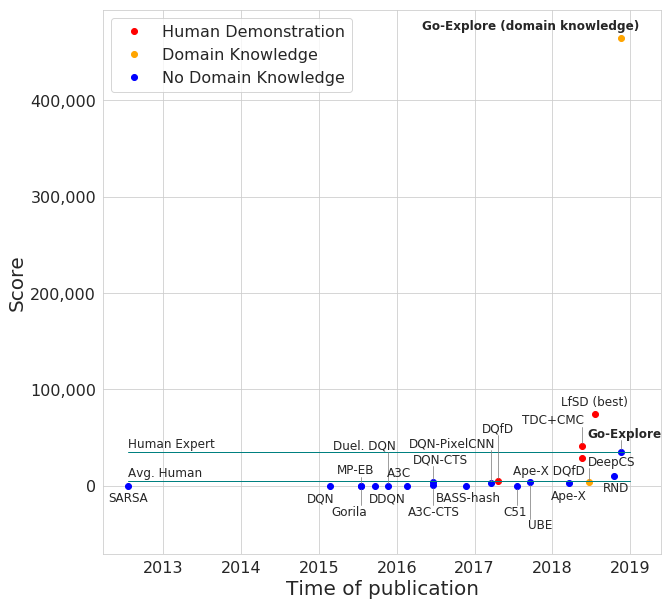
Go-Explore
Go-Explore is a novel family of RL algorithms achieving an average score of 400,000 on Montezuma’s Revenge, a notoriously difficult environment. The previous state-of-the-art algorithm gets an average score of 11,347. Go-Explore can reliably solve the game, while previous methods rarely completed the first level.
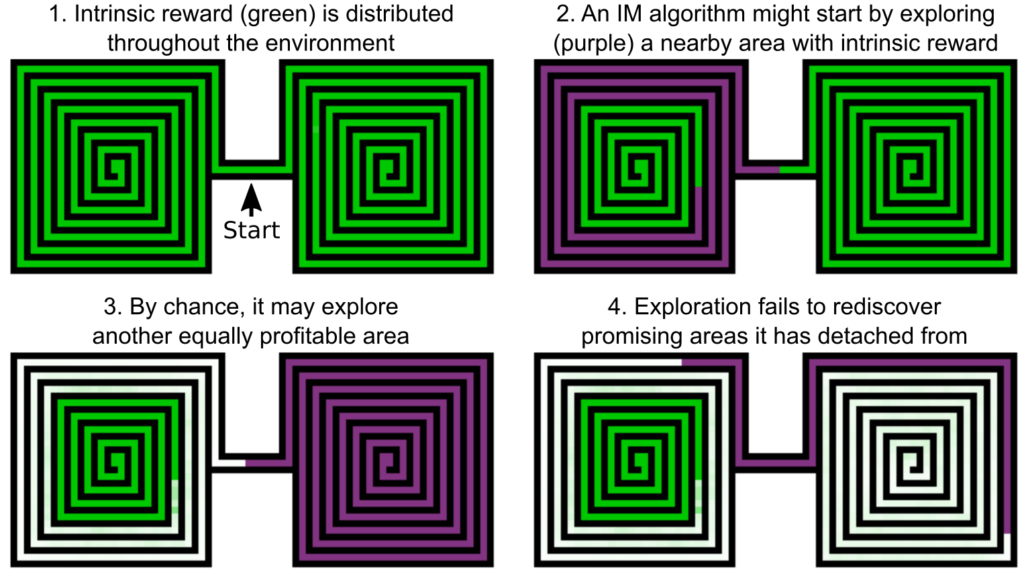
Detachment 😐
The authors hypothesize that the problem of “detachment” is a major weakness that prevented the previous methods from solving the task. One way of foster exploration is to give a bonus when the agent sees new stuff. However, sometimes agents discover hard-to-reach states, but don’t fully explore this “promising” area. Because they already have seen this trajectory, they might not find it “interesting” enough to return to the promising area to continue exploring, and potentially reach rewarding states.
Go-Explore

The algorithm is articulated around generating the best possible trajectories, and using imitation learning on them. A “cell” is a set of similar states, to which an agent might return (more on that later).
Phase 1:
- Choose a cell from the archive probabilistically (optionally prefer promising ones, e.g. newer cells)
- Go back to that cell (by resetting emulator to a saved state)
- Explore from that cell (e.g. randomly for n steps)
- For all cells visited, if the new trajectory yields higher score, swap it in as the trajectory to reach that cell (reminds me of Dijkstra)
- Return to 1 until solved.
Phase 2:
Using trajectories to solve environments only work for deterministic environments, which is not the case of Atari. The current benchmark for Atari games requires test-time to be stochastic. To allow solving the stochastic task, imitation learning is used, with the trajectories from phase one as the demonstrations.
Cell representation
To allow trajectories to have cells in common, a good state representation must be used. The authors show that using a downscaled (8x11) and quantized (8 grayscale intensities) version of the current game frame works well.

However, by using a hand-crafted cell representation, results are improved dramatically. (Note: The method is SotA even without this domain knowledge.) The hand-crafted representation contains the \((x,y)\) position of the agent, the current room, the current level, and the current number of keys held. This information is extracted from pixels.
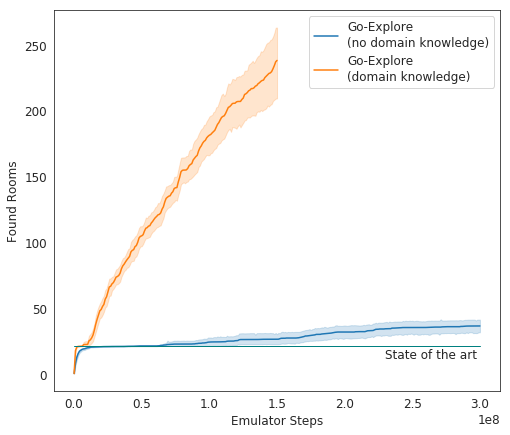
Results that say “BAMF”
Notice that Go-Explore w/o domain knowledge equals expert human performance.