From Recognition to Cognition: Visual Commonsense Reasoning
Introduction
Semantic understanding of an image goes well beyond object detection: By looking at a picture, we can infer relationships between objects, understand what happened prior to this image and what will happen next. Current computer vision algorithms still struggle at this task.
To try and challenge this problem, the authors provide four contributions as follows:
- They formalize the task at hand, naming it Visual Commonsense Reasoning
- They introduce a new dataset, VCR, tailored for this task
- They introduce Adversarial Matching, a way to transform natural language annotations into questions
- They provide a model for this task, called the Recognition to Cognition Network
Visual Commonsense Reasoning (VCR)
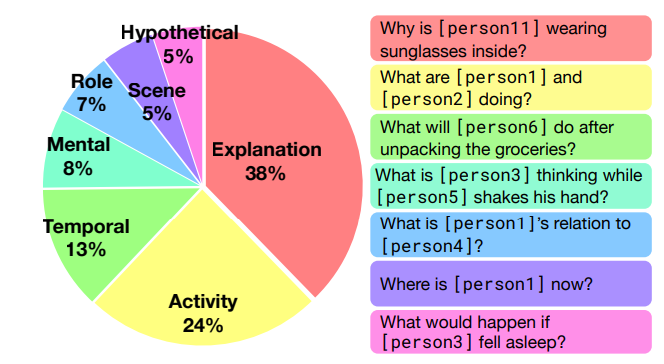
To properly understand the content of an image, its global context, a model must be able to answer questions based on the image’s meaning. Moreover, as a human can, it should be able to reason as to why it gave the answer. This ensures that the model chose the answer for the right reasons. Questions from the dataset are written in a mix of rich natural language as well as detection tags (such as [person2]) to help provide an unambiguous link between the textual description of an object and its location. Above and below are categories of questions and examples of questions/answers/reasoning triplets

Dataset
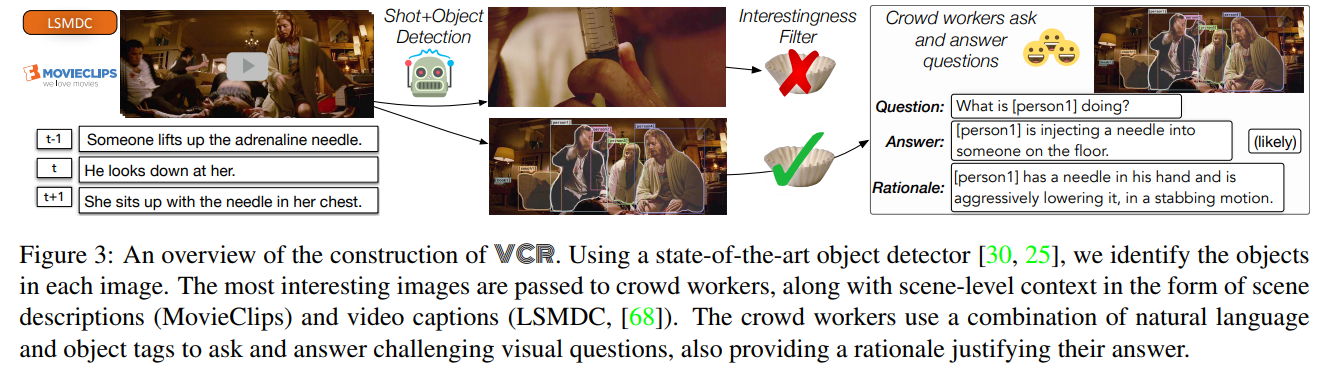
The dataset proposed consists of clips from the Youtube channel MovieClips 1 as well as the Large Scale Movie Description Challenge dataset2. Mask-RCNN was then used to detect objects and filter “uninteresting scenes”. That is, scenes where less than two persons and too few objects were present. They then used Amazon’s Mechanical Turk to write up to three question/answer/rationale triplets per selected frame.
Adversarial Matching
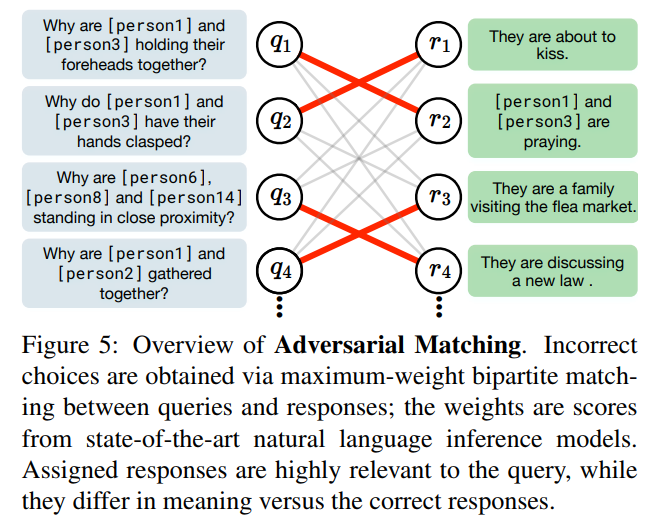
It was too demanding and error-prone to ask the workers to also write false responses and rationales to the provided questions. Instead, the authors propose Adversarial Matching, a way to turn natural language into multiple choice tests. The counterfactuals must be as relevant to the context while not being too similar to the correct answer. To do so, they used two models (BERT and ESIM+ELMo) and fed them questions \(q_i\) and responses \(r_i\) and evaluated their relevance \(P_{rel}\) and similarity \(P_{sim}\). They then performed maximum-weight bipartite matching on a weight matrix given by
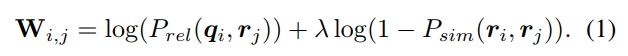
Recognition to Cognition Network
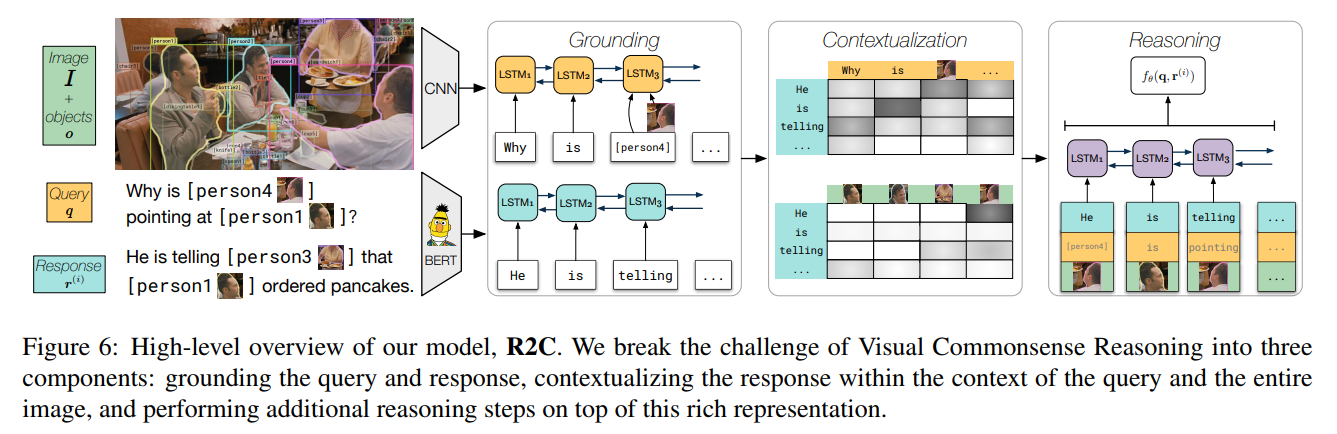
The model is split up into three parts: First, the grounding module learns a joint image-language representation for each token of the question and answers. Contextualization then contextualizes the sentences with each other and the image context. Reasoning then tries to associate which sentences fit together.
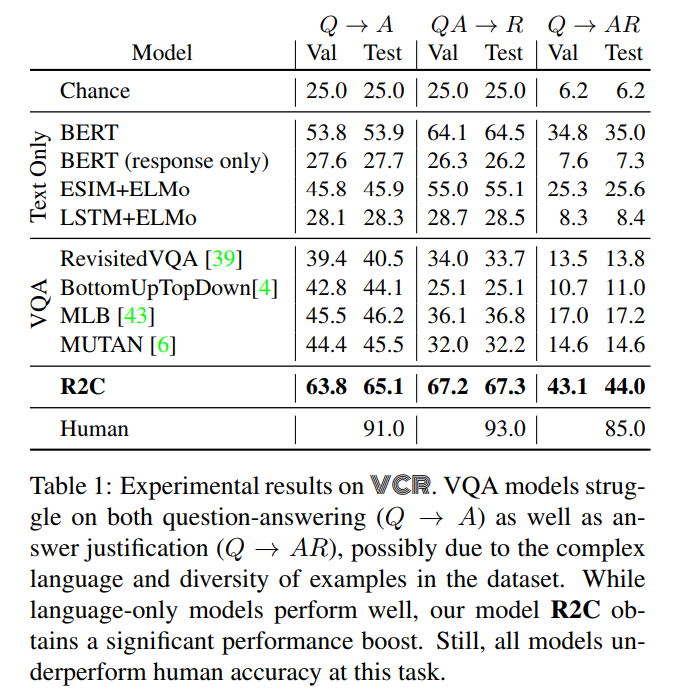

The dataset should be available soon at https://visualcommonsense.com/