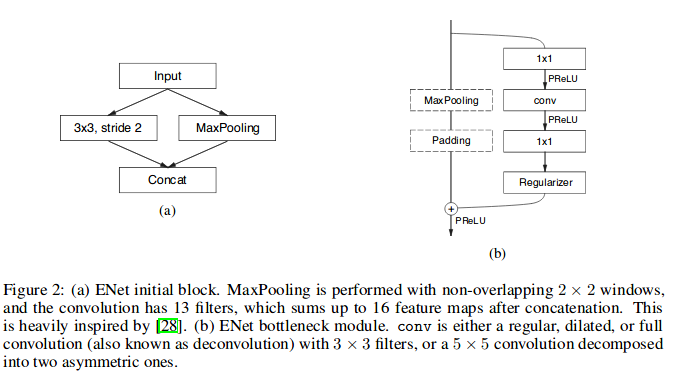
They adopt a view of ResNet that describes them as having a single main branch and extensions with convolutional filters that separate from it, and then merge back with an element-wise addition. Each block consists of three convolutional layers: a 1x1 projection that reduces the dimensionality, a main convolutional layer (conv in figure bellow), and a 1x1 expansion. A Batch Normalization and PReLU are also used between all convolutions. Just as in the original paper of the original ResNet paper, they refer to these as bottleneck modules. If the bottleneck is downsampling, a max pooling layer is added to the main branch.
The first three stages are the encoder and stage 4 and 5 belong to the decoder.
Also, the first 1x1 projection is replaced with a 2x2 convolution with stride 2 in both dimensions.
conv (convolution) is either a regular, dilated or full convolution (also known as deconvolution or fractionally strided convolution) with 3x3 filters.
For the regularizer, they use Spatial Dropout, with p= 0.01 before bottleneck 2.0, and p= 0.1 afterwards.
The initial stage contains a single block, Stage 1 consists of 5 bottleneck blocks, while stage 2 and 3 have the same structure, with the exception that stage 3 does not downsample the input at the beginning (they omit the 0th bottleneck).
They did not use bias terms in any of the projections, in order to reduce the number of kernel calls and overall memory operations, as cuDNN uses separate kernels for convolution and bias addition. This choice didn’t have any impact on the accuracy. Between each convolutional layer and following non-linearity they use Batch Normalization. The decoder maxpooling is replaced with max unpooling, and padding is replaced with spatial convolution without bias. They did not use pooling indices in the last upsampling module, because the initial block operated on the 3 channels of the input frame, while the final output has C feature maps (the number of object classes). Also, for performance reasons, they decided to place only a bare full convolution as the last module of the network, which alone takes up a sizeable portion of the decoder processing time.
In section 4 of the article, they justified every decision about every part of the network, for more information see this section.
Results
Inference Time
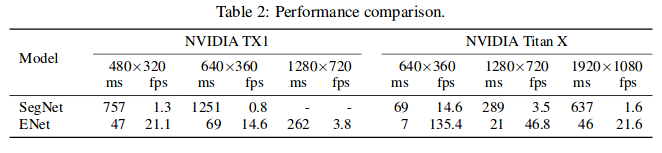
The table below compares inference time for a single input frame of varying resolution. They also report the number of frames per second that can be processed. Dashes indicate that they could not obtain a measurement, due to lack of memory. ENet is significantly faster than SegNet, providing high frame rates for real-time applications and allowing for practical use of very deep neural network models with encoder-decoder architecture.
Hardware Requirements
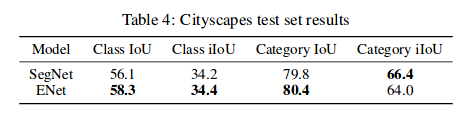
The table below reports a comparison of floating point operations and parameters used by different models. ENet efficiency is evident, as its requirements are on two orders of magnitude smaller. They report that the storage required to save model parameters in half precision floating point format. ENet has so few parameters, that the required space is only 0.7MB, which makes it possible to fit the whole network in an extremely fast on-chip memory in embedded processors. Also, this alleviates the need for model compression, making it possible to use general purpose neural network libraries. However, if one needs to operate under incredibly strict memory constraints, these techniques can still be applied to ENet as well.

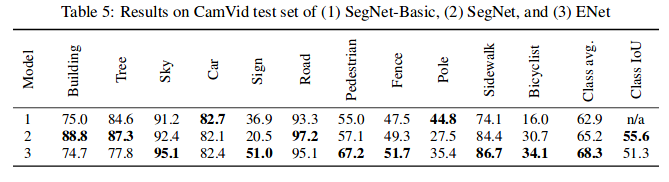
Benchmarks