PlaNet: Learning Latent Dynamics for Planning from Pixels
Model-based Reinforcement Learning (RL) has the agents learn the dynamics of their environment. This then allows the agent to plan ahead to find the optimal route instead of relying on a learned policy, which is more of a black-box approach.
PlaNet learns a world model (the dynamics) from image inputs only and then leverages it for planning. The authors claim to be able to almost achieve state of the art results in model-free RL while being 5000% sample efficient.

How it works
PlaNet learns a dynamics models given input images. Instead of planning directly on observed images (therefore trying to plan what the next image will be), the agent plans on a latent representation of the hidden state.
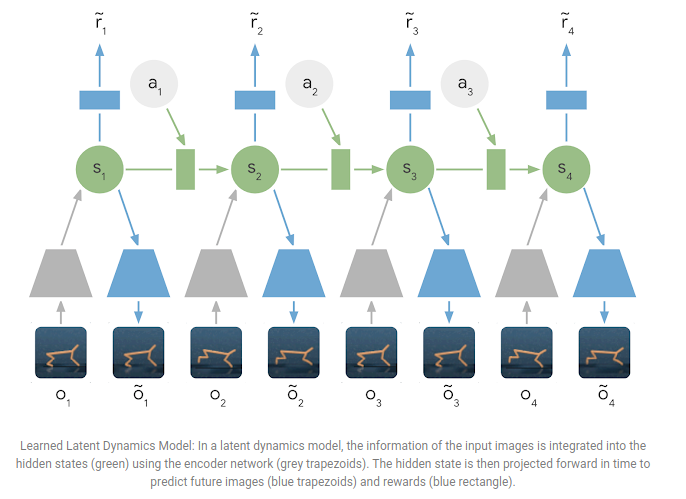
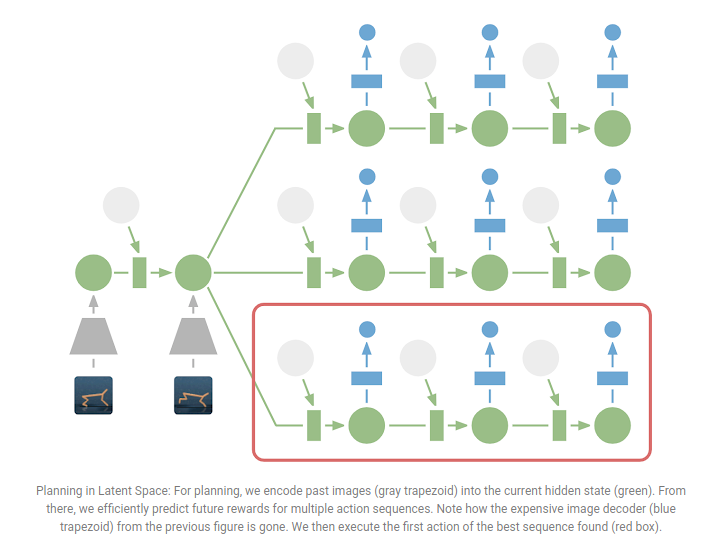
However, encoding and decoding the images is expensive since thousands of timesteps over several trajectories need to be calculated to provide good planning. The authors therefore skip this step and only plan using the predicted rewards and encoding only past observations.

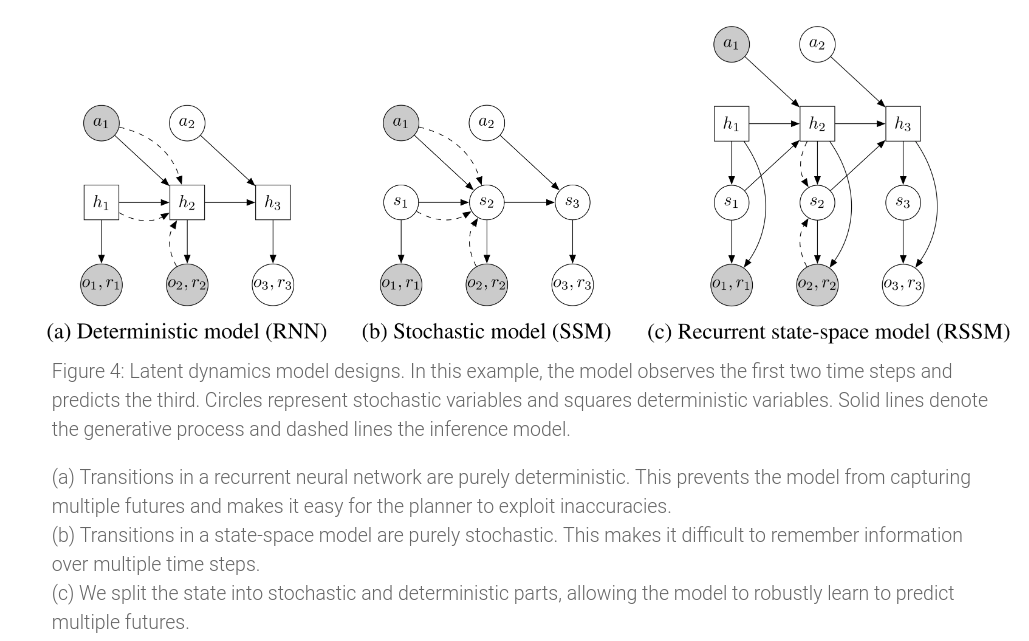
Recurrent State Space Model
To plan ahead, the authors use a Recurrent State-Space Model (RSSM) that predicts purely in latent space. This model includes both stochastic and deterministic paths in the transition model.
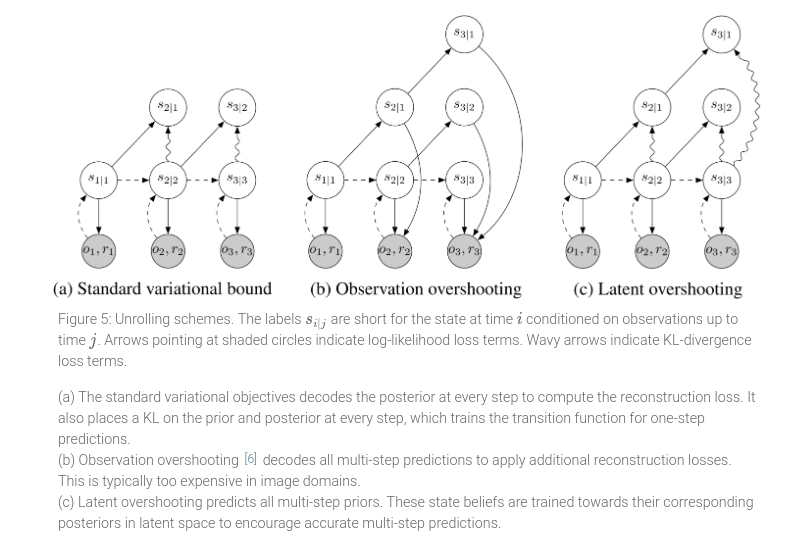
Latent Overshooting
If you could plan using perfect one-step prediction, it is easy to convince yourself that you could do perfect multi-step planning. However, since the authors only have an imperfect model, they need to train it to make multi-step predictions.
whereas the KL-divergence and likelihood terms are described here:
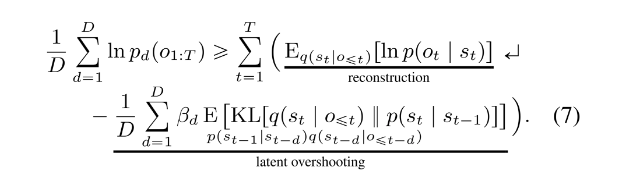
Latent overshooting can be interpreted as a regularizer in latent space that encourages consistency between one-step and multi-step predictions, which we know should be equivalent in expectation over the data set.
Results