SeedNet: Automatic Seed Generation with Deep Reinforcement Learning for Robust Interactive Segmentation
Highlights
The goal of the paper is to propose a method to reduce human effort while maintaining the performance in interactive/weakly supervised segmentation tasks. The goal is to create additional seed points and obtain accurate segmentation results.
An automatic seed generation technique with deep reinforcement learning to solve the interactive segmentation problem is proposed.
The contributions of the paper include:
- The introduction of a Markov Decision Process (MDP) formulation for the interactive segmentation task where an agent puts seeds on the image to improve segmentation.
- A novel reward function design to train the agent for automatic seed generation with deep reinforcement learning.
Summary
Provided that a point on the desired object and a point in the background are given by the user, a sequence of artificial additional points are automatically generated for precisely segmenting the desired object.
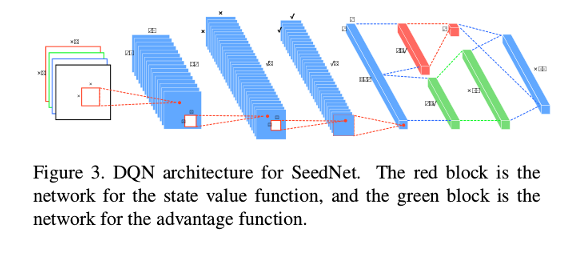
The problem is formulated as Markov Decision Process (MDP) and optimized by reinforcement learning with Deep Q-Network (DQN).
Introduction
Segmenting the object of interest in an image is one of the fundamental problems in computer vision. However, without knowing the user’s intention, automatic object selection has inherent limitations because where and what objects should be extracted differs by users.
The automatic seed generation problem is treated as a sequential decision-making problem and train the seed generation agent with deep reinforcement learning.
The advantage of the proposed system is that consistent performance has been achieved in images in unobserved datasets as well as in previously observed datasets.
Methods
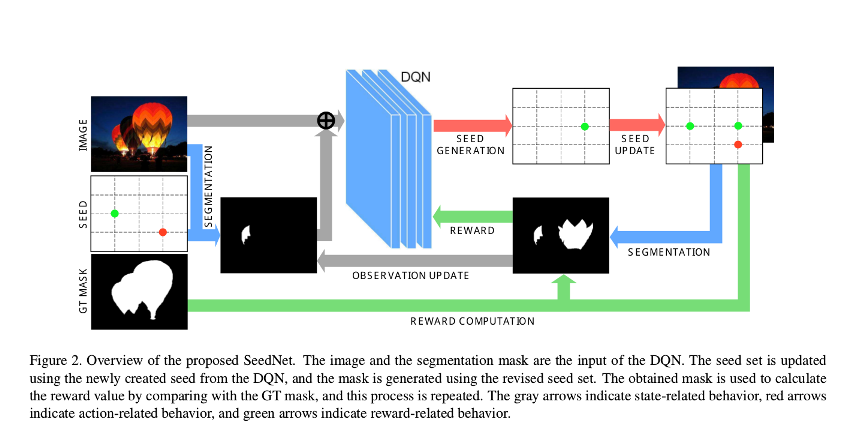
The agent starts by analyzing the image and the foreground/background segmentation produced with the initial seeds by the user, and then determines a new foreground or background seed. After creating a new segmentation by combining the created seed with the initial seeds, the agent uses this segmentation as a next input and repeats the process of creating seeds.
- State/observation: current binary segmentation for the next iteration.
- Action: positioning new seed point. The agent decides the label (foreground/background) and position of the seed in the 2D grid given the states. The action grid is low resolution.
- Reward: variation with the intersection-over-union (IoU) score between the segmentation and ground truth based on regions.
The process is terminated after an arbitrary number of seeds have been generated.
The method uses a Random Walk (RW) model to perform the segmentation operation with the generated seeds.
The reward part is omitted during test time, and only the seed generation process is performed.
Results
Results on the variability with respect to the segmentation method are included.
Training is performed on MSRA10K, results for unobserved datasets (GSCSEQ, Weizmann Single Object, Weizmann Horse, iCoseg, IG02) are included.

Discussion
Comparison to other approaches:
- Multiple instance learning (MIL): SeedNet requires no bounding box.
- Seeded region growing: SeedNet proposes new points rather than expanding the seed area. Thus, chances for including other areas that are harder to reach for a growing method are increased.
It can be considered as an alternative to the use of attention models and reinforcement learning.
Only the binary mask information is added to the state to achieve robustness in the segmentation with respect to the seeds.
Conclusions
There are algorithms that allow to automatically select a point in the foreground and the background, so adding such a method as a prior step would ideally render the method fully automatic (if the seeds are acceptable).