Label Refinement Network for Coarse-to-Fine Semantic Segmentation
Idea
They propose a novel network architecture called the label refinement network that predicts segmentation labels in a coarse-to-fine fashion at several resolutions. The segmentation labels at a coarse resolution are used together with convolutional features to obtain finer resolution segmentation labels. They define loss functions at several stages in the network to provide supervisions at different stages.
Network
The convolution and subsampling operations motivate the LRN architecture, the feature map \(f(I)\) obtained at the end of the encoder network mainly contains high-level information about the image. Spatially precise information is lost in the encoder network, and therefore \(f(I)\) cannot be used directly to recover a full-sized semantic segmentation which requires pixel-precise information. \(f(I)\) can be used to produce a segmentation map \(s(I)\) of spatial dimensions \(h_0 \times w_0\) , which is smaller than the original image dimensions \(h \times w\). The costom decoder network progressively refines the segmentation map \(s(I)\). This model enforces the channel dimension of \(s_k (I)\) to be the same as the number of class labels, so \(s_k (I)\) can be considered as a (soft) label map.
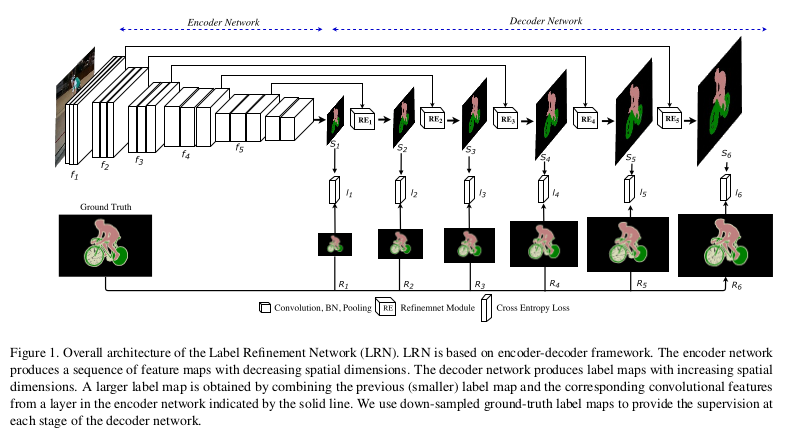
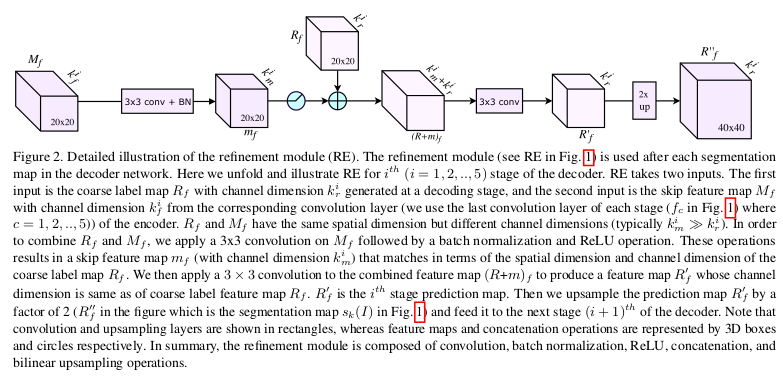
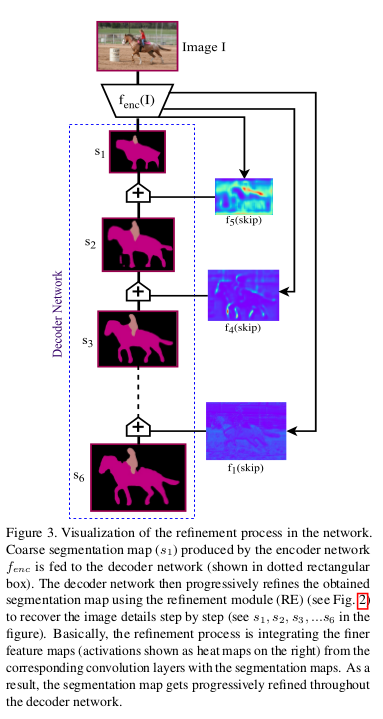
Results
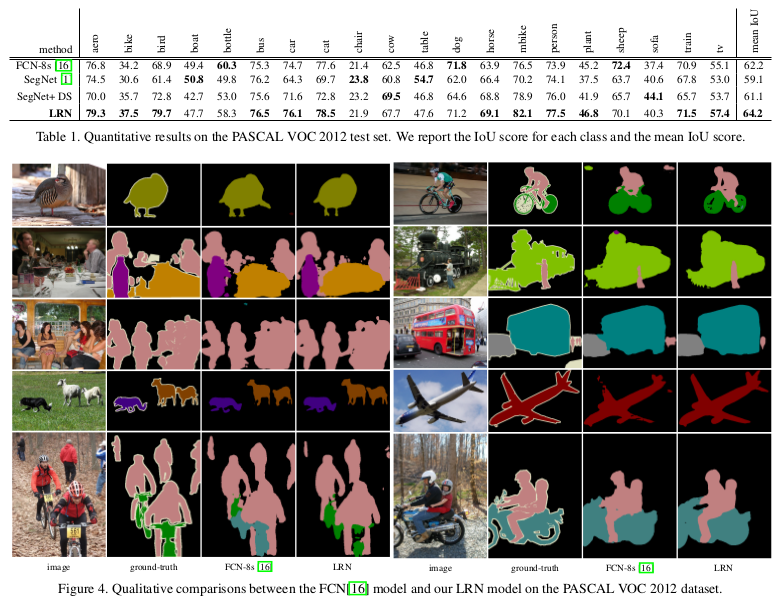
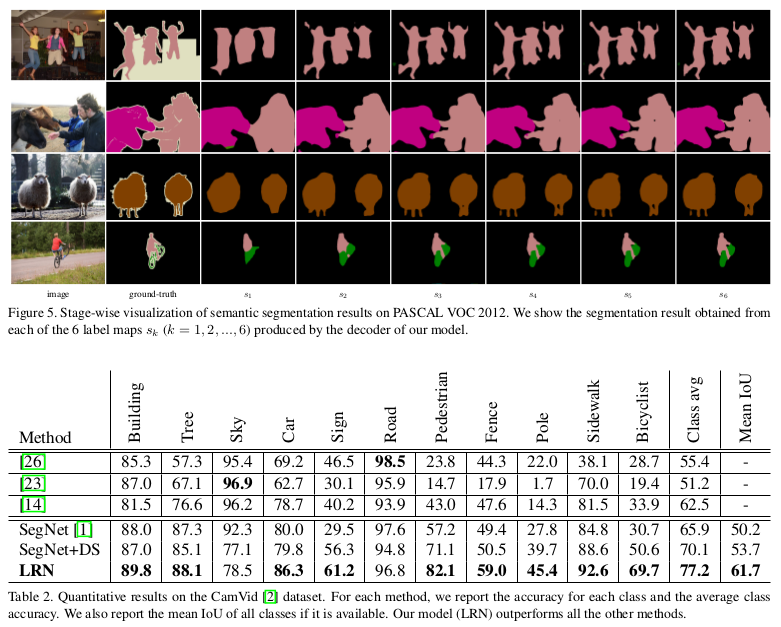
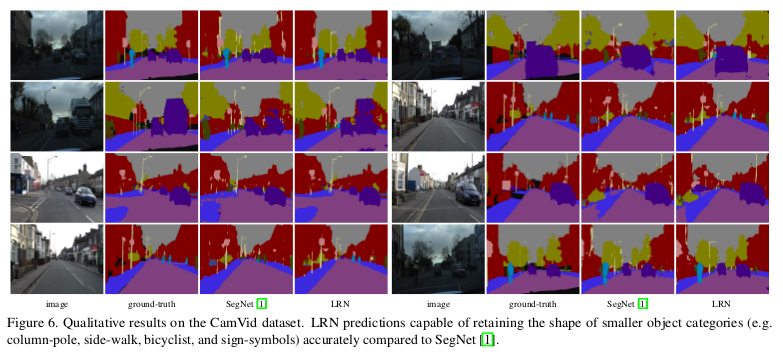
The model produces segmentation labels in a coarse-to-fine manner. The segmentation labels at coarse levels are used to refine the labeling produced at finer levels progressively.