PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
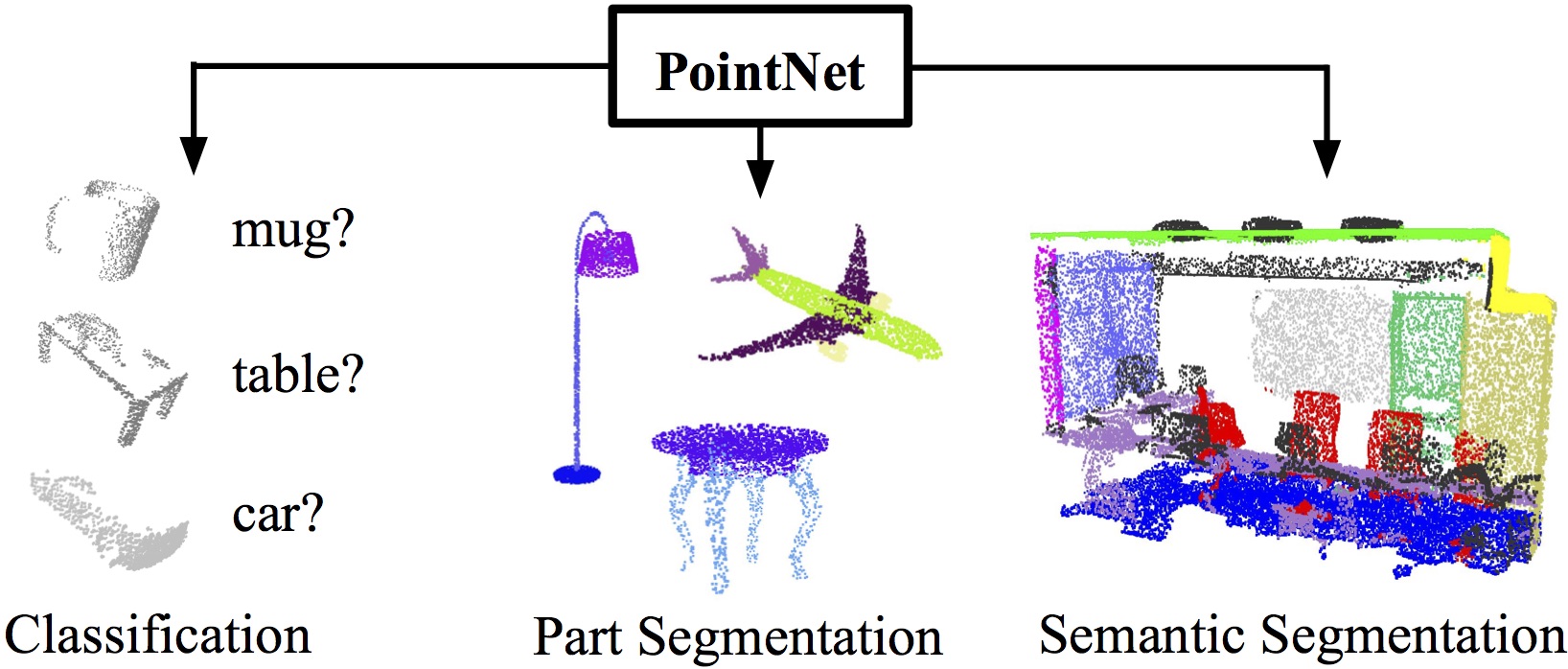
A neural net for classification and segmentation of point clouds.
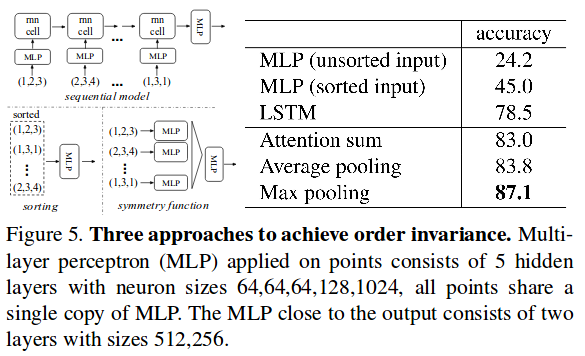
The PointNet Architecture
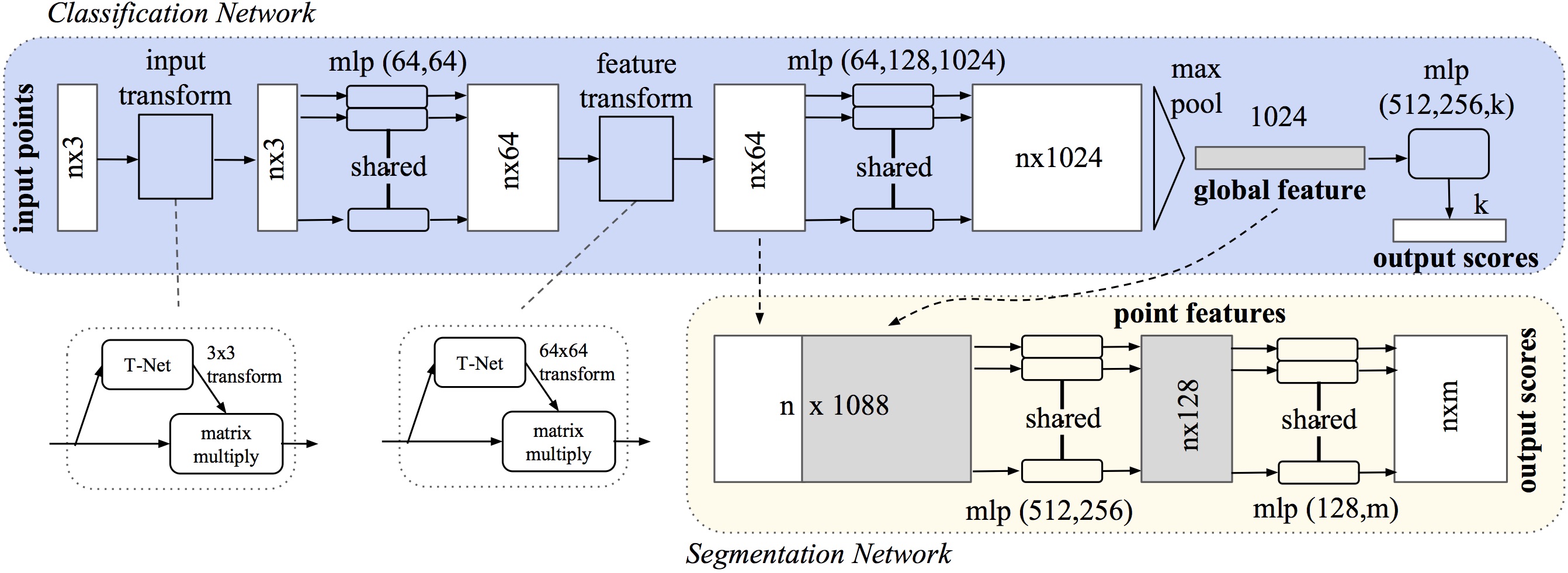
- Sequence of point-wise MLPs
- Sub-networks for data-dependent transforms (T-Net)
- Max-pooling at the end for a global feature vector
- Concatenate local feat-vect with global feat-vect for segmentation
Pros
- Learns to summarize a shape by a sparse set of key points
- Robust to missing points
- No voxelization, no rasterization, no convolution
- End-to-end learning (no hand-crafted features)
- Supports N-dimensional points (e.g. spatial + color)
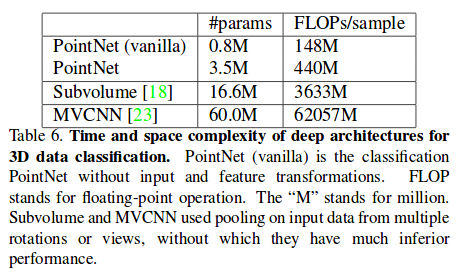
- Low-complexity
Cons
- Slightly worse than “Multi-view CNN” (which generates 2D projections of the point cloud)
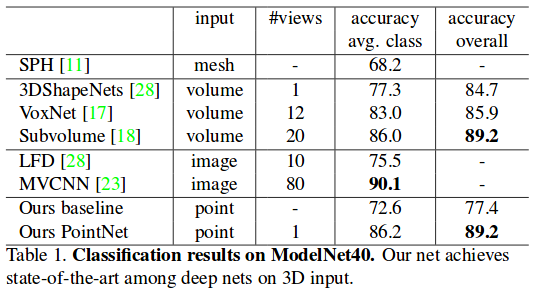
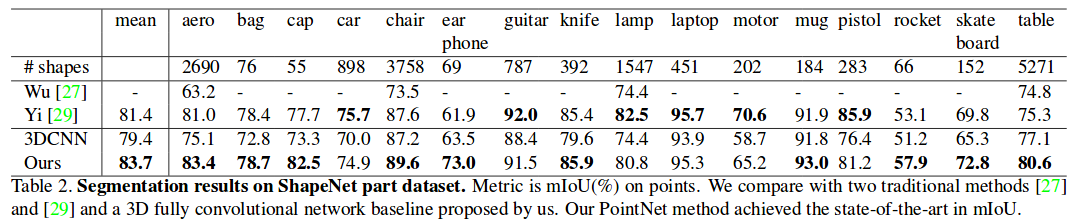
Results
Qualitative results
Part Segmentation Results. We visualize the CAD part segmentation results across all 16 object categories. We show both results for partial simulated Kinect scans (left block) and complete ShapeNet CAD models (right block).

Semantic Segmentation Results. Top row is input point cloud with color. Bottom row is output semantic segmentation result (on points) displayed in the same camera viewpoint as input.

Visualizing Critical Points and Shape Upper-bound. The first row shows the input point clouds. The second row shows the critical points picked by our PointNet. The third row shows the upper-bound shape for the input – any input point sets that falls between the critical point set and the upper-bound set will result in the same classification result.

Quantitative results