Diversity in Faces
Introduction
Facial recognition algorithms have recently reached incredible accuracy. However, it is a well-known fact that neural networks learn what they are taught. What if what they were taught was biased, was not representative of the diversity in the human race? To build fair and accurate models, the training data used must provide sufficient coverage and balance. But what is sufficient coverage?
Prior work
In the past, most database focused on simple attributes such as age, skin tone and gender. However, there is an evergrowing sentiment that these characteristics alone are not enough. Also, most datasets are severely imbalanced towards middle-aged white males.
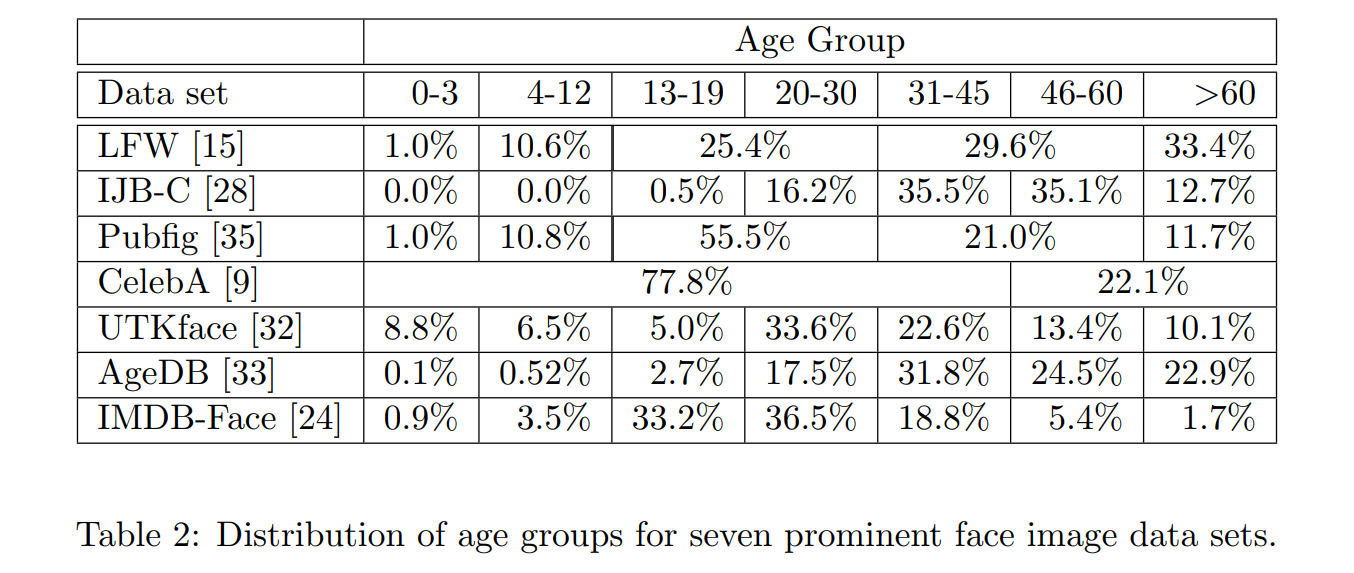
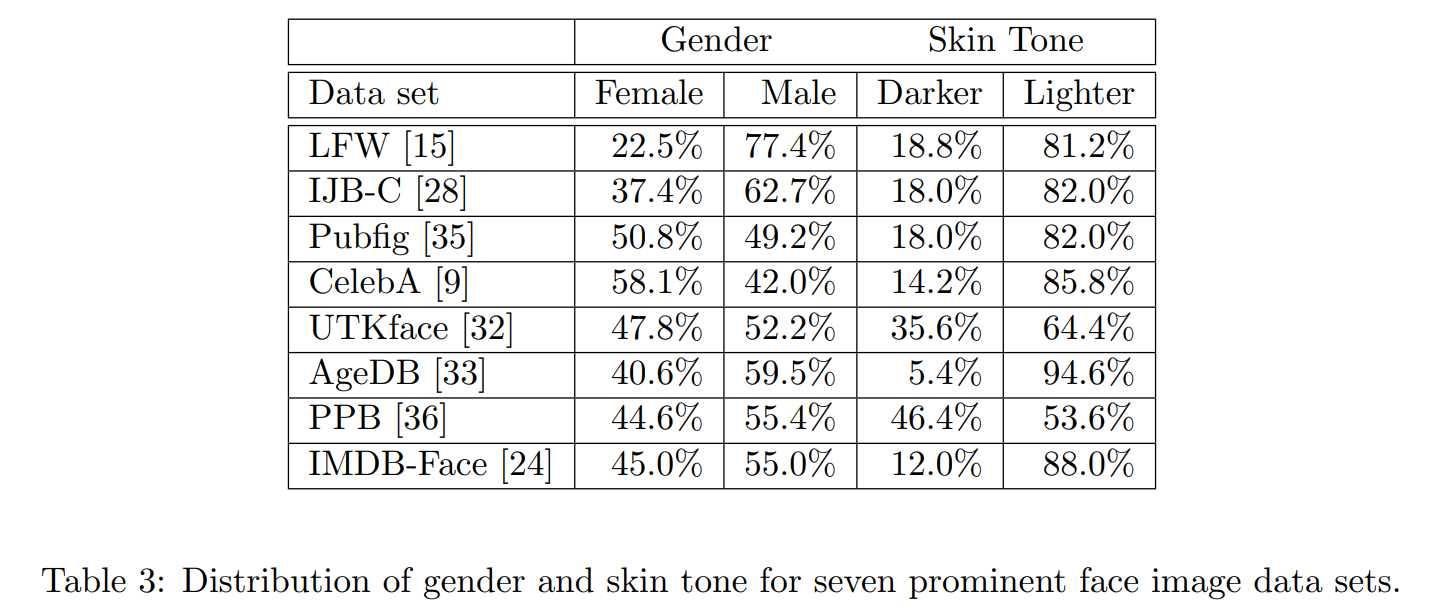
Chosen features
Are age, gender and skin tone sufficient? What about other highly personal attributes that are part of our identity, such as race, ethnicity, culture, geography, or visible forms of self-expression that are reflected in our faces in a myriad of ways? Is it even still relevant to represent gender as a binary attribute?
Instead of trying to answer these questions, the authors focused on biological traits present in faces. These traits, or coding schemes, have been chosen for their strong scientific basis as evidenced by highly cited work, while ensuring that extracting these coding schemes was computationally feasible, making sure that the values provided were continuous instead of categorical and that these values would be interpretable by a human.
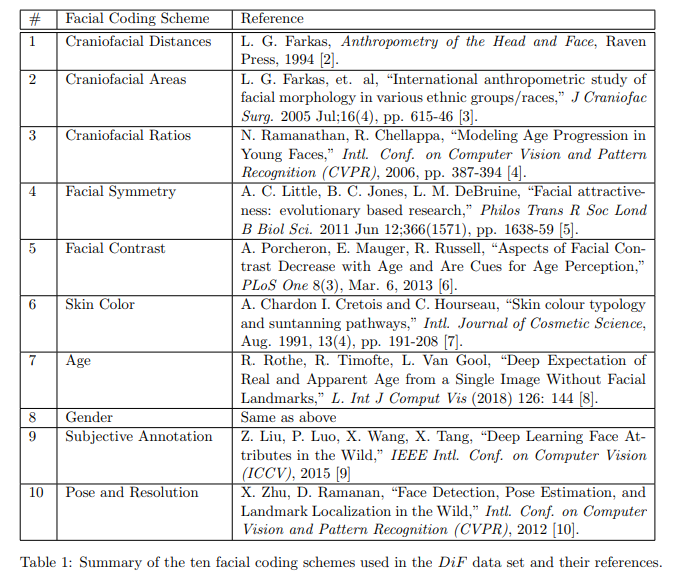

Feature acquisition
Below are some examples of how coding schemes were extracted. Some other coding schemes were acquired via crowdsourcing and/or predictions from a CNN trained specifically to recognize the characteristic. While the images in the real dataset were subsampled from YFCC-100M, the below images use a synthetic face generated by a GAN.
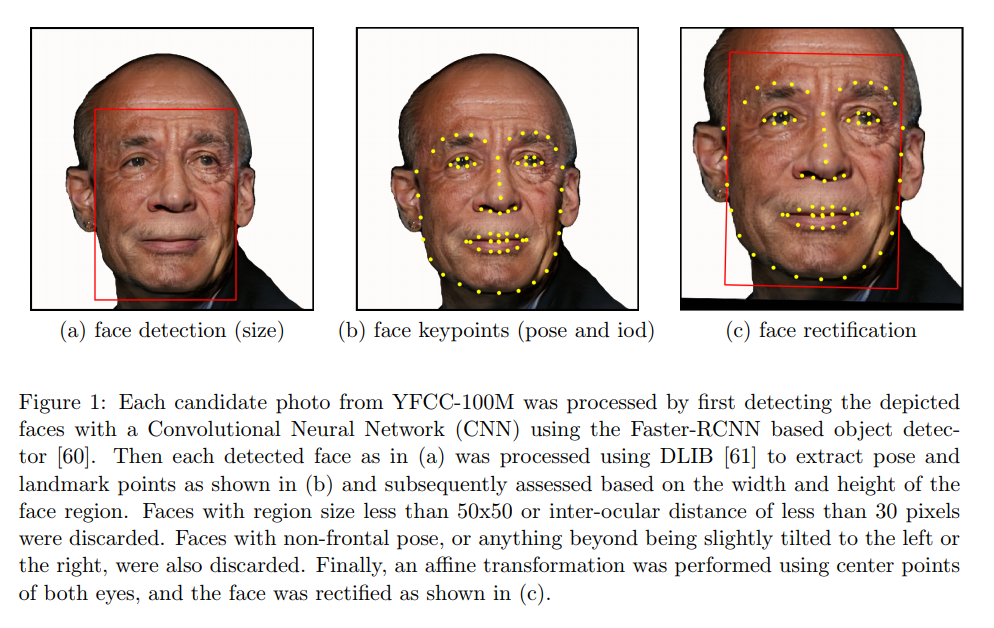
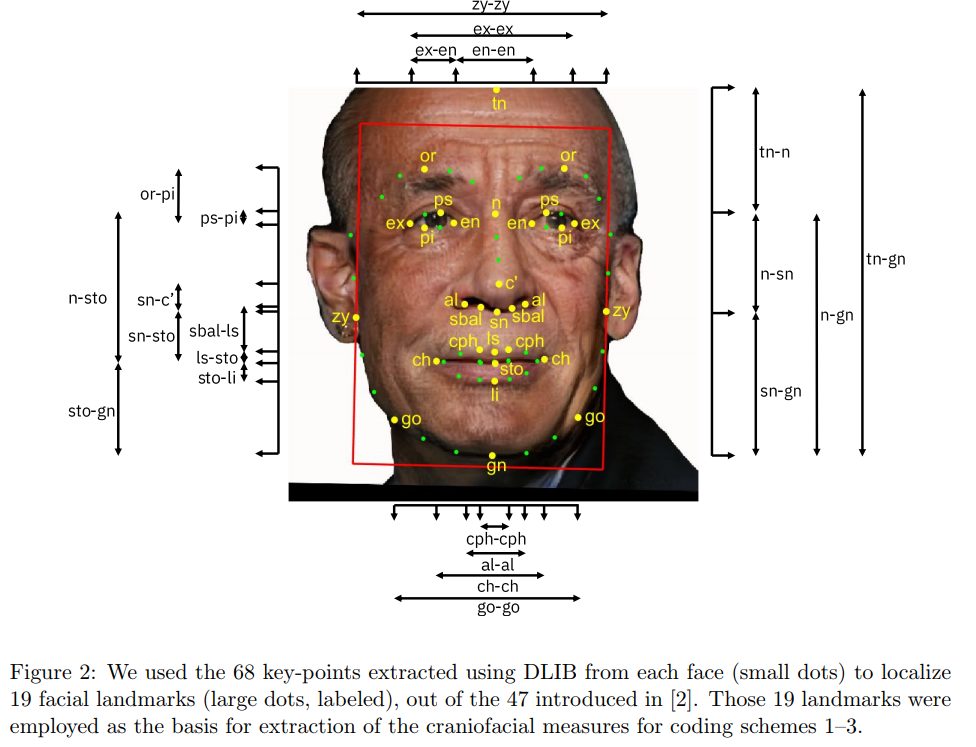

Diversity
Of course, the authors wanted to ensure that their newly created dataset was diverse enough. To do so, they calculated the diversity and evenness of their characteristics according to these metrics:
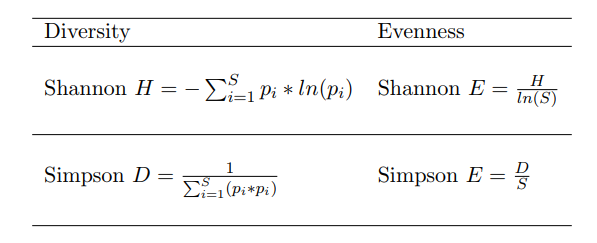
Generally, a higher diversity and an evenness closer to 1 are preferable.
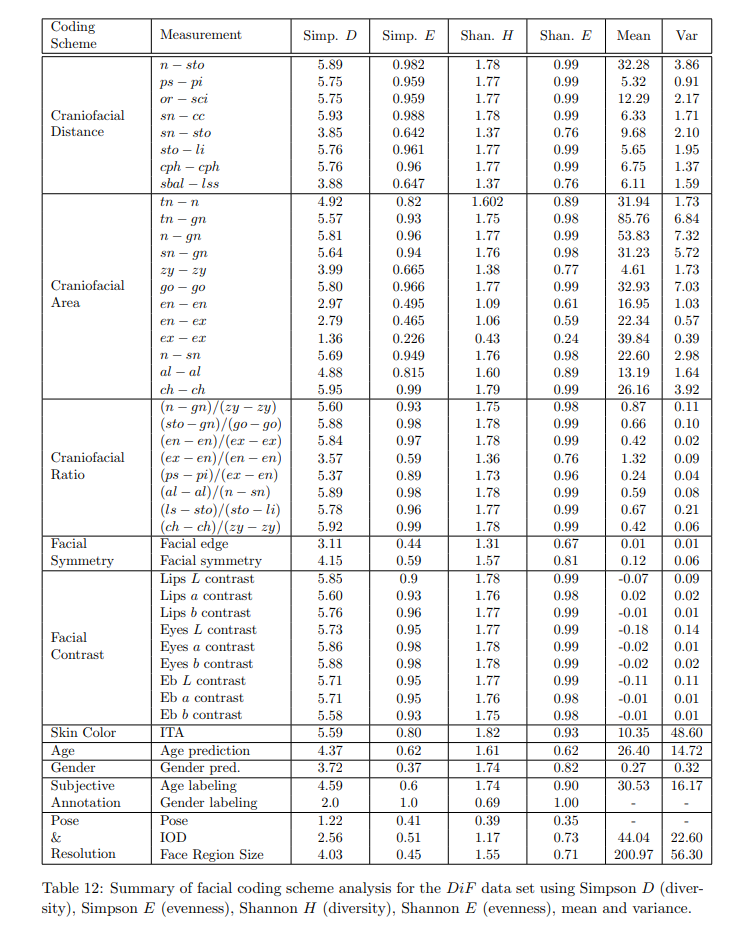
Because reading the whole table above would be painful, here is the gist of it: Individual measurements seem to have higher diversity and evenness than the feature (age, gender, race) they represent.