Incremental Learning for Semantic Segmentation of Large-Scale Remote Sensing Data
Code: https://project.inria.fr/epitome/inc_learn/
Method
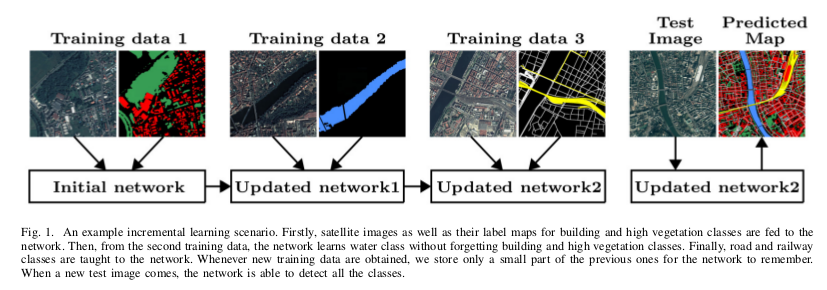
Authors propose a method to avoid catastrophic forgetting, a significant performance drop for the already learned classes when new classes are added on the data, having no annotations for the old classes. They propose an incremental learning methodology, enabling to learn segmenting new classes without hindering dense labeling abilities for the previous classes, even if the entire previous data are not accessible.
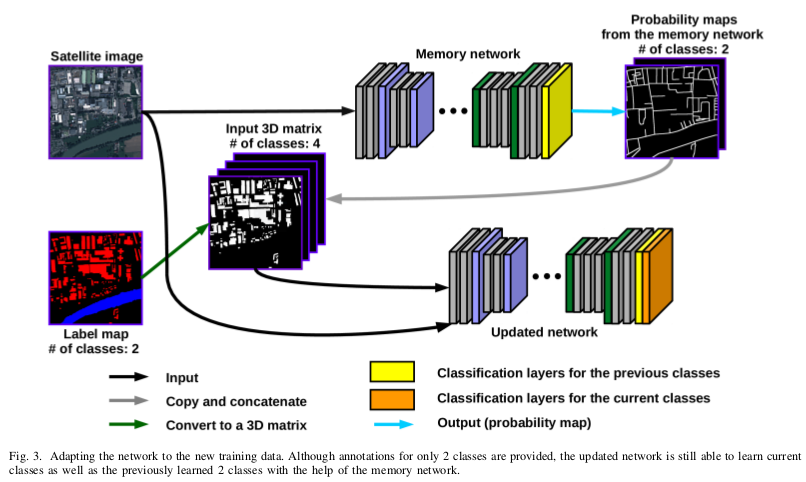
The proposed approach adapts the network to learn new as well as old classes on the new training data, and allows it to remember the previously learned information for the old classes.
For adaptation, they keep a frozen copy of the previously trained network, which is used as a memory for the updated network in absence of annotations for the former classes. The updated network minimizes a loss function, which balances the discrepancy between outputs for the previous classes from the memory and updated networks, and the mis-classification rate between outputs for the new classes from the updated network and the new ground-truth.
Loss
For a total of three losses:
- \(L_{class}\) (sigmoid cross entropy loss)
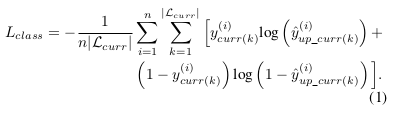
- \(L_{distill}\), measures the disparity between \(y_{mem}\) samples from the memory network, and \(y_{up_prev}\) from the updated network.
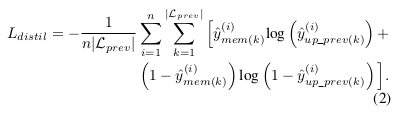
- \(L_{adapt}\) is the loss used during the adaptation
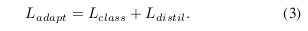
- \(L_{rem}\) is the costOm loss for the incremental learning
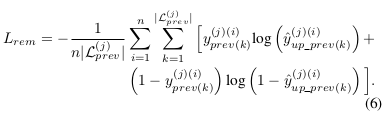
Network
This network is a variant of U-net.
-
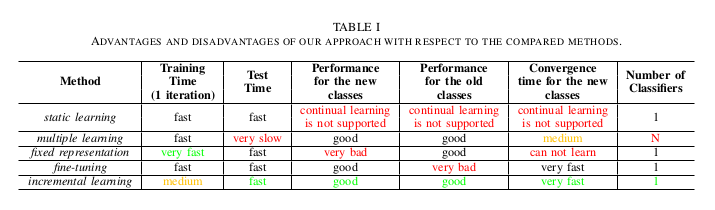
Static learning: This is the traditional learning approach which assumes that 100% of the training images and annotations for the same classes are available at the time of training.
-
Multiple learning: This learning strategy trains an additional classifier whenever the new training data is made available. The number of classifiers that need to be stored increases linearly.
-
Fixed representation: To learn new classes, they remove the classification layers, which were optimized for the previous classes and plug in new classification layers dedicated for the new classes. The newly added classification layers are initialized with Xavier method1. When new training data is made available, only the newly added classification layers are optimized, the rest of the network being frozen.
-
Fine-tuning: They use a similar strategy to fixed representation. The only difference is that while training the network, instead of only the classification layers, they optimize the whole network using only the new training data.
-
Incremental learning: This strategy requires for the memory network to generate probability maps from the training patches to optimize \(L_distil\).
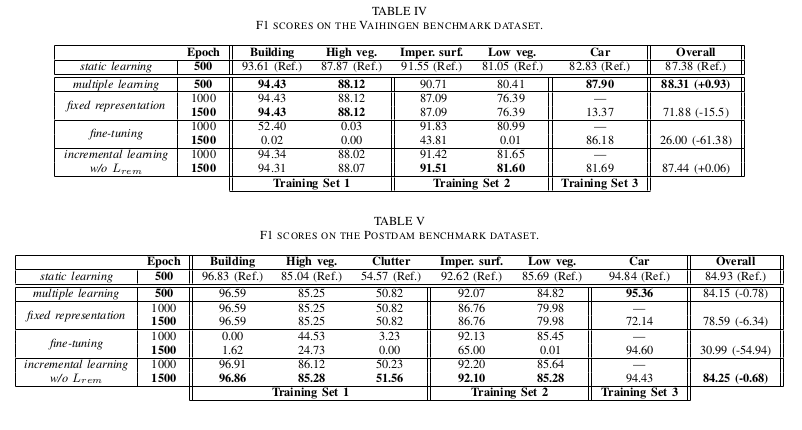
Results
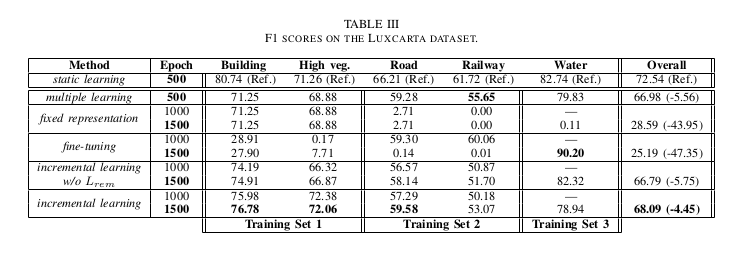
The results are competitive with the state-of-the-art single-dataset methods, while allowing the network to learn new classes.

-
X. Glorot and Y. Bengio, “Understanding the difficulty of training deep feedforward neural networks,” in Proceedings of the thirteenth international conference on artificial intelligence and statistics, 2010, pp. 249–256. ↩