Low-Shot Learning from Imaginary Data
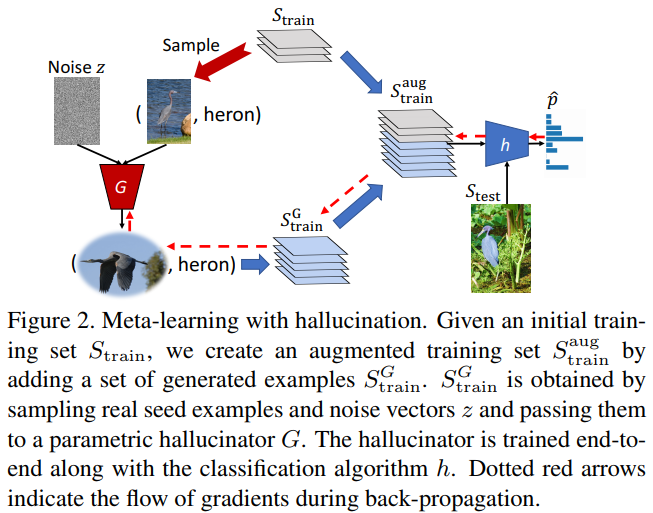
This paper adapts GANs for low-shot learning. As we see in fig. 2, from the few samples they have, they use a pretrained generator to augment the dataset and they use standard methods on the augmented dataset (siamese networks, etc). They do not show any generated samples. They also use a modified version of softmax with a prior probability which boosts probabilities of the “novel” classes. Those classes are only seen at test time and the network was not trained on those.
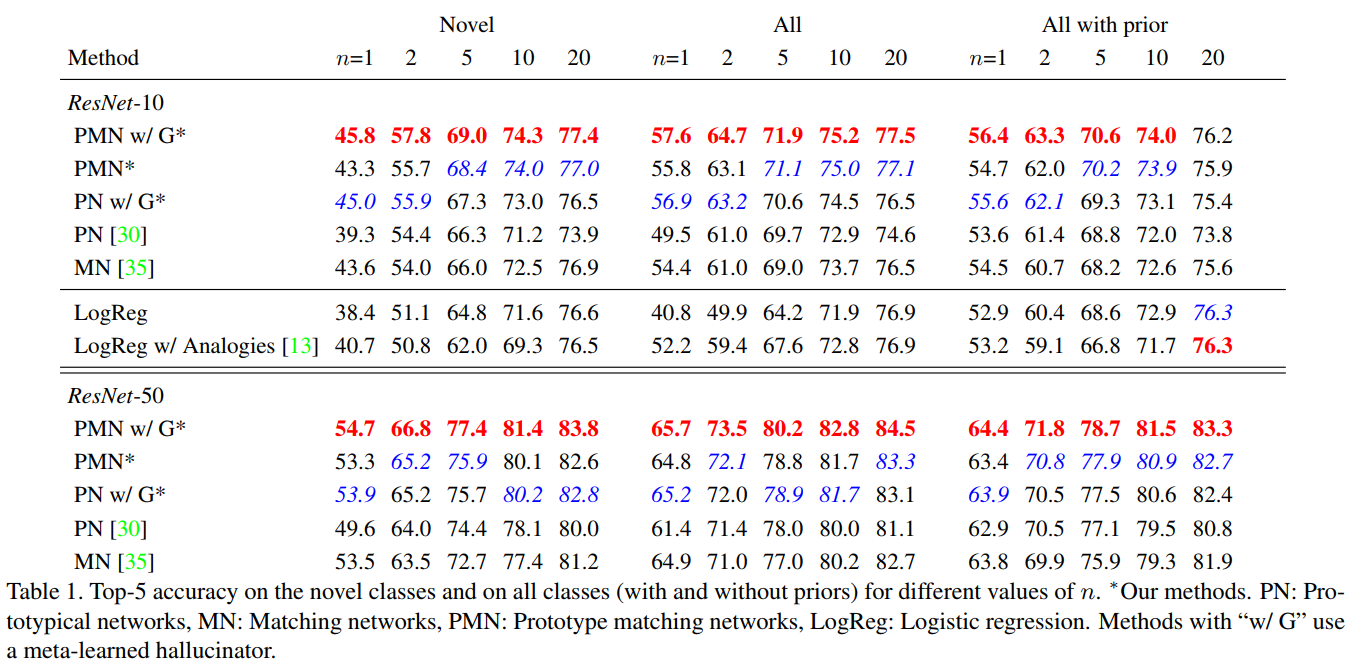
In Table 1, we see that the top-5 accuracy is highly impacted by the new training scheme when \(n\) is low.
Finally, they do show that the generated samples are closer to the real distribution than using prototypes.
