CBAM: Convolutional Block Attention Module
This paper builds upon Squeeze-and-Excite (S&E) by adding spatial attention in addition to channel attention.
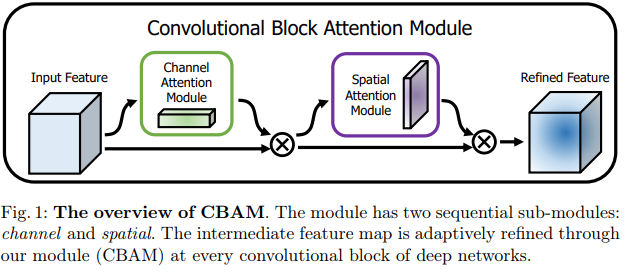
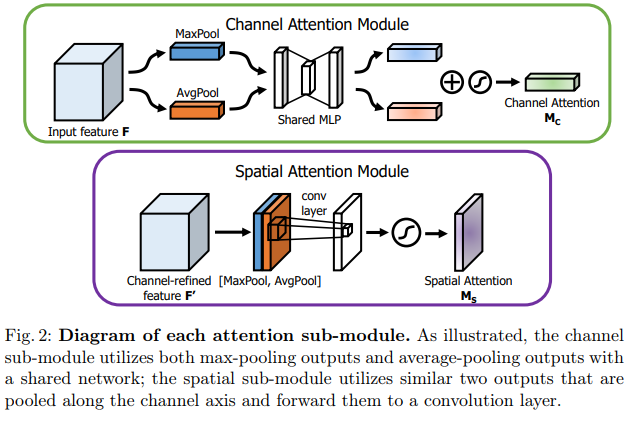
They modified the S&E Module by adding an Avg pooling before applying the MLP to generate the channel attention map.
The Spatial Attention Module is pretty similar, they first concatenate the output of a Max and Avg pooling layers. They then combine them using a Conv layer to produce the attention map.
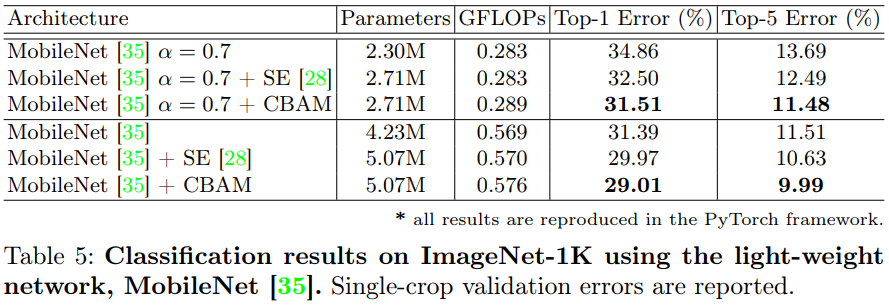
They tested their method on ImageNet, COCO (+2% mAP) and Pascal VOC 2007 (+2% mAP).
Their method is quite powerful as their attention maps better segment the object in the images than previous works.
