Character-level Convolutional Networks for Text Classification
The authors propose to encode a text string as a binary matrix, where one-hot representations of characters are stacked together, in order to feed it to a convolutional network for classification. They compare this approach to word-based methods, such as bag of words, n-grams, TFIDF, and LSTM.
Method
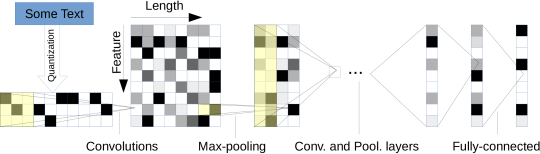
- Text Quantization: A string of text is converted to a binary image. Each column encodes a character. They use a set of 70 characters, which implies that their input images have a height of 70 pixels. They use a fixed sequence length of 1014 (they do not study the impact of this hyperparameter). It seems that they take a crop of 1014 from the input text, but they don’t give any details about this (they don’t say if they always take the 1014 first characters).
- Kernel sizes: The first two convolutions have a kernel size 7, an the remaining 4 convolutions are size 3.
- Temporal max-pooling: At 3 places in the network, they apply a temporal max-pooling with a stride/window of 3. This progressively reduces the length of the sequence representation, without affecting the number of features.
- Synonyms augmentation: They perform a data augmentation where they replace words with their synonyms. More details in the paper.
- Uppercase and Lowercase: In most cases, avoiding a distinction between uppercase and lowercase yields better performance. Avoiding the distinction works better for less-clean datasets.
Results
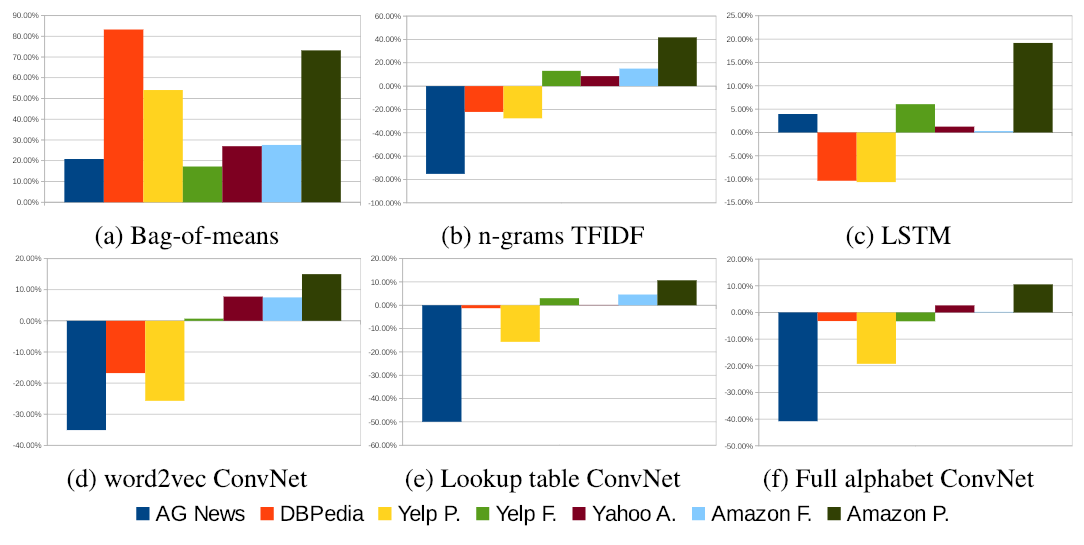
The following figure presents the relative error of other methods in comparison to the proposed method (for each dataset). We can see that the first 3 datasets are better tackled with previous methods, while the last 4 datasets seem to be better handled by the proposed method. The authors state that their method overperforms previous methods on less-curated, user-generated data.