Privacy-preserving generative deep neural networks support clinical data sharing
Code: https://github.com/greenlab/SPRINT_gan
Summary
Problem: Privacy concerns limit data sharing in the medical community, especially given the required data-sharing procedures and agreements.
Goal: Once a study is complete, train a generative model to generate synthetic data as close as possible to real participants, then release the synthetic dataset instead of the real data.
However:
Numerous linkage and membership inference attacks have demonstrated the ability to re-identify participants or reveal participation in a study on both biomedical datasets and from machine learning models.
For example, given a model and a real subject’s data, it might be possible to determine if this subject was part of the model’s training set.
Solution: Include a differential privacy constraint during training.
Differential privacy : Define strong guarantees on the likelihood that a subject could be identified as a member of the trial. Informally, differential privacy requires that no subject in the study has a significant influence on the information released by the algorithm.
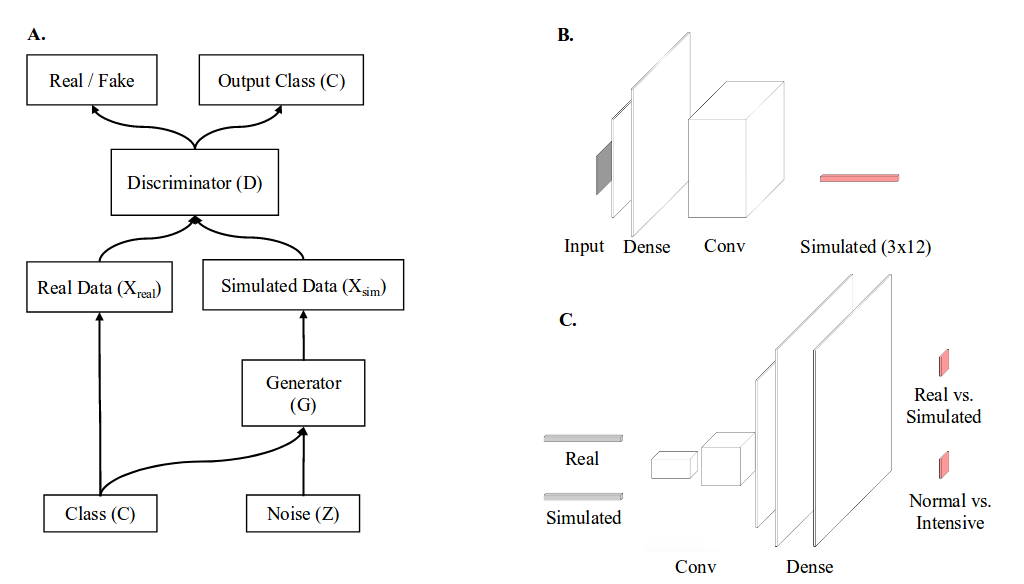
In GANs, the discriminator is the only component that can access real, private data, and needs to be modified.
Applying differential privacy: limit the effect any single subject can have on the training process by adding random noise based on the maximum effect of a single subject. In practice: clip the norm of the gradient and add proportional gaussian noise.
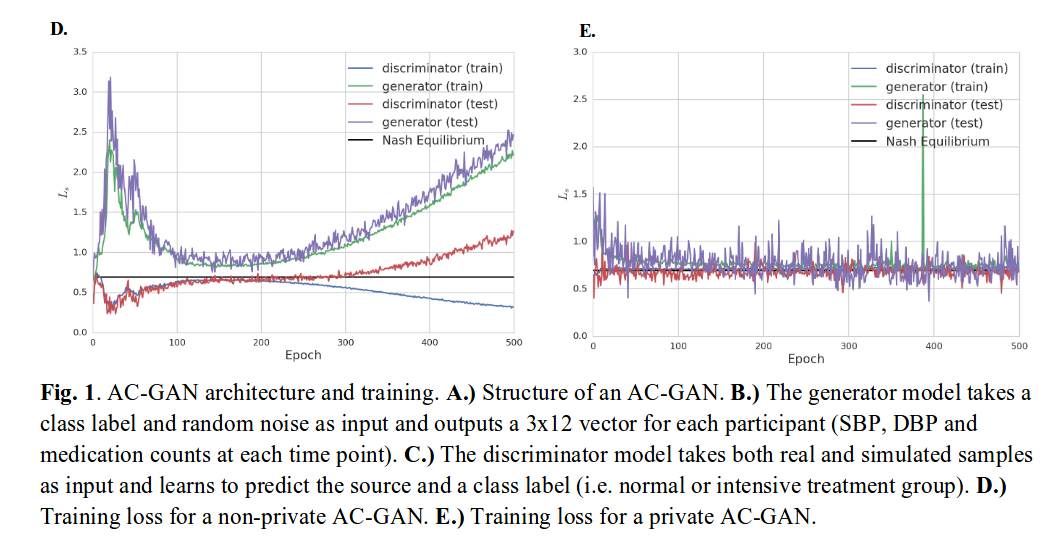
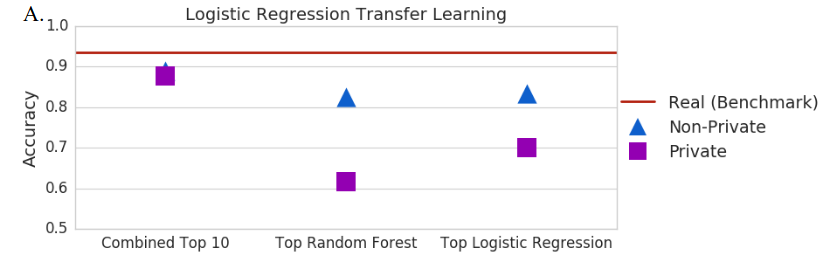
To stop training, they need to use a traditional classifier and test the generator at each epoch. Then they select the top 5 epochs and combine generated samples from each.
Experiments
Dataset:
SPRINT (Systolic Blood Pressure Trial) Data Analysis Challenge from New England Journal of Medicine.
-
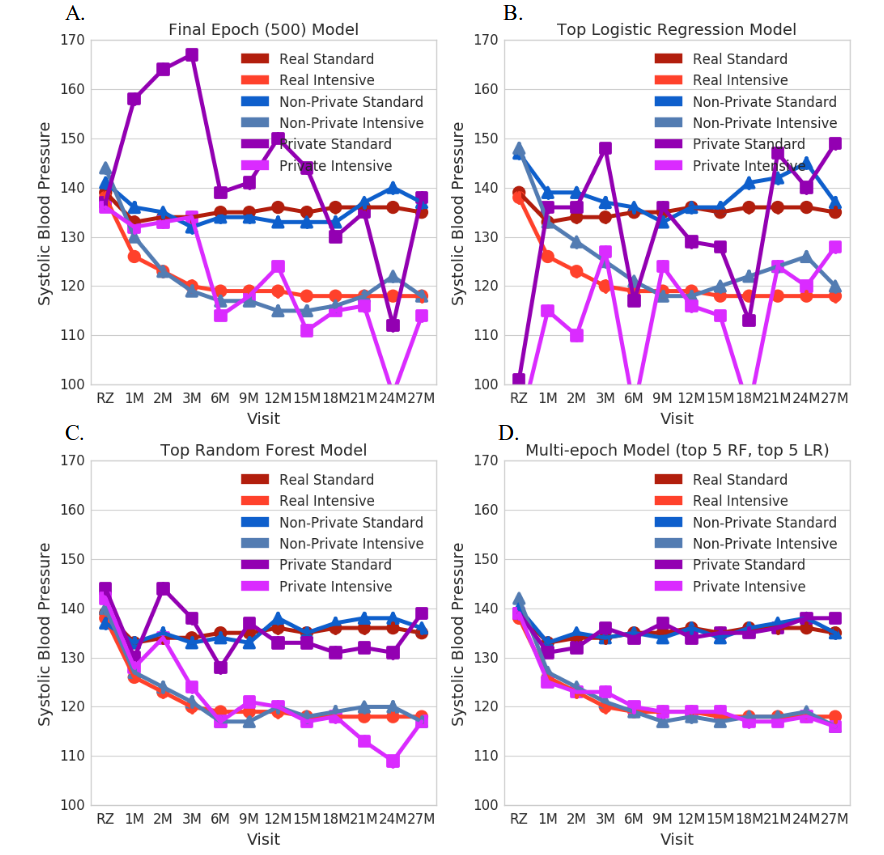
Intensive management (<120mmHg) vs Standard management (<140mmHg)
-
Data: Blood pressure at 12 time points
-
6000 train subjects; 502 test subjects
Models:
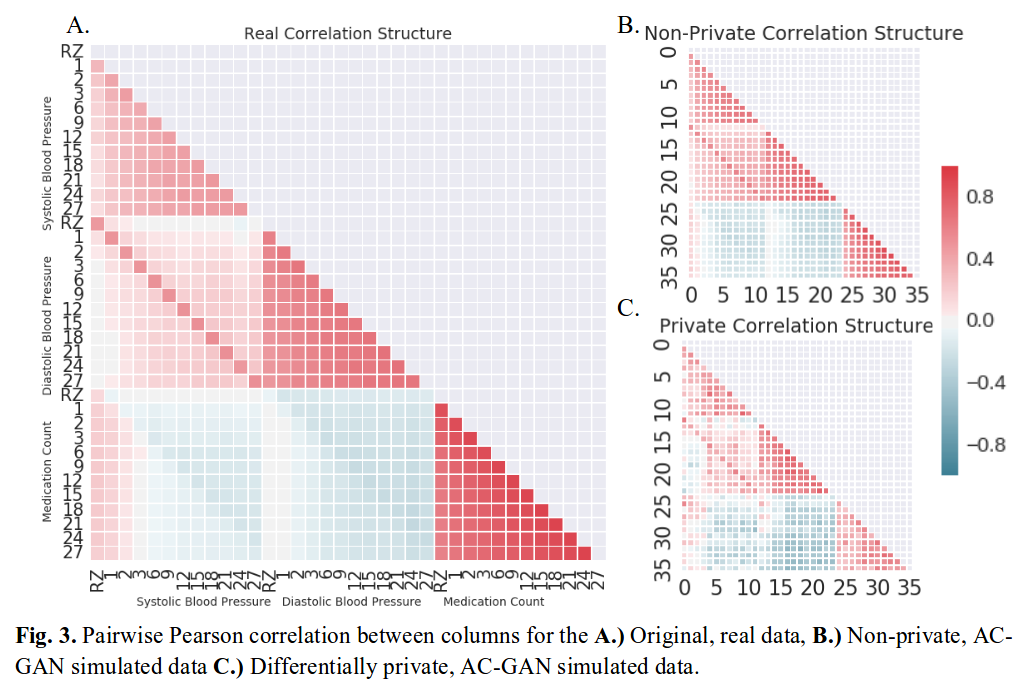
- AC-GAN (Auxiliary classifier) – Standard training : “non-private” model – Using differential privacy : “private” model
Evaluation: Train on synthetic data, then score on a real test set.