Deep Neural Networks Improve Radiologists' Performance in Breast Cancer Screening
Introduction
“Breast cancer is the second leading cancer-related cause of death among women in the US. Early detection, through routine annual screening mammography, is the best first line of defense against breast cancer. […] A radiologist can spend up to 10 hours a day working through these mammograms, in the process experiencing both eye-strain and mental fatigue.”
The authors propose a deep-learning method leveraging both pixel-level and patch-level precision that is as accurate as ensembles of radiologists. They also provide a new dataset that was used to train the proposed model.
Dataset
Two challenges arise in breast cancer detection. One, the most commonly used mammography dataset contains only about 10 000 images. Second, mammography images are very high resolution (around 2000x2000). Prior work shows that downsampling these images can significantly hurt performance of computer vision models, so it is not a viable option.
The authors introduce the NYU Breast Cancer Screening Dataset (BCSD), consisting of ~230 000 screening mammography exams from ~150 patients, each exams consisting of four images (CC and MLO views of left and right breasts).
From these 230 000 exams, 7000 biopsies were performed and the results were annotated by radiologists.
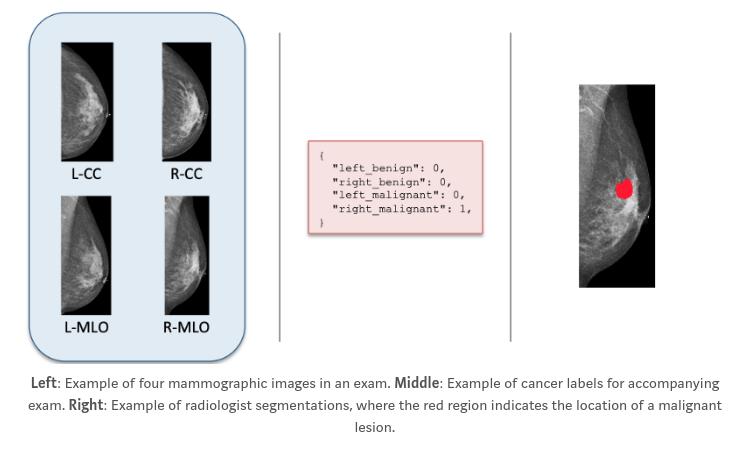
From this dataset, around 8% had malignant findings and 46% benign findings.
Model
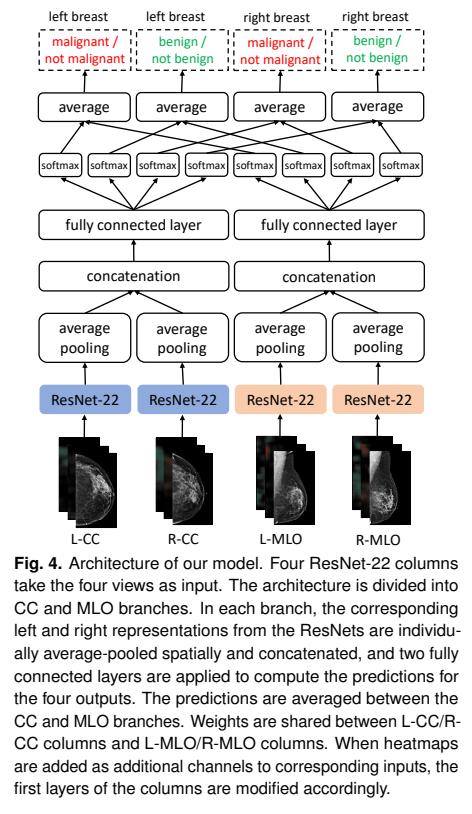
The authors used (only) ResNet-22 because of the size of the images and their available power (four Nvidia V100). To alleviate the size problem, the authors generated heatmaps of benign and malign findings by applying a patch classifier in a sliding window classifier across the entire mammogram.
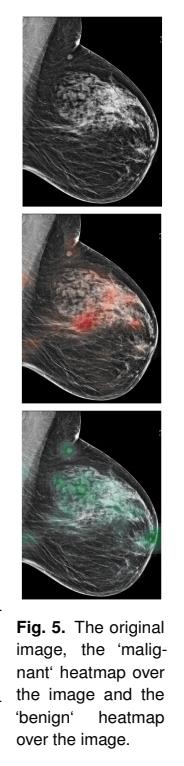
The patch classifier is a DenseNet-121 trained on 256x-256-sized patches and supposedly works “exceedingly well” with no actual results presented.
Results
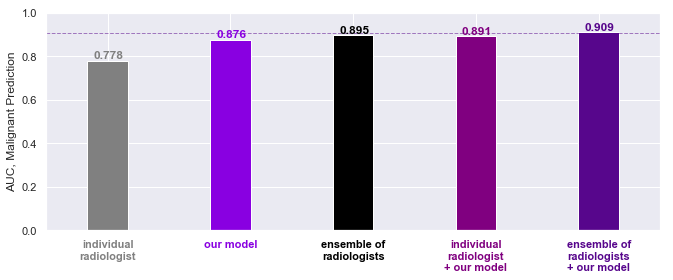
Since the above diagrams are way too cluttered, here is some clearer results from the blog post: