Visual semantic navigation using scene priors
The idea
The authors propose that using semantic priors (in the form of a graph) greatly increases the performance of an agent trying to navigate in a scene to find an object. This method generalizes well to unseen objects (but with known semantics) and unseen scenes.
The method
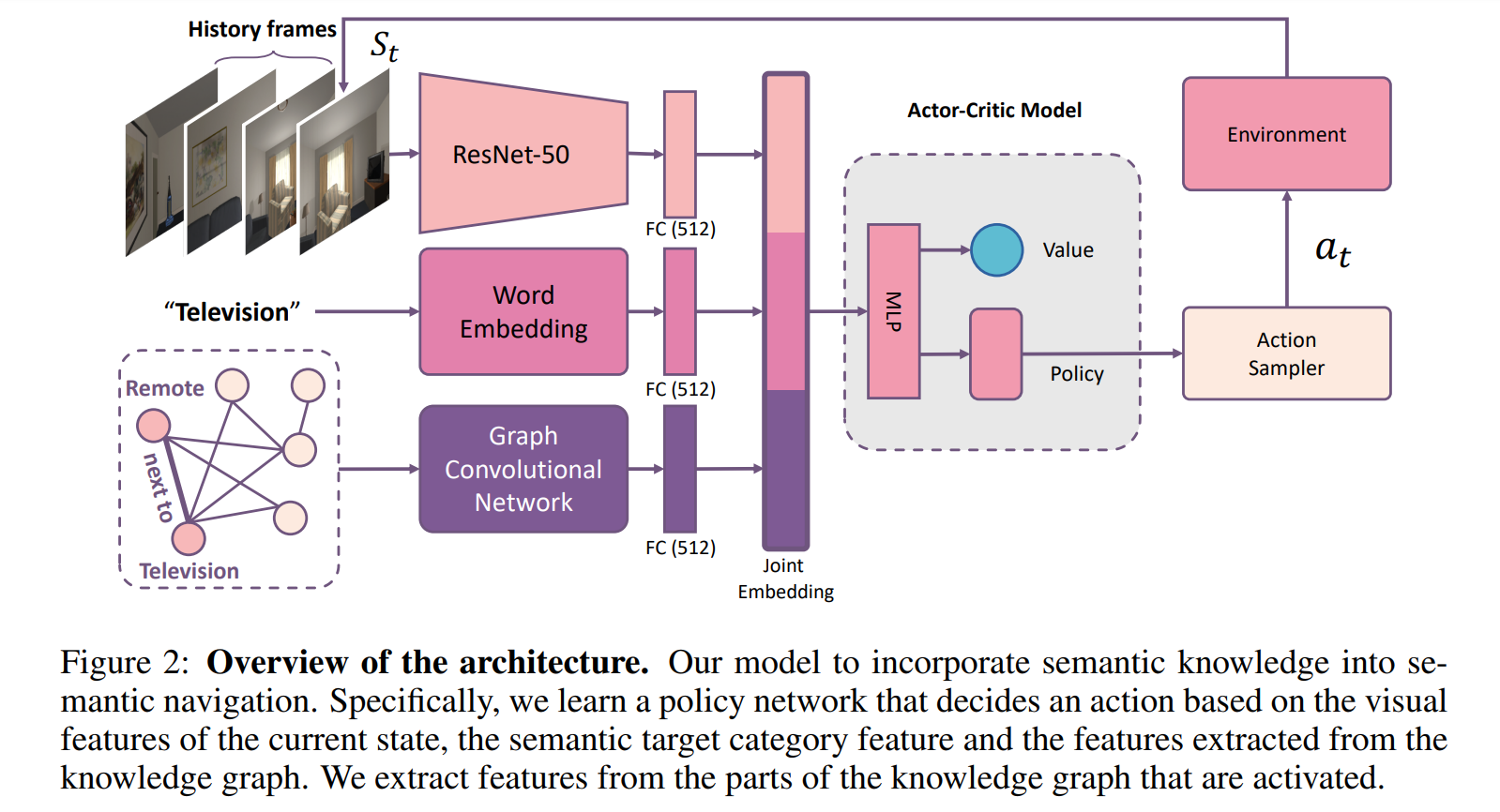
The goal is to navigate to a specified target object category using only RGB input. The task is considered successful if an instance of the target object category is visible and within a threshold of distance.
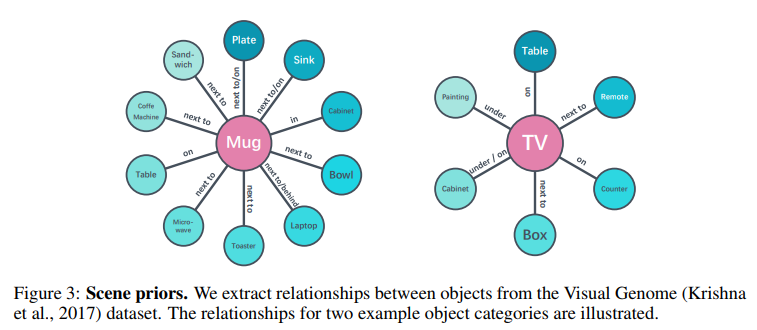
For visual analysis, the model uses a ResNet-50 pre-trained on ImageNet. The current frame as well as the last three frames are input to the ResNet-50 to provide some sense of time-steps. Word embedding is done using fastText 1 and scene priors are extracted via a Graph Convolutional Network 2.
A3C is used output an action at each time step, where only one MLP outputting both the value and the policy has been implemented. The environment is provided by the AI2-THOR framework which provides “near photo-realistic” customizable environments3
The results
SPL is Success weighted by Path Length, which provides a more accurate representation of performance than plain Success Rate.
First results show performance in case the agent has to provide the “stop” action, telling the environment that he has found the object’s category. Second results show performance in case the environment tells the agent that he has found the object’s category. The authors also mention that using the Graph Convolutional Network only adds 0.12 GFLOPs compared to A3C.
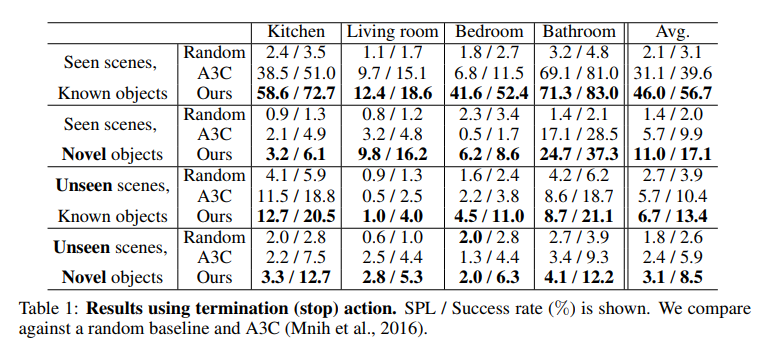
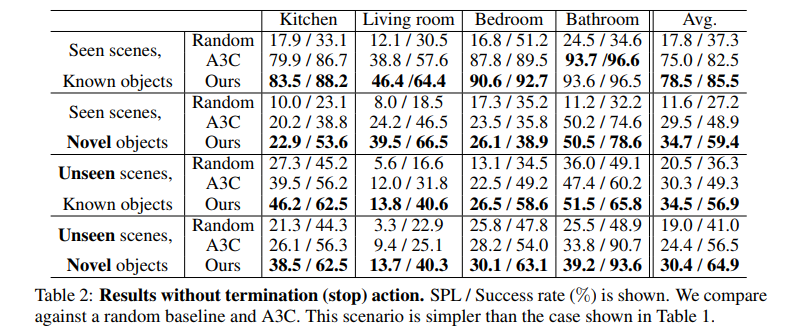
Finally, here’s a video of it in action: https://www.youtube.com/watch?v=otKjuO805dE