Unsupervised Domain Adaptation using Feature-Whitening and Consensus Loss
Summary
In this paper, the authors propose a domain adaptation method to train a deep neural net on a labeled source dataset and yet get good results on a target dataset whose visual domain is shifted WRT the one of the source dataset. The main novelty is a so-called Domain-specific Whitening Transform (DWT) as well as a Min-Entropy Consensus (MEC) loss which account for both the labeled source data and the non-labeled target data. The method is illustraed in Fig.1.
Proposed method
Domain-specific Whitening Transform (DWT)
For the DWT, they replace the usual Batch Norm
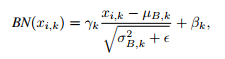
by a new Batch Whitening operation:
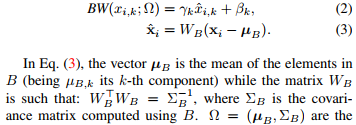
The goal of the BW is to project the feature space of both target and source distributions onto a common zero-centered hypersphere.
Min-Entropy Consensus Loss
The second contribution of this paper is the Loss which they minimize :
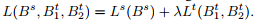
Where the first term is the usual cross-entropy over the labeled source training data
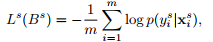
whereas the second term is the Min-Entropy Consensus (MEC) Loss which is intended for the target data
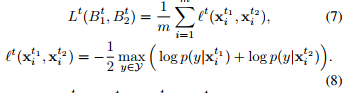
Since the target data are unlabeled, the goal of that loss is to make sure that the prediction of two identical batches \(B_1^t\) and \(B_2^t\) more or less some noise are identical.
Results
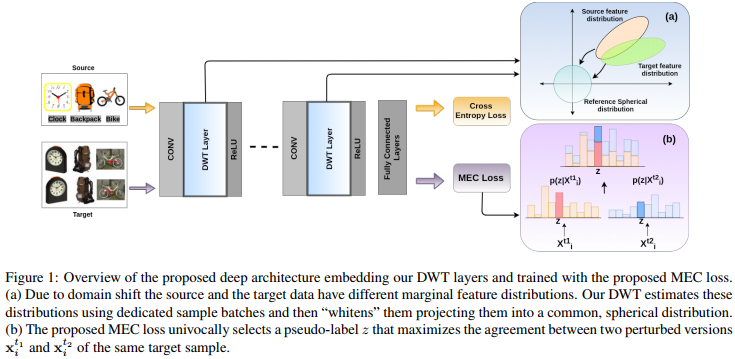
The method is state-of-the-art on several source-tardet dataset pairs: