Learning to reinforcement learn
The idea
Recent deep reinforcement learning methods are reaching human-level and superhuman-level performances in an ever-expanding list of tasks. However, most methods are still plagued with two massive disadvantages: They require an absurd amount of training data and specialize on one restricted task domain.
The authors propose a framework to overcome these factors which they call deep meta-reinforcement learning. The concept is to train a recurrent neural network (in this case an LSTM) as a reinforcement learning algorithm (in this case A2/3C), so that the LSTM eventually becomes its own reinforcement learning algorithm.
The method
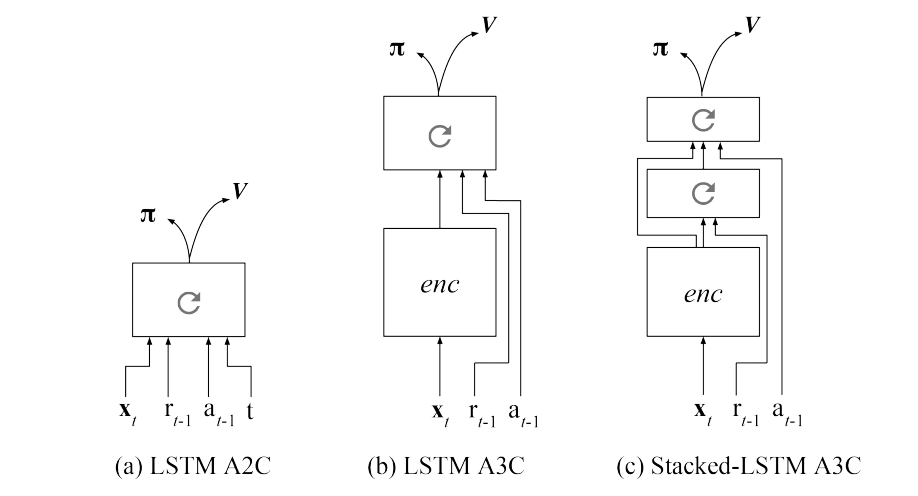
Using this architecture from Mirowski et al. (2016)1, they trained the agent on several tasks from the same family of tasks to prove their agent can learn a new task even if the weights are fixed, after a training period.
The results
They trained their agent in three different categories of tasks. The first one was variations of the multi-armed bandit problem. With a distribution \(D\) of Markov Decision process, the authors sample a task \(m\) at the beginning of an episode and the internal states of the agent are reset. The training process then goes on for a certain number of episodes, where a new task \(m\) is drawn from \(D\) at each new episode.
After training is completed, the agent’s policy is fixed and it is tested over new tasks drawn from \(D\) or slight modifications of \(D\) to test its generalization capabilities. The authors show that the agent is performing well on new MDPs even when its weights are fixed.
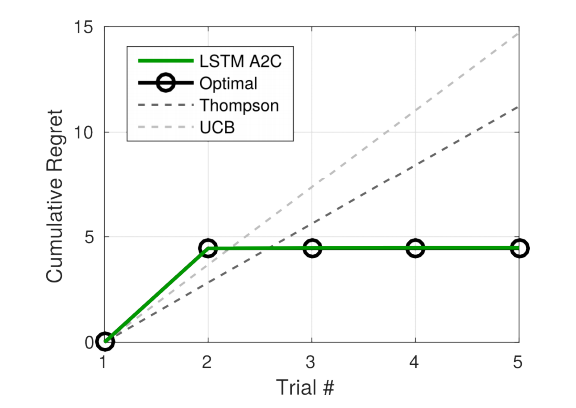
Most notably, they presented a problem where a bandit had one informative arm (with a fixed position) and multiple rewarding-arm including one optimal arm (with varying positions). The informative arm provided no reward but informed the agent as to where the optimal arm was. The above graph shows that the algorithm was able to prefer losing immediate reward for information which then provided optimal reward, as opposed to classic solvers which did not use this arm.
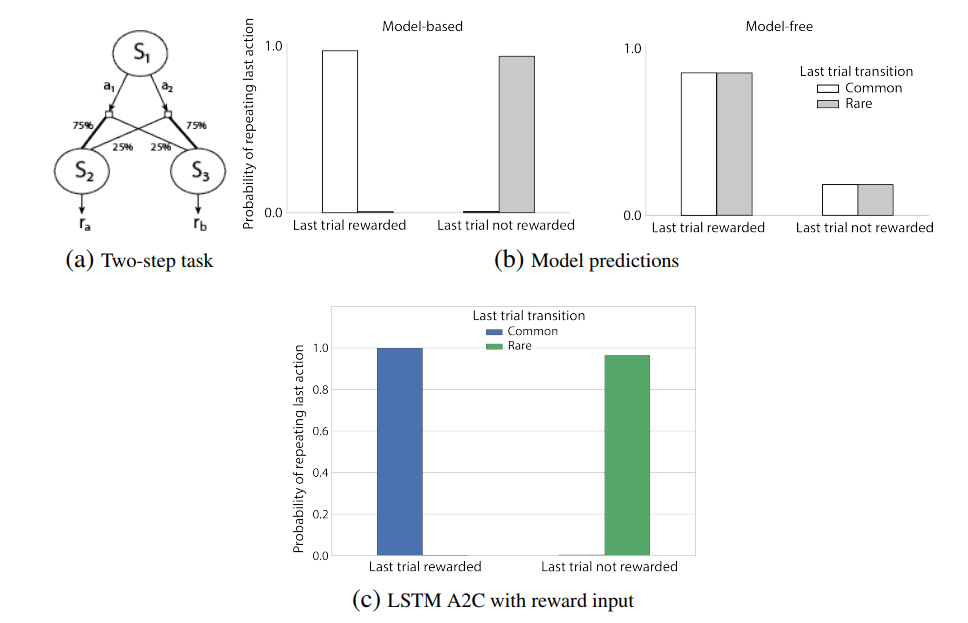
They also trained the agent to see if it would learn the underlying task structure where needed. To do so, they trained the agent on the MDP above. Without going into details into the experiment, the authors discovered that the agent has the same behavior as a model-based agent, while being model-free, which implies that the agent learned the underlying task structure.
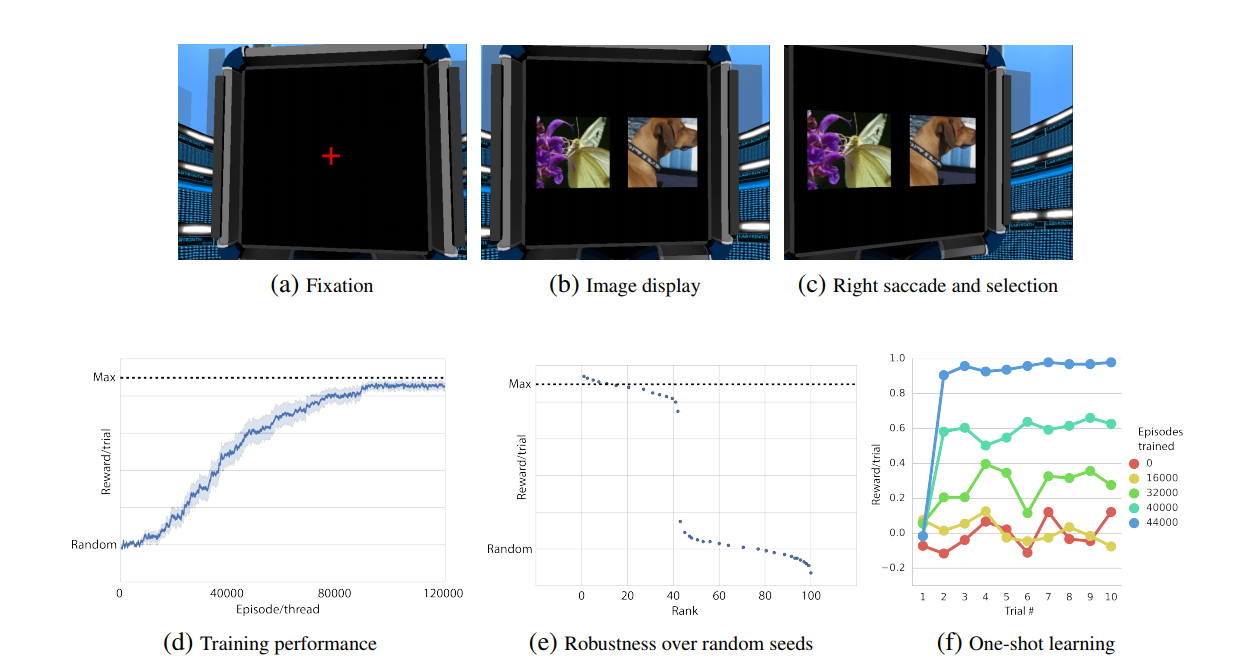
Finally, the authors then wanted to see if the agent was able to learn an abstract task representation and give rise to one-shot learning. To do so, they adapted an experiment from a study on animal behavior 2, where the agent had to do two consecutive steps: First, it has to fixate on the cross at the center of the screen for four times steps to receive a small reward. Then, the cross disappeared and the agent had to successively rotate (select an action left of right which rotated the agent over 4.4 degrees in the selected direction) until an image was “selected”. One of the two images was the “target” image, rewarding the agent, and the other was the “bad” image, costing the agent. After ten time steps of fixating over the image, the images disappeared, the red cross reappeared and the process repeated until the end of the episode.
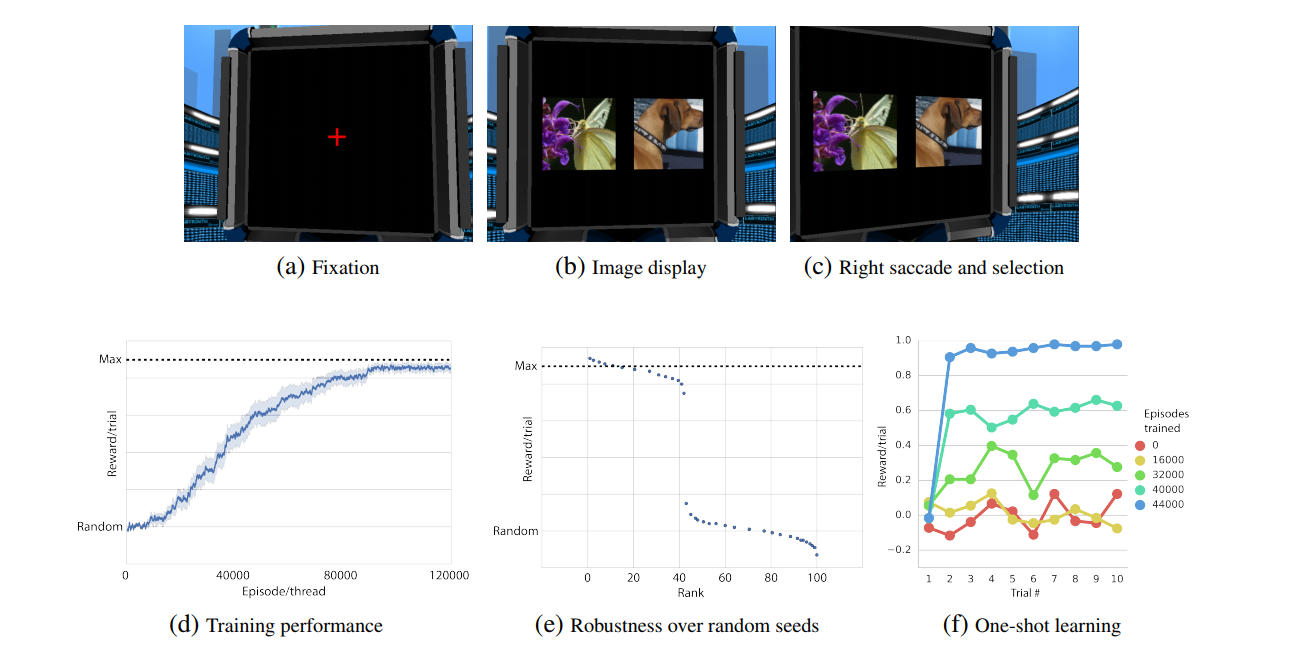
Each episode had its own sets of images, and after a couple of episodes, the agent always selected the “target” image after the first try, which indicates that the agent is able to “one-shot-learn” the target image.
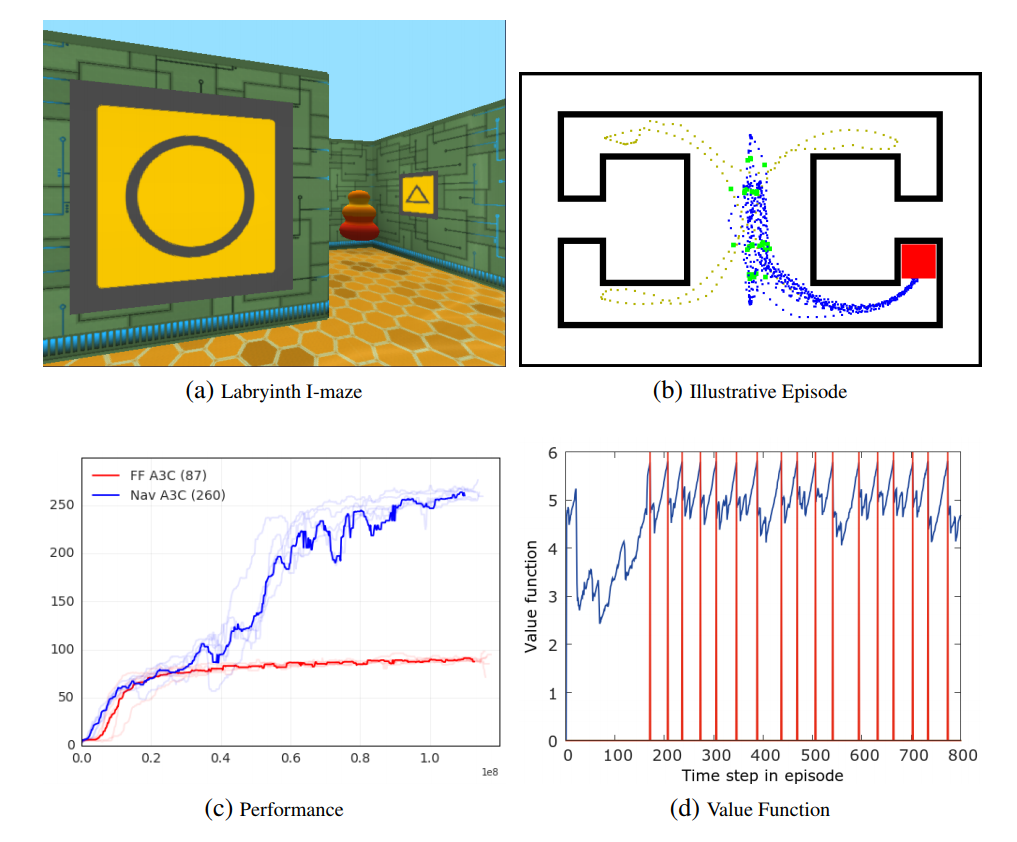 The authors also reported an experiment from 1 where, after some training, is able to return to the goal confidently within an episode even with a random starting point. This means that the agent is able to “one-shot-learn” the position of the goal and is generally able to learn how to navigate in a maze, independently of its structure.
The authors also reported an experiment from 1 where, after some training, is able to return to the goal confidently within an episode even with a random starting point. This means that the agent is able to “one-shot-learn” the position of the goal and is generally able to learn how to navigate in a maze, independently of its structure.
Criticism
However, the authors did not try to compare their agent to “classic” feed-forward deep reinforcement-learning agents (except for the reported maze experiment), so we cannot know if the behaviors shown by the LSTM agent are unique to it or general to all deep RL agents, although I would be surprised if they are.
Implementation: https://github.com/awjuliani/Meta-RL