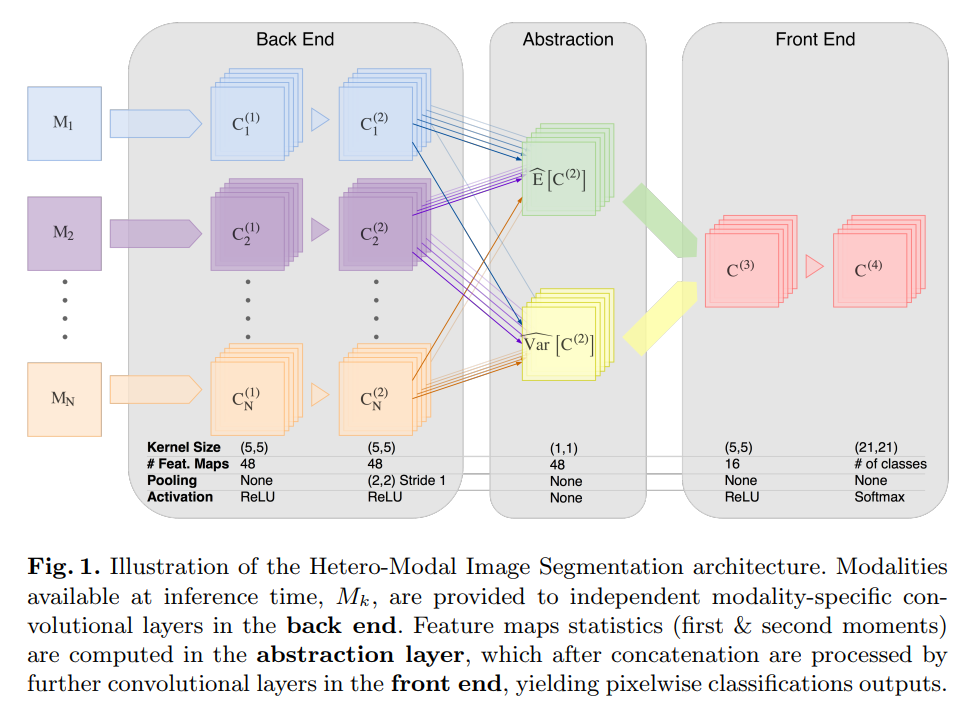
HeMIS: Hetero-Modal Image Segmentation
Summary
Problem: How to do image segmentation when multiple modalities might be available or missing?
Solution: Learn an embedding that maps each modality into a latent vector space, then use statistics in this space as input for a segmentation model.
NOTE: To keep the original resolution, there is no downsampling (they use zero-padding and a stride of 1).
Training
During training, input modalities are dropped randomly using curriculum learning (start with all modalities, then gradually increase the “dropping” probability).
The model is trained end-to-end.
Experiments
Datasets:
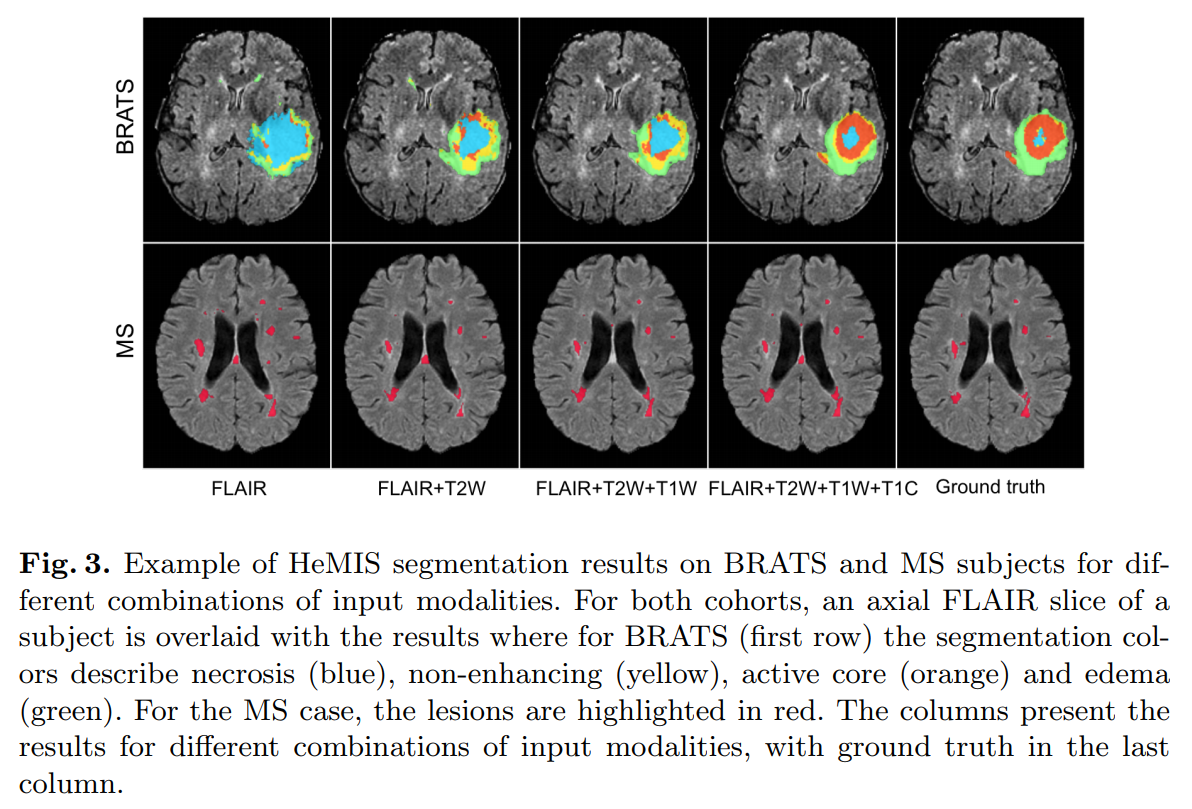
- BRATS 2013/2015 (Brain tumors)
- MSGC/RRMS (Multiple sclerosis)