A Style-Based Generator Architecture for Generative Adversarial Networks

Summary
This paper presents a ground breaking generative neural network that produces the most realistic images of human faces ever. The secret of their method resides roughly in three main improvements over a Baseline Progressive GAN (which happens to be a 2017 paper from the same authors[1]) on top of careful tuning of the baseline method. The loss of the network is a common WGAN loss. The proposed method is well illustrated in fig.2.
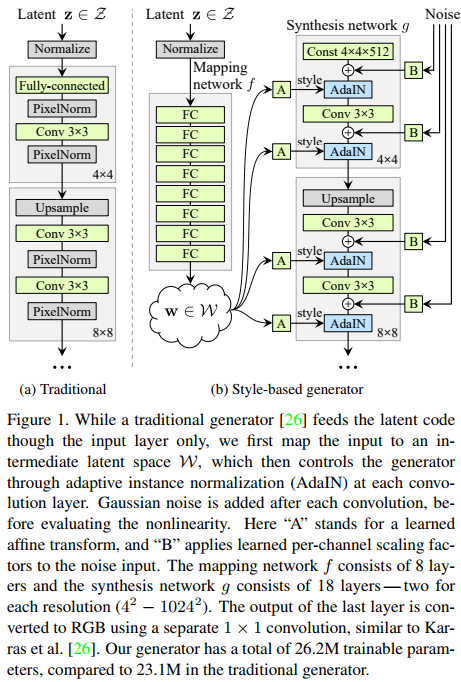
Proposed method
The main contributions of this paper are threefold:
- Latent space projection: Instead of feeding their decoder network with a random sample \(z^{512}\) from a latent space \(Z\), they first project \(z\) to a new space \(W\) also of 512 dimensions. Projection is done with a 8 layer MLP. They argue that this non-linear projection allows \(W\) to be a better and yet disentangled latent space.
- Style transform: the recovered vector \(w\) is then fed to a series of learned affine transformations which predicts a style vector \(y = (y_s, y_b)\)
that control an adaptive instance normalization (AdaIN) operation:
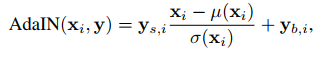
- Noise: the system feeds noise to the input of each AdaIN operation. While noise does not affect the overall appearance, it nonetheless affects small details like finer curls of hair, finer background detail, and skin pores and thus prevent “painterly” looking results. The effect of noise is illustrated in Fig.4.

Authors also show that the latent vector \(w\) of more than one image can be combined together to produce mind-blowingly accurate facial combinations.

They also showed that their method was successful at producing other types of images such as bedrooms and cars.

References
[1] T. Karras, T. Aila, S. Laine, and J. Lehtinen. Progressive growing of GANs for improved quality, stability, and variation. CoRR, abs/1710.10196, 2017.